Java and Maven Installation Steps (Ubuntu)
- java 17 is needed for spring framework 6 / spring boot 3
- download deb file from here
- run
sudo apt install ./jdk-17_linux-x64_bin.deb - download binary tar.gz file from here
- run
tar xzvf apache-maven-3.9.3-bin.tar.gz - add the following to ~/.bashrc -
export JAVA_HOME="/usr/lib/jvm/jdk-17" export PATH="$PATH:$JAVA_HOME/bin/" export M2_HOME="~/apache-maven-3.9.3" export MAVEN_OPTS="-Xms256m -Xmx512m" export PATH="$PATH:$M2_HOME/bin/" - note - when creating projects using start.spring.io, it comes bundled with the maven wrapper
Rest
- evolution of http - http1 ➙ http1.1 ➙ http2 ➙ http3
- tls is the newer standard and ssl is old (e.g. http3 only supports / uses tls)
- safe methods - only fetch information and do not cause changes. e.g. - GET, HEAD (like GET but requests for metadata), OPTIONS (supported http methods by the url), TRACE (echoes the request, helps understand if the request was altered by intermediate servers)
- idempotent methods - safe methods, PUT, DELETE (POST is not idempotent)
- status codes - 100 series for informational purpose, 200 series for success, 300 series for redirects, 400 series for client side errors and 500 series for server side errors
- rest - representational state transfer. it is stateless
- richardson maturity model - maturity of restful resources. this was probably needed because unlike soap, rest doesn’t really have as many standards
- level 0 - swamp of pox - e.g. soap. pox here stands for plain old xml. typically uses just one url and one kind of method
- level 1 - resources - use multiple uris for identifying specific resources. e.g. /products/123
- level 2 - use http verbs in conjunction with level 1. e.g. POST for creating a product
- level 3 - hateoas - hypermedia as the engine of application state. server returns links in the response to indicate what other actions are available. this helps with the idea of self discovery / self documenting of apis
- marshalling (pojo to json) / unmarshalling (json to pojo) is done with the help of jackson
- so far, finding this pdf good for reference
- spring was introduced by rod johnson as a simpler alternative to j2ee, thus replacing xml with pojos
- spring boot is a wrapper around spring, which can do things like auto-configuration e.g. autoconfigure h2 if it is on the classpath, starter dependencies and so on
- convention over configuration - there are reasonable defaults, which we can override as needed
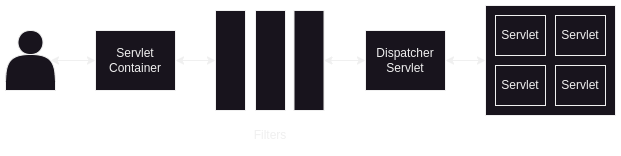
- spring boot has an embedded tomcat server, which can route requests to the application. earlier, the idea used to be to build war applications (we build jar applications now) and manually deploy them to tomcat servers. tomcat is also called the “servlet container”
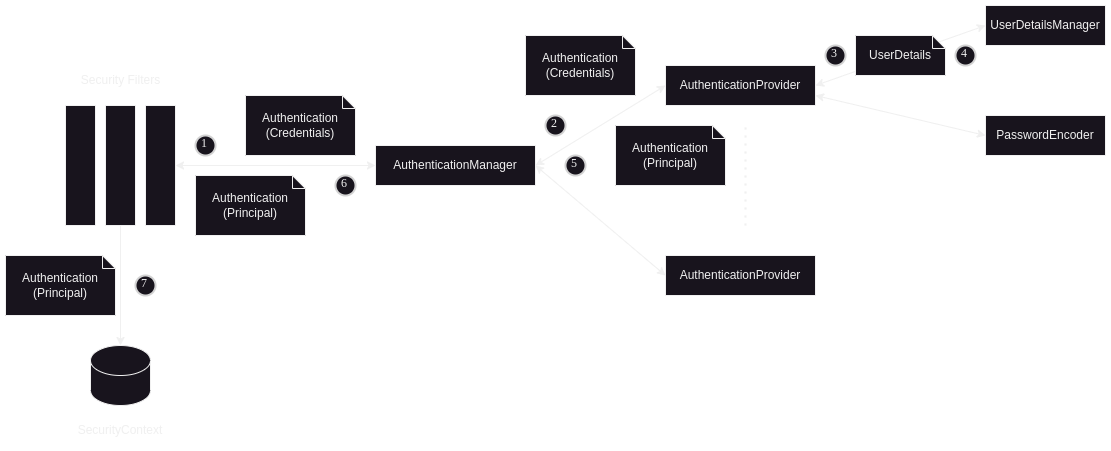
- mvc - model view controller. a
DispatcherServletrunning underneath directs requests to / handles responses from the controller - the controller calls a service, which has the business logic (interacting with db) and returns a model (pojo)
- servlet api is abstracted away from us, but that is what gets used underneath i.e. our requests are sent to servlets that can then forward these requests to our business logic
- the “servlet container” i.e. tomcat is responsible for converting http requests / response to corresponding servlet request / servlet response
- we can optionally add filters - these can perform pre / post processing on our servlet requests / servlet responses - e.g. spring security filters
- so entire flow according to my understanding -
![webmvc architecture]()
@Servicefor service,@Controllerfor controllers- extend the
CommandLineRunnerinterface for initial bootstrapping - by default in spring boot, package scan happens for any components that are in the same package or inside of any nested packages
- spring context creates components (i.e. instances) via this package scan and holds on to it
@SpringBootApplication public class Spring6WebappApplication { public static void main(String[] args) { ApplicationContext ctx = SpringApplication.run(Spring6WebappApplication.class, args); BookController bookController = ctx.getBean(BookController.class); } } - we can also autowire the
ApplicationContextas well - dependency injection - needed dependency is automatically injected for us. this can be achieved via (3 ways) -
- constructor (instantiation)
- setters
- using field injection i.e.
@Autowired
- favoured method is using constructor injection with properties marked
private final. this means the class cannot be instantiated (aka application fails) if the dependency is not available, instead of the dependency causing null pointer exceptions later - dependency injection works with concrete classes / interfaces (think interface segregation in the i of solid principles)
- inversion of control (2 points) -
- it is the underlying framework that does the heavy lifting for us so that we can focus on the business logic. heavy lifting includes things like instantiation of objects
- allows dependencies to be injected at runtime. the dependencies are not predetermined
- primary beans - if we have two different concrete classes implementing an interface, and we try to use dependency injection for this interface, we get the error expected single matching bean but found 2. using
@Primary, we can ask spring to prefer one of the implementations over another - we can use
@Qualifierto specify the bean name explicitly as well. useful when for e.g. we have multiple implementations as described above - we can also “name” the parameters we want to use dependency injection for correctly. e.g. we have two concrete classes
EnglishGreetingServiceandSpanishGreetingService. we can use the former using the correct name for the constructor argpublic Il8NController(GreetingService englishGreetingService) { this.greetingService = englishGreetingService; } - by default, unless we name the bean, the name used for e.g. for
HelloServicewould behelloService. we can name beans explicitly as well, e.g.@Service("bonjourService") - profiles - we can annotate a bean with
@Profile@Service @Profile("EN") public EnglishHelloService implements GreetingService { } - this means that the bean would only be instantiated when that particular profile is active. e.g. -
@SpringBootTest @ActiveProfiles("EN") class IL8NControllerTest { } - a bean can be available in multiple profiles -
@Profile({ "EN", "English" }) - we can also add a bean to be available by default -
@Profile({"EN", "default"}). this means that if no bean is available, add this bean to the application context. e.g. in this case, use theEnglishHelloServiceimplementation when any other bean for theGreetingServiceis not available - so, we have discussed different techniques to resolve conflicts / to achieve inversion of control -
@Primary,@Service,@Qualifier, naming the fields “correctly”,@Profile(named and default), etc - bean lifecycle methods - we can hook into the various lifecycle stages that a bean goes through, e.g. when the bean properties are set, when its instantiation is over and so on. we can either implement interfaces like
InitializingBean,DisposableBeanor annotations like@PreDestroyand@PostConstruct - bean scopes - we can set scope via for e.g.
@Scope(BeanDefinition.SCOPE_PROTOTYPE). the different options are -- singleton - it is the default scope of beans, one object per application context
- prototype - a new instance is returned every time it is referenced. so, the instance isn’t stored in the container. this also means that once an instance is no longer used / referenced, it gets garbage collected
- web scopes - for web environments, the instance isn’t stored in the container
- session - one instance per user per session
- request - one instance per http request
- global session - one instance per application lifecycle, like singleton
- three lifecycle phases - initialization, use and destruction. steps 1-7 below are for initialization
- note: steps 5 and 6 are done by us manually if we use
@Beaninside@Configuration- application context is created
- bean factory is created
- then, bean definitions are loaded into the bean factory from all different sources like component scan. the bean factory only contains metadata & references to the beans & has not instantiated them yet
- bean factory post processors act on the beans to configure them, e.g. fields annotated with
@Valueare set viaPropertySourcesPlaceholderConfigurer. we can implementBeanFactoryPostProcessorif we want, the idea is to configure beans before they are instantiated - beans are instantiated, and we do dependency injection using constructors. beans have to be instantiated in the correct order because of the dependency graph
- we use setters after initialization, e.g. we do dependency injection for setters. in general for good development practice, optional dependencies should use dependency injection via setters while required dependencies should use dependency injection via constructors
- bean post processing can happen, which is further broker down into 3 steps. note - this is bean post processing, step 4 was bean factory post processing
- pre-init bean post processor - implement
BeanPostProcessorto callpostProcessBeforeInitialization - initializer - calls method annotated with
@PostConstruct - post-init bean post processor - implement
BeanPostProcessorto callpostProcessAfterInitialization
- pre-init bean post processor - implement
- use phase - application context maintains references to the beans with scope singleton, so they don’t get garbage collected etc. we can look into the context anytime by implementing
ApplicationContextAwareand usingsetApplicationContext - destruction phase - when close is called on application context.
@PreDestroymethod is called on beans before they are marked for garbage collection
- spring mvc - based on java servlet api, which is blocking. remember servlet (servlet container i.e. tomcat, dispatcher servlet, servlet request / servlet response, etc)
- spring webflux uses project reactor and not java servlet api, so it is non blocking
- similarly,
RestTemplateis the older standard and is on the way to deprecation unlikeWebClient - spring works using proxies
- proxies wrap a class to add behavior, e.g. transaction proxies
- proxies help in adding behavior without modifying code
- proxies don’t act on internal logic like calling private methods
- aspect oriented programming - helps in adding common behavior to many locations
- usually used for cross cutting concerns
- spring aop is easier to implement, does runtime weaving
- aspectj is a bit more difficult to implement, does compile time weaving, and has more features
- performance of compile time weaving > runtime weaving
JoinPointis the codePointCutis what selects aJoinPointAdviceis what gets applied toJoinPoint. three advices have been discussed here -@Before,@AfterReturningand@Around- example - all methods annotated with
@AspectDebuggershould generate logs- AspectDebugger.java -
@Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface AspectDebugger { } - DebuggingAspect.java -
@Slf4j public class DebuggingAspect { @Pointcut("@annotation(AspectDebugger)") public void executeLogging() { } @Before("executeLogging()") public void logMethodCall(JoinPoint joinPoint) { log.debug("started executing method: %s, with args: %s\n", joinPoint.getSignature().getName(), Arrays.toString(joinPoint.getArgs())); } @AfterReturning(value = "executeLogging()", returning = "retVal") public void logMethodCall(JoinPoint joinPoint, Object retVal) { log.debug("finished executing method: %s, with return value: %s\n", joinPoint.getSignature().getName(), retVal); } @Around("executeLogging()") public Object trackExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable { Long startTime = System.currentTimeMillis(); Object retVal = joinPoint.proceed(); Long endTime = System.currentTimeMillis(); log.debug("method: %s took: %dms to execute\n", joinPoint.getSignature().getName(), endTime - startTime); return retVal; } }
- AspectDebugger.java -
- lombok - code generation at compile time
- enable “annotation processing” in intellij for it to work with lombok
@Data- shortcut for@Getter,@Setter,@EqualsAndHashCode,@ToString,@RequiredArgsConstructor@NonNull- throw an exception if null value is passed for field@Value- immutable variant (i.e.private final) of@Data@SneakyThrows- throw checked exceptions without declaring it in the throws clause@Synchronized- better version ofsynchronized@Logfor java util logger. this is not usually recommended@Slf4jfor slf4j logger. slf4j is actually a generic logging facade which uses logback bts in spring- we can see the generated implementation inside the target folder (intellij has a decompiler that can parse this .class file for us)
- delombok - with the help of lombok plugin in intellij, we can generate the code for an annotation. this provides us with a starting point
- get list can be done by annotating controller method with
@RequestMapping("/api/v1/beer") - get by id - make use of path variable
@RequestMapping("/api/v1/beer") public class BeerController { // ... @RequestMapping(value = "/{beerId}", method = RequestMethod.GET) public Beer getBeerById(@PathVariable UUID beerId) { // ... - spring-boot-dev-tools - live reload
- using request body for e.g. for create requests. also, it is a good practice to add the location header, which specifies the id of the newly created object -
@PostMapping public ResponseEntity saveBeer(@RequestBody Beer beer) { Beer savedBeer = beerService.saveBeer(beer); HttpHeaders headers = new HttpHeaders(); headers.add(HttpHeaders.LOCATION, "/api/v1/beer/" + savedBeer.getId()); return new ResponseEntity(headers, HttpStatus.CREATED); } - unit test - test specific sections of code, called code coverage. should execute very fast and in unity i.e. not have external dependencies
- integration test - include the spring context, database and message brokers
- functional test - these tests run against a running instance of the service
- testing pyramid - large number of unit tests, fewer integration and even fewer functional tests
- mock mvc - helps us unit test our controllers
@WebMvcTest- create test splices so that the entire context is not brought up. only the controllers specified are instantiated and not even their dependencies. if we do not specify the controller explicitly, all controllers are instantiated- we mock the dependencies of the controller using mockito
- mocks - predefined answers to the method calls. can assert on executions, e.g. assert it was called with a specific parameter
- spy - wrapper around the actual object
- the assertion of execution can be done using
verify - argument matchers - match the arguments of the execution of mocks. e.g. disallow the predefined response if the matching fails
- argument captors - capture the arguments of the execution of mocks
- apart from stubbing response, we can also perform assertions on executions of mocks -
verify(beerService).updateBeerById(eq(beer.getId()), any(Beer.class)); - we can use
ArgumentCaptorfrom mockito to help us capture arguments passed to mocksArgumentCaptor<UUID> id_ = ArgumentCaptor.forClass(UUID.class); verify(beerService).deleteBeerById(id_.capture()); assertEquals(id, id_.getValue()); - use
@MockBeanfor injecting the service mocks into the controller - we use
jsonpath, which comes from jayway jsonpath - we use hamcrest matchers e.g. notice the use of
is@WebMvcTest(controllers = {BeerController.class}) class BeerControllerTest { @Autowired MockMvc mockMvc; @MockBean BeerService beerService; @Test void getBeerById() throws Exception { Beer beer = Beer.builder().id(UUID.randomUUID()).build(); when(beerService.getBeerById(beer.getId())).thenReturn(beer); mockMvc.perform(get("/api/v1/beer/" + beer.getId()) .accept(MediaType.APPLICATION_JSON)) .andExpect(status().isOk()) .andExpect(content().contentType(MediaType.APPLICATION_JSON)) .andExpect(jsonPath("$.id", is(beer.getId().toString()))); } } - using json path capabilities in assertions -
.andExpect(jsonPath("$.length()", is(2))) .andExpect(jsonPath("$[?(@.id == '%s')]", one.getId().toString()).exists()) .andExpect(jsonPath("$[?(@.id == '%s')]", two.getId().toString()).exists()); - spring boot does configure an object mapper for us by default which we should prefer using in our test by autowiring instead of creating a new one so that our tests are closer to the real word scenario. we use this object mapper for creating request body in post requests
- if the request body contains json, we need to provide the content type header as well
mockMvc.perform(post("/api/v1/beer") .accept(MediaType.APPLICATION_JSON) .contentType(MediaType.APPLICATION_JSON) .content(objectMapper.writeValueAsString(req))) .andExpect(status().isCreated()) .andExpect(header().exists("Location")) .andExpect(header().string("Location", "/api/v1/beer/" + beer.getId())); - when testing using mock mvc,
delete("/api/v1/beer/" + id.toString())can be written asdelete("/api/v1/beer/{beerId}", id.toString())to make use of positional binding - we can also auto-configure mock mvc in a non-
@WebMvcTest(such as@SpringBootTest) by annotating it with@AutoConfigureMockMvc - the default error handling mechanism uses
DefaultHandlerExceptionResolver,ResponseStatusExceptionResolver(maybe more?), which extendsAbstractHandlerExceptionResolver - we can annotate the methods inside controllers with
@ExceptionHandlerto handle specific exceptions i.e. we provide the annotation the exception it should handle. we can use this in the methods of controllers. the downside of this is that it is scoped to a single controller - so, we can annotate a class with
@ControllerAdviceto handle exceptions globally and continue to use@ExceptionHandleron the methods of this classpublic class NotFoundException extends RuntimeException {} @ControllerAdvice public class ErrorHandler { @ExceptionHandler(NotFoundException.class) public ResponseEntity handleMethodNotFound() { return ResponseEntity.notFound().build(); } } @ResponseStatus- we can annotate “custom exceptions” with this annotation to use a specific status for that exception. understand we cannot change code of existing pre-built exceptions, so this only works for custom exceptions. this way, we can skip the controller advice shown above@ResponseStatus(HttpStatus.NOT_FOUND) public class NotFoundException extends RuntimeException { }- to prevent having too many custom exceptions / no point of having custom exceptions that are only used once, we can use
ResponseStatusException. it allows us to throw exceptions with a response statuscatch (Exception e) { throw new ResponseStatusException(HttpStatus.NOT_FOUND, "Foo", e); } - spring boot’s
ErrorControllerdefines how to handle errors, e.g. respond with whitelabel pages in browsers vs json for rest requests. we can configure it using following properties -# whether to include errors attribute - think this includes validation errors? server.error.include-binding-errors=never # whether to include exception attribute server.error.include-exception=false # whether to include message attribute - think this is for exception message? server.error.include-message=never # whether to include stack trace server.error.include-stacktrace=never # whether to display error page in browsers server.error.whitelabel.enabled=true - i observed that by setting the
server.errorproperties to as verbose as possible, the errors property in the response was pretty decent (i.e. include the error message, field name, etc) - however, when testing via mock mvc, something like this was not working -
.andExpect(jsonPath("$.errors.length()", is(2))) .andExpect(jsonPath("$.errors[?(@.defaultMessage == '%s')]", "must not be blank").exists()) .andExpect(jsonPath("$.errors[?(@.defaultMessage == '%s')]", "must not be nullable").exists()) - i think this is more to do with how mock mvc isn’t actually like a full blown integration test. so, to test the validation handling via mock mvc, i did the below -
MvcResult result = mockMvc.perform(post("/api/v1/beer") .accept(MediaType.APPLICATION_JSON) .contentType(MediaType.APPLICATION_JSON) .content(objectMapper.writeValueAsString(beer))) .andExpect(status().isBadRequest()) .andReturn(); MethodArgumentNotValidException e = (MethodArgumentNotValidException) result.getResolvedException(); assertNotNull(e); List<String> defaultMessages = e.getBindingResult().getFieldErrors("beerName").stream() .map(DefaultMessageSourceResolvable::getDefaultMessage) .toList(); assertEquals(2, defaultMessages.size()); assertTrue(defaultMessages.contains("must not be null")); assertTrue(defaultMessages.contains("must not be blanker")); - error handling - already discussed earlier - if the exception thrown is annotated with
@ResponseStatus, it can be handled byResponseStatusExceptionResolver. however, if its not, spring will wrap it aroundServletException. this is not something mock mvc can handle. so basically, below will not work in such cases -MvcResult result = mockMvc.perform(put("/api/v1/beer/{beerId}", beerDto.getId()) // ... .andReturn(); result.getResolvedException() - unit testing spring services example -
@ContextConfiguration(classes = {BeerCSVServiceImpl.class}) @ExtendWith(SpringExtension.class) class BeerCSVServiceTest { @Autowired BeerCSVService beerCSVService; // ... - now, we can use
@MockBeanetc. note how we configureBeerServiceImplbut autowireBeerService - rest template - spring automatically autowires a RestTemplateBuilder with sensible defaults for us
- use uri component builder - as we add things like query parameters, we don’t have to worry about things like encoding special characters etc, unlike when we directly provide the string url by performing concatenations ourselves
- here we expect the server to return an object of type jpa’s Page, and so, we want to deserialize the response into this. now Page is an interface, so we can instead use PageImpl. jackson cannot directly convert to PageImpl (i think this happens because PageImpl does not have the right constructor etc) so we use our own wrapper like below based on (this) -
@JsonIgnoreProperties("pageable") // ignore the pageable property in the response public class JacksonPage<T> extends PageImpl<T> { public JacksonPage(List<T> content, int number, int size, long totalElements) { super(content, PageRequest.of(number, size), totalElements); } } - rest template code - note
UriComponentsBuilder,ParameterizedTypeReference@Service @Slf4j public class BeerClientServiceImpl implements BeerClientService { @Override public Page<BeerDto> listBeers(String beerName) { UriComponentsBuilder uriComponentsBuilder = UriComponentsBuilder.fromPath("/v1/beer"); if (beerName != null) uriComponentsBuilder.queryParam("beerName", beerName); return restTemplate.exchange( uriComponentsBuilder.toUriString(), HttpMethod.GET, null, new ParameterizedTypeReference<JacksonPage<BeerDto>>() { } ) .getBody(); } @Override public BeerDto getBeerById(UUID beerId) { UriComponents uriComponents = UriComponentsBuilder.fromPath("/v1/beer/{beerId}") .buildAndExpand(beerId); return restTemplate.exchange( uriComponents.toUriString(), HttpMethod.GET, null, new ParameterizedTypeReference<BeerDto>() { } ) .getBody(); } } - note - if we don’t really have the need for mapping to a full blown pojo, we can use Map or better JsonNode. JsonNode has methods to parse json and extract different attributes from it etc
List<String> beerNames = new ArrayList<>(); response.getBody() .get("content") .elements() .forEachRemaining(beerNode -> beerNames.add(beerNode.get("beerName").asText())); log.info("response body = [{}]", beerNames); - creating a beer - note
HttpEntity@Override public BeerDto createBeer(BeerDto beerDto) { ResponseEntity<Void> response = restTemplate.exchange( "/api/v1/beer", HttpMethod.POST, new HttpEntity<>(beerDto), Void.class ); URI location = response.getHeaders().getLocation(); return getBeer(location.getPath()); } - there is a way to unit test rest template using
@RestClientTest. i am not a fan of so many annotations, so i prefer@SpringBootTest, unless i want to do unit testing of services, where i can use@ExtendWith(SpringExtension.class). my full so answer@Slf4j @SpringBootTest class BeerClientServiceImplTest { @Autowired BeerClientService beerClientService; @Autowired ObjectMapper objectMapper; @Autowired RestTemplate beerServiceRt; MockRestServiceServer mockServer; @BeforeEach void setUp() { mockServer = MockRestServiceServer.createServer(beerServiceRt); } @Test @SneakyThrows void listBeers() { Page<BeerDto> stubbedResponse = new PageImpl<>( List.of(BeerDtoMocks.two), PageRequest.of(1, 1), 1 ); mockServer.expect(method(HttpMethod.GET)) .andExpect(requestTo(containsString("/api/v1/beer"))) .andRespond(withSuccess() .body(objectMapper.writeValueAsString(stubbedResponse)) .contentType(MediaType.APPLICATION_JSON)); Page<BeerDto> response = beerClientService.listBeers(null); assertEquals(BeerDtoMocks.two.getBeerName(), response.getContent().get(0).getBeerName()); } } - similarly, to mock post calls (we need to return id in location header) -
UUID id = UUID.randomUUID(); URI location = UriComponentsBuilder.fromPath("/api/v1/beer/{beerId}") .buildAndExpand(id) .toUri(); mockServer.expect(method(HttpMethod.POST)) .andExpect(requestTo(containsString("/api/v1/beer"))) .andRespond(withAccepted().location(location)); - spring 6 introduced
RestClientas an alternative toRestTemplate, with fluent api likeWebClient - actuator helps us in monitoring and managing our applications through http endpoints
- we can see all available endpoints here
- adding actuator in spring boot
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> - by default, all endpoints are enabled but not exposed, only the health endpoint is exposed. to expose all endpoints, use
management.endpoints.web.exposure.include=* - we can see the health at /actuator/health
- it would return
{ status: "UP" }if it works fine - this endpoint can for e.g. be useful for configuring readiness probe of spring boot applications deployed on kubernetes
- add property
management.endpoint.health.show-details=ALWAYS, docs to show more details - we can also add custom health checks to show up when we hit the health endpoint (not discussed)
- we can see arbitrary information about the app at /actuator/info
- inside pom.xml inside
spring-boot-maven-plugin, add below -<executions> <execution> <goals> <goal>build-info</goal> </goals> </execution> </executions> - this gives build time, version, maven coordinates of the project, etc
- it generates a file at target/classes/META-INF/build-info.properties
- add the plugin below -
<plugin> <groupId>pl.project13.maven</groupId> <artifactId>git-commit-id-plugin</artifactId> </plugin> - to enable all git related information like branches, last commit, etc., add below
management.info.git.mode=full - it generates a file at target/classes/git.properties
- we can add custom endpoints to actuator as well (not discussed)
- we can secure the health endpoints using spring security! - e.g. allow all users to access the health endpoint and only users with a role of admin to access other endpoints
@Configuration public class SecurityConfig extends WebSecurityConfigurerAdapter { @Override protected void configure(HttpSecurity http) throws Exception { http.authorizeRequests() .requestMatchers(EndpointRequest.to(HealthEndpoint.class)).permitAll() .requestMatchers(EndpointRequest.toAnyEndpoint()).hasRole("ADMIN"); http.csrf().and().httpBasic(); } } - metrics - can integrate with many other monitoring systems like cloudwatch, datadog, prometheus, etc. by using micrometer which is vendor neutral, just like slf4j for logging
- it would return information like jvm memory usage, system cpu usage, etc
- hitting
/actuator/metrics/will show what all endpoints we can hit, then we can hit them via for instance/actuator/metrics/application.ready.time - opencsv - convert csv records to pojo. define pojo as such -
@Data @AllArgsConstructor @NoArgsConstructor @Builder public class BeerCSVRecordDto { @CsvBindByName private Integer row; @CsvBindByName(column = "count.x") // specify column name explicitly private Integer countX; } - now, use the code below -
File file = ResourceUtils.getFile("classpath:data/beers.csv"); List<BeerCSVRecordDto> records = new CsvToBeanBuilder<BeerCSVRecordDto>(new FileReader(file)) .withType(BeerCSVRecordDto.class) .build() .parse(); - note -
ResourceUtilscomes from spring, can be used for reading files in classpath easily
JPA
- ddl - data definition language - creating / dropping tables, indices, etc
- dml - data manipulation language - insert, update and delete data
- dql - data query language - retrieving data, joins, aggregations, etc
- dcl - data control language - grant / revoke access
- at its core, jdbc (java database connectivity) is used to interact with sql databases
- jdbc is used to prepare sql statements, bind arguments, scroll through results, etc
- clearly, this is low level api and therefore tedious to work with
- idea is to work with java objects instead of
java.sql.ResultSet - object / relational paradigm mismatch / impedance mismatch - object models and relational models do not work well together out of the box. some examples are -
- granularity - e.g. let us say user has an address (one to one). in java, there would be a separate address class to represent this, and the user class will contain a reference to the address class. in sql, the same user table might have multiple columns for address like state, city, zip code, etc
- inheritance - e.g. we have multiple billing details, credit card and bank account. in java, there would be separate classes representing credit card and bank account, both extending a common super class billing details. sql doesn’t support inheritance like this
- identity - == in java is for instance identity. equals in java is for instance equality, where all fields can be compared. equality of two rows in database is done by database identity i.e. comparing only the primary key. all three things are different
- association - in java, we can represent them using object references, e.g. for one to many, the one side would have a list as an object reference, while the many side will only have a single object reference. in sql however, we just have a foreign key constraint
- hibernate is basically an orm (object relational mapper)
- so, this helps with interoperability between java objects and underlying rdbms using metadata
- jpa - jakarta persistence api is a specification. hibernate implements jpa
- other hibernate components -
- hibernate validator - implementation of bean validation (jsr 303)
- hibernate envers - audit trail of data
- hibernate search - uses apache lucene underneath to add text search capabilities
- hibernate ogm (object grid mapper) - reusing hibernate for no sql databases including key value, graph, document, etc
- hibernate reactive - non blocking way of interacting with the database
- hibernate jpamodelgen - static metamodel (discussed later)
- spring data commons - helps unify access to different kinds of data stores, be it relational or no sql, and makes code even more concise
- spring data jpa is a jpa specific implementation of spring data, adding functionality like generating implementations based on interface method names
- other spring data components -
- spring data jdbc - sits on top of spring data. so, it eliminates the magic that spring data jpa might have, but at the same time eliminates boilerplate unlike when interacting with jdbc directly
- spring data rest - exposing spring data repositories as rest resources
- spring data mongodb - for mongodb (document database)
- spring data redis - for redis (key value database)
- spring data neo4j - for neo4j (graph database)
- simple class example with id -
@Entity @Data @AllArgsConstructor @NoArgsConstructor public class Message { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Long id; private String text; } EntityManagerFactory/EntityManagerare jpa, whileSessionFactory/Sessionare specific to hibernate, so i assume we should always try using the former. note the syntax below of starting and committing a transaction@Test public void loadFromStorage() throws Exception { List<Message> messages; try (EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa-one")) { try (EntityManager em = emf.createEntityManager()) { em.getTransaction().begin(); Message message = Message.builder().text("hello world!").build(); em.persist(message); em.getTransaction().commit(); em.getTransaction().begin(); messages = em.createQuery("select m from Message m", Message.class).getResultList(); messages.get(0).setText("updated hello!"); em.getTransaction().commit(); } } assertAll( () -> assertEquals(1, messages.size()), () -> assertEquals("updated hello!", messages.get(0).getText()) ); }- using spring data jpa, this is even simpler -
@Test public void loadFromStorage() { Message message = Message.builder().build(); message.setText("hello spring data jpa!"); messageDao.save(message); Iterable<Message> messages = messageDao.findAll(); assertEquals("hello spring data jpa!", messages.iterator().next().getText()); } - note - performance of spring data is considerably slower than regular hibernate when dealing with very huge amounts of data
- for the most part, we should use / be able to use jpa annotations, coming from jakarta.persistence. we should have to use ones coming from hibernate for specific use cases only
- we can have global annotations which do not need to be put into a specific file, like
@NamedQuery. we can keep global metadata inside a file package-info.java - for rapid prototyping, we can set
spring.jpa.hibernate.ddl-auto=updatebut for production, prefer usingvalidateinstead - to log the sql statements, use
spring.jpa.show-sql=trueorlogging.level.org.hibernate.SQL=DEBUG(the later will use the logger i.e. have package name etc. before to help maintain the standard log format). for debugging purpose, we can log the values as well i.e. without the propertylogging.level.org.hibernate.orm.jdbc.bind=TRACEset to trace like this, logs will show the sql but not the actual values in statements like insert - hikari - maintains a connection pool to the database. establishing a connection to the database is a complex / resource intensive operation
- database migration - prior to or in conjunction with the application. help track history, successful vs unsuccessful scripts etc. and thus avoid data loss
- two popular solutions - liquibase (more complex and robust) and flyway
- both have integrations with spring boot (preferred since automated?), maven / gradle plugins and have clis as well
- flyway commands -
- migrate - migrate to latest version
- clean - drop all database objects (NOT FOR PRODUCTION)
- info - print information about migrations
- validate - validate available migrations with applied migrations
- undo - undo the most recently applied migration
- baseline - baseline an existing database i.e. we start using flyway from an intermediary state and not from get go
- repair - repair the schema history tables maintained by flyway
- add the flyway dependency for mysql (version comes from spring boot starter parent)
<dependency> <groupId>org.flywaydb</groupId> <artifactId>flyway-mysql</artifactId> </dependency> - files should be inside of resources/db/migration and have the format
V1__init-beer.sql - note - if encountering too many problems with h2 vs mysql (e.g. i encountered one with uuid described above), we can use db/migration/<vendor> folder - is it better to just use test containers instead?
flyway automatically creates the
flyway_schema_historytable for us the first time around and adds these scripts to it as rowsinstalled_rank version description type script checksum installed_by installed_on execution_time success 1 1 init-beer SQL V1__init-beer.sql -978541020 SA 2023-07-22 20:38:03.365998 4 TRUE - my doubt - hopefully, there is some “serious” locking / transaction level that flyway uses. e.g. what if i have horizontally scaled instances - i would not want there to be any consistency issues
- validation - defensive programming
- e.g. do not allow null / white spaces for name -
@NotNull @NotBlank private String beerName;and add
@Validto the method arguments like sopublic ResponseEntity<Void> saveBeer(@Valid @RequestBody BeerDto beer) { - we can also apply hibernate validations on our entities (which i don’t think is a good practice) and the database type constraints themselves (e.g. column length limits) act as a validation layer as well
- accessing metadata at runtime - we can access the metadata of our models at runtime. two options -
- dynamic metamodel - using jakarta we get the
EntityManagerFactory- remember only this -emf.getMetamodel(). notice how we get access to the entity and its attributes -Metamodel metamodel = emf.getMetamodel(); Set<ManagedType<?>> managedTypes = metamodel.getManagedTypes(); ManagedType<?> itemType = managedTypes.iterator().next(); SingularAttribute<?, ?> idAttribute = itemType.getSingularAttribute("id"); - static metamodel - hibernate to jpa metamodel generator, using
hibernate-jpamodelgendependency. use case - type safe query builder -CriteriaBuilder cb = em.getCriteriaBuilder(); CriteriaQuery<Item> query = cb.createQuery(Item.class); Root<Item> fromItem = query.from(Item.class); Path<String> namePath = fromItem.get(Item_.name); query.where(cb.like(namePath, cb.parameter(String.class, "pattern"))); List<Item> items = em.createQuery(query) .setParameter("pattern", "%Item 1%") .getResultList();
- dynamic metamodel - using jakarta we get the
- note - with spring 6, the javax persistence namespace has been renamed to jakarta
- all annotations like
@Id,@GeneratedValue,@Entity, etc. come from jakarta.persistence now - beauty of
CrudRepository- we can change spring-data-jpa to spring-data-mongodb, without any changes required inside code. this is because it comes from spring-data-commons i believe JpaRepositoryextends bothCrudRepositoryandPagingAndSortingRepositoryfor us, so people usually use this variant- jpa can generate implementations based on interface method names. some things it supports includes
Like,IgnoreCase,OrderBy(withAsc/Desc),Distinct,LessThan,First/Top - we can return
List,Optional, etc - the syntax correctness of these methods are verified when the application context loads up
@Query- the method name in this case can be anything- we can bind parameters by position or by name, and use
@Paramif we bind using name - we can add the
nativeQueryto write native sql, but we loose out on portability (swap underlying relational database easily, e.g. integration test vs production) @Queryissue - while this does give more flexibility around writing complex jpql, the correctness of the query is not verified like interface methods i.e. the query will only fail execution when called. maybe because unlike here, jpa has to generate the corresponding concrete implementation in case of interface methods?- projections - spring data jpa can also help change shape of return type instead of using the persistent class as the return type. e.g. we want to fetch less data from database for optimization / exposing less fields to the service layer, etc
- we can use interface or classes for this custom projection
- interface projection - the underlying “proxy class” would be generated by jpa
- interface projection has two types - close projections and open projections
- close projections - names of interface methods match the names of the persistent class attributes
public interface EmployeeView { String getFirstName(); String getLastName(); } - open projections - when we want to do more complex things. notice how we use spel inside
@Valuepublic interface EmployeeView { @Value("#{target.firstName} #{target.lastName}") String getFullName(); } - issue - spring cannot optimize closed projections since it does not know in advance what columns might be required unlike in open projections
- class projection - the names of the constructor arguments should match the field names of the persistent class exactly
@Data public class EmployeeDto { private String fullName; public EmployeeDto(String firstName, String lastName, String email) { this.fullName = firstName + " " + lastName; } } - issue - nesting of projections (e.g. one to many) is not supported by class based projections unlike interface based projections
- for insert, update, delete operations, we can continue using
@Query, but we also need to add@Modifyingon top of it - the automatic generation of implementation based on method names is also supported for delete operations, e.g.
deleteByLevel deleteByLevelvsdeleteBulkByLevel-deleteByLevelwill first run a query and then delete all objects one by one. this will also thus call “registered callbacks” if any.deleteBulkByLevelwill run a single jpql query i.e. not load all the elements first, and skip all callbacks- qbe - query by example - allows for dynamic query creation - something we cannot do using techniques like
@Query/ interface method names - it has three parts -
- probe - we set the values used by
ExampleMatcherin the persistent class ExampleMatcher- provides the rules for matching the propertiesExample- combines theExampleMatcherand probe
- probe - we set the values used by
- example of qbe. note - if we do not use
withIgnorePaths, default values of the probe (e.g. 0 for primitive integer) would be put in the where clause of the sql / jpql for those propertiesUser user = new User(); user.setEmail("@someotherdomain.com"); ExampleMatcher matcher = ExampleMatcher.matching() .withIgnorePaths("level", "active") .withMatcher("email", match -> match.endsWith()); List<User> users = userRepository.findAll(Example.of(user, matcher)); - doubt - based on how we are manually setting properties inside for e.g.
withIgnorePaths, is this a good use case for introducing hibernate-jpamodelgen? - request param - note how we pass required as false, since it is true by default. use case - e.g. providing pagination related parameters
public List<BeerDto> listBeers(@RequestParam(required = false) Integer pageNumber) { - a neat trick - right click on a method -> refactor -> change signature. we can for e.g. add a new argument to the method, e.g. String beerName. we can also provide a default value, e.g. null. this means that the method and all its usage will be appropriately refactored, without us doing this manually in every place
- implementing paging and sorting -
- to repository methods, add an argument of PageRequest - constructed using page number, size, sort object
- repository methods return a Page - contains the content (list of objects), utility methods to go to next / previous page, etc
- implementation -
// repository Page<PersistentBeer> findAllByBeerStyle(BeerStyle beerStyle, PageRequest pageRequest); // service PageRequest pageRequest = PageRequest.of( pageNumber != null && pageNumber > 0 ? pageNumber - 1 : DEFAULT_PAGE_NUMBER, pageSize != null && pageSize > 0 ? pageSize : DEFAULT_PAGE_SIZE, Sort.by(Sort.Order.by("beerName"), Sort.Order.by("beerStyle")) ); Page<PersistentBeer> beers = beerRepository.findAllByBeerStyle(beerStyle, pageRequest); return beers.map(beerMapper::map); // returns new Page by calling map on all elements of page // tests - for instance, create a Page object to stub return values Page<BeerDto> beers = new PageImpl<>(List.of(one, two)); - entity type - they are the persistent classes we use. they have ids (key constraint, identity constraint) and foreign keys for referencing other entity types (referential constraint). they have their own lifecycle and exist independently of other entity types
- value type - they belong to another entity type and do not have their own lifecycle. they would not have an identity of their own. some examples of value types -
- address in user. can be represented as embeddable classes in jpa
- recall the idea of weak identities and identifying relationships. e.g. a bid is a weak identity and its identifying relations are item and user. so, value types can be represented as a table inside our database as well
- recall - instance identity != instance equality != database identity
- primary keys - should not be null (entity constraint), should be unique (key constraint) and should not be updatable (hibernate does not work well with updatable primary keys)
- due to the restrictions above, and the fact that databases do not “perform optimally” with all types when indexing, it is better to have surrogate keys over natural keys
- for taking help from jpa to generate surrogate keys, we use
@GeneratedValuealong with@Id. otherwise, we will have to take care of assigning identifiers ourselvesGenerationType.AUTO- the default. jpa talks to the underlying database to decide which strategy is the bestGenerationType.IDENTITY- auto incremented primary key columnGenerationType.SEQUENCE- a table is maintained separately, and this is called every time before an insertGenerationType.TABLE- an extra table calledHIBERNATE_SEQUENCESis maintained, where there is one row for each entity. this table would be referred to before every insert
- sequence vs auto increment - why we should consider sequence - in case of auto increment, we need to wait for response from the database for ids. in case of sequence, hibernate is “aware” of the id. so, our instances would have an id assigned to them even if the actual insert inside the db has not happened yet (multiple inserts can be batched, which is when this might be useful)
- another option - uuid - for globally unique ids. advantage - is random and fairly unique across systems and databases. disadvantage - more space and is thus less efficient compared to the incremented ids
@Data @Builder @Entity @AllArgsConstructor @NoArgsConstructor public class PersistentBeer { @Id @GeneratedValue @UuidGenerator // org.hibernate.annotations.UuidGenerator @Column(columnDefinition = "binary(16)") private UUID id; @Version private Integer version; // ... } - note - had to add the
columnDefinitionbecause without it, h2 was failing whenddl-autowas set tovalidatebut mysql works without this as well - calling methods, like
repo.save(obj)doesn’t always guarantee obj will be updated by jpa, so always useobj = repo.save(obj)instead. remember how first level cache is used by jpa etc, so that is where these things probably become important - override table name using
@Table. by default, our camel cased classes are converted to snake case. note - sql is case insensitive - we can also pass properties like schema etc to
@Table hibernate.auto_quote_keyword- have hibernate automatically add quotes to reserved keywords which might be used as table / column names. remember that for spring boot, the prefix ofspring.jpa.propertiesmight come into picture, i.e.spring.jpa.properties.hibernate.auto_quote_keyword=true- we can also use backticks / double quotes explicitly, e.g.
@Table("\"User\"") - if for e.g. we need a naming strategy, e.g. prefix all tables names with
CE_. we can use naming strategy for this -public class CENamingStrategy extends PhysicalNamingStrategyStandardImpl { @Override public Identifier toPhysicalTableName(Identifier name, JdbcEnvironment context) { return new Identifier("CE_" + name.getText(), name.isQuoted()); } } // ... properties.put("hibernate.physical_naming_strategy", CENamingStrategy.class.getName()); - dynamic sql generation - even when we update some columns, we see all columns being updated ie. previous column values itself are used. when using hibernate, when we load our application, hibernate generates crud statements for all our persistent classes and caches them. this way, it does not have to regenerate them entirely every time 🤯. this behavior can be disabled as well. use case - we only update one column, but our sql will try updating all columns by reusing the previous value, but this can become very slow if the table has a lot of columns
- some classes are never updated once created, e.g. bid. hibernate can avoid dirty checking for such classes, thus making it faster. for this, annotate the persistent class with
@Immutable - we can create views using
@Subselect - we can also have the regular repositories for these to use them -
@Entity @Immutable @Subselect( value = "select i.ID as ITEMID, i.NAME as NAME, " + "count(b.ID) as NUMBEROFBIDS " + "from ITEM i left outer join BID b on i.ID = b.ITEM_ID " + "group by i.ID, i.NAME" ) @Synchronize({ "ITEM", "BID" }) public class ItemBidSummary { @Id private Long itemId; private String name; private long numberOfBids; } - why we should mention table names inside
@Synchronize- this way, hibernate knows to flush the updates for these views before running the query - so, remember the three annotations along with
@Entityfor views -@Immutable,@Subselect,@Synchronize - primitive java types, their corresponding wrapper types and most java datetime related types can be directly converted by hibernate to corresponding sql types
- otherwise, if the property extends java.io.Serializable, the property is stored in its serialized form. this can have many issues -
- serialization / deserialization is costly
- if the application is demised, the class is no longer available and therefore the data in the database can no longer be interpreted
- transient - some properties need not be persisted. e.g. we might want to store
initialPricebut notinitialPriceAfterTax. we can use either the javatransientkeyword, or@Transient - checks can be done using multiple ways. just stay consistent -
- hibernate validator, e.g.
@NotNull. can help us validate at presentation layer. also, if using hibernate for ddl generation, this annotation would be ignored - jpa / hibernate annotations, e.g.
@Column(nullable = false). exception would be thrown by jpa before the insert / update statement is executed. also, if using hibernate for ddl generation, this annotation would be factored in- advantage - exception is thrown by hibernate itself without hitting database, thus performant
- disadvantage - duplication of logic if similar constraints are present in ddl as well
- relying on database having
not nulldefined for columns. in this case, a constraint violation exception would be thrown by the database- disadvantage - we lose out on flexibility, since changing constraints requires ddl
- advantage - data integrity guarantees for consumers using this data directly
- hibernate validator, e.g.
- annotate properties with
@Generated, so that hibernate knows that these values are generated by the database, and that hibernate needs to make “an extra round trip” after inserting / updating these entities to fetch the new value, by calling a new select - jpa / hibernate handle usual java to sql type mapping, e.g. Integer / int in java to integer in sql, long / Long in java to bigint in sql, etc
- the idea is while there are some defaults, we can provide more specific values, for e.g. precision and scale for numeric types, length of string for varchar types, etc. not only that, based on what length we specify, hibernate can also decide the corresponding type for mysql - longtext, mediumtext. similarly, for byte[], it can choose tinyblob, mediumblob and longblob
- my understanding - we can lazy load large data types by annotating using
@Basic(fetch = FetchType.LAZY)! - to adjust whether we want to save only date, only timestamp or both date and timestamp, we can use
@Temporal. default is@Temporal(TemporalType.TIMESTAMP), but we can use justDATE/TIME - enums - by default, if we don’t add the annotation
@Enumerated(EnumType.STRING), the ordinal position will be used. issue - if we introduce a new value, it might affect the position of the existing enum values, thus making our data go haywire - property access - jpa can either access the properties directly via fields, or via getter and setter methods. good practice - let everything use fields. if we need the persistence layer to go via getters and setters, we can do it as follows -
@Access(AccessType.PROPERTY) // the other one is AccessType.FIELD private String name; public String getName() { return name; } public void setName(String name) { this.name = name.startsWith("AUCTION: ") ? name : "AUCTION: " + name; } - my understanding - the above can also be achieved using
@ColumnTransformer, in which case we deal with sql instead of java code - derived properties - calculated at runtime using sql. these are calculated every time the item is “retrieved from the database”. so, do consider values getting outdated. doubt - can
@Synchronizediscussed earlier help with this? also, obviously these properties would be ignored in insert and update statements@Formula("(select avg(b.amount) from bid b where b.item_id = id)") private BigDecimal averageBidAmount; - custom converter - e.g. we want to support a special type for currencies in our object model, but this of course might not be supported by the relational database we use. so, we can use custom converters (remember
@Convert,AttributeConverterand@Converter) -// target, as seen by object model class MonetaryAmount implements Serializable { private BigDecimal value; private Currency currency; } // object model type to relation model type interconversion @Converter class MonetaryAmountConverter implements AttributeConverter<MonetaryAmount, String> { @Override public String convertToDatabaseColumn(MonetaryAmount monetaryAmount) { return monetaryAmount.toString(); } @Override public MonetaryAmount convertToEntityAttribute(String s) { String[] split = s.split(" "); // 35.61 USD return new MonetaryAmount( new BigDecimal(split[0]), Currency.getInstance(split[1]) ); } } // declaring the attribute @Convert(converter = MonetaryAmountConverter.class) @Column(name = "price", length = 63) private MonetaryAmount buyNowPrice; - create and update timestamps -
@CreationTimestamp(source = SourceType.DB) private LocalDateTime createdDate; @UpdateTimestamp(source = SourceType.DB) private LocalDateTime updateDate; - my understanding - the default is using jvm’s time, which might be an issue, since for e.g. for a horizontally scaled application the clocks might not be synchronized. disadvantage here is every insert would then not be “buffered” and have to be flushed immediately, just like generation strategy of identity vs sequence?
- embeddable - recall two kinds of association - composition and aggregation. embeddable means composition
- so, embeddable entities -
- do not have their own identity. primary key is owning entity’s primary key
- when owning entity is deleted or saved, same operation is carried out on embeddable entity
- it does not have a lifecycle of its own
- e.g. user (owning) and address -
@Embeddable public class Address { private String street; } @Entity public class User { @Id @GeneratedValue private Long id; private String username; // note - no annotation needed here private Address homeAddress; } - different approaches for inheritance have been discussed now -
- mapped superclass - mapping all subclasses to different tables
@MappedSuperclass public class BillingDetails { @Id @GeneratedValue(strategy = GenerationType.AUTO) private Long id; private String owner; } @Entity public class BankAccount extends BillingDetails { private String account; private String bankName; } @Entity public class CreditCard extends BillingDetails { private String number; private String exp; } - output -
![mapped superclass]()
- optionally, we could have made
BillingDetailsabstract - also, to override properties of superclass from the subclass, we can use
@AttributeOverride, e.g. modify the column nameownertocc_ownerfor the credit card table -@AttributeOverride( name = "owner", column = @Column(name = "cc_owner") ) - this logic around mapped superclass can be extended to repositories as well. note how we use 1. generics and 2.
@NoRepositoryBean. then, we can have specific methods in subclass dao / generic methods in superclass dao@NoRepositoryBean public interface BillingDetailsDao<T extends BillingDetails> extends JpaRepository<T, Long> { Optional<T> findByOwner(String owner); } public interface CreditCardDao extends BillingDetailsDao<CreditCard> { Optional<T> findByNumber(String number); } public interface BankAccountDao extends BillingDetailsDao<BankAccount> { } - tips with mapped superclass -
- problem - doesn’t work with polymorphic associations - we cannot have other entities reference
BillingDetails/BillingDetailscannot reference other entities. this is becauseBillingDetailsitself is not a concrete table - when to use - for top level classes, when further modifications / changes in future are unlikely
- problem - doesn’t work with polymorphic associations - we cannot have other entities reference
- we can instead use table per class
- minute changes to code
- add
@EntitytoBillingDetails - replace
@MappedSuperclasswith@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)@Entity @Inheritance(strategy = InheritanceType.TABLE_PER_CLASS) public abstract class BillingDetails { // ... - remove
@NoRepositoryBeanfromBillingDetailsDao
- add
- advantage of table per class - supports foreign key
- my understanding - internally, table per class can do a “union of the tables of the subclasses” when querying the superclass. this is not supported when using mapped superclass. e.g. a user has a list of messages - and a message can of type sms, email, etc. so, we can use table per class for message class, and this way, while we see different tables in the relational database for different subclasses, we can have associations to our message class
- what above means i think is that in jpql, we can write
select * from BillingDetailsin table per class, but not in mapped superclass - remember to create the
BillingDetailsas an abstract class, otherwise a new table forBillingDetailswas being created - probably because of how things work, another feature - we can now have foreign keys for a generic
BillingDetails, i could see a common sequence table - billing_details_seq for both bank_account and credit_card. so, important - does this mean that there can be foreign keys toBillingDetailsi.e. abstract class when using table per class, but not when using mapped superclass? - so, it feels like table per class could be desirable for actual polymorphism cases, while invalid when we are just trying to move properties like create and update timestamp, id, etc to a common class, in which case mapped superclass is better
- single table hierarchy - a single table is used for representing the superclass, which has all the columns from all the subclasses
- a column for discriminating is used (default is dtype) - this helps determine which subclass a row belongs to
- code - only change is strategy
@Entity @Inheritance(strategy = InheritanceType.SINGLE_TABLE) public abstract class BillingDetails { // ... - output -
![single table]()
- advantage - reporting, gains in performance since no unions etc is involved, schema evolution is straight forward, etc
- disadvantage - data integrity, e.g. cannot enforce not null for columns of subclasses at database level (we can use validation techniques however). there is also a denormalization involved here
- when using repositories of subclasses, hibernate will automatically add filtering logic -
where dtype = 'BankAccount'for us bts - we can of course use the base class in jpql (since the table is of base class after all)
- joined - this strategy will have tables for all subclasses and superclasses
- so, there would be joins involved - the id column in the subclasses (e.g. bank_account below) is both a primary key and a foreign key reference to the superclass (e.g. billing_details below)
- hibernate knows how to perform the joins for us
- code - only change is strategy
@Entity @Inheritance(strategy = InheritanceType.JOINED) public abstract class BillingDetails { // ... - output -
![joined]()
- e.g. if i run
billingDetailsDao.findAll(), the sql run is as below. note the left join and thecase whenclause which helps hibernate determine which subclass it might map toselect b1_0.id, case when b1_1.id is not null then 1 when b1_2.id is not null then 2 end, -- other columns from billing_details b1_0 left join bank_account b1_1 on b1_0.id = b1_1.id left join credit_card b1_2 on b1_0.id = b1_2.id - e.g. if i run
bankAccountDao.findAll(), the sql run is as below. note the normal (inner?) joinselect b1_0.id, -- other columns from bank_account b1_0 join billing_details b1_1 on b1_0.id = b1_1.id - disadvantage - joins are involved, thus taking a performance hit
- imagine our legacy system has two tables - author and author_details. however, in our new domain models, we would like to see it as one class
![secondary table]()
- we can map the above using
@SecondaryTable. note how we mention thePrimaryKeyJoinColumn, because the default was otherwise id i.e. the same column name as that of author table@Entity @SecondaryTable( name = "author_details", pkJoinColumns = @PrimaryKeyJoinColumn(name = "author_id") ) @Data @AllArgsConstructor @NoArgsConstructor public class Author { @Id @GeneratedValue private Long id; private String name; @Column(table = "author_details") private Instant dob; @Column(table = "author_details") private String countryOfOrigin; } - java collections framework works well with hibernate
- we can use
ElementCollection. i think that the point is that the child entity is owned by the parent i.e. “composition”. features like cascading of persistence, deletion, etc follow. the child object need not be marked with@Entityitself. i do not see any real upside of this over the usualOneToManyetc annotations by making the child as an@Entity, so skipping it for now. we get much more fine grained control this way - considerations when writing implementations for associations -
- we should always (as a best practice and as a requirement by jpa) use interfaces like
java.util.Setinstead of concrete implementations - hibernate has its own collection classes for associations like one to many, which helps it with dirty checking. so basically, our collection instances are wrapped with these hibernate collections to help with dirty checking etc
- we should consider initializing with an empty collection’s concrete implementation to avoid null checks / null pointer exceptions for newly created entities
- when creating bidirectional links, we need to carry out two steps for linking both sides, so, we can also add convenience methods like so -
public void addBid(Bid bid) { bids.add(bid); bid.setItem(this); }
- we should always (as a best practice and as a requirement by jpa) use interfaces like
- many to one - this is the simplest, directly maps to the foreign key column. default column name used by jpa below is
item_id. also, notice how we override the fetch type, since the default is eager@ManyToOne(fetch = FetchType.LAZY) private Item item; - we can override the foreign key column name using
@JoinColumn - we can make this bidirectional, by mapping the one to many side as well.
getBidswill automatically fetch all the bids for an item for us - one to many - using the
mappedBycolumn, we tell hibernate that “load using the foreign key already specified inside theitemproperty ofBid”. the default fetch type is lazy.@OneToMany(mappedBy = "item") private Set<Bid> bids = new HashSet<>(); - it is common to set the cascade option on the
OneToMany. in this case, we would want to cascade persist and remove orphanRemoval = true(false by default) tells hibernate that a bid should be deleted if it is removed from an item’s collection. understand how this is different from remove cascade - cascade only ensures calls to delete bids are made when we call delete item@OneToMany( mappedBy = "item", cascade = {CascadeType.PERSIST, CascadeType.REMOVE}, orphanRemoval = true ) private Set<Bid> bids = new HashSet<>();- note - my understanding - another difference between using
ElementCollectionvsOneToManyis that when we do for e.g. collection.clear() in the prior, a single database statement is issued, while deletes happen one by one in the later. so is it safe to assume that relying on cascade when deleting huge chunks of data is not a feasible option, and we should use some custom jpql / try usingdeleteBulkvariants? - another option - when specifying foreign keys, some sql databases support the
on delete cascadeclause. this way, when an item is deleted, its bids are deleted automatically by the database itself. we can tell hibernate about this using -@OneToMany( mappedBy = "item", cascade = {CascadeType.PERSIST, CascadeType.REMOVE}, orphanRemoval = true ) @OnDelete(action = OnDeleteAction.CASCADE) private Set<Bid> bids = new HashSet<>(); - as soon as i comment out the OnDelete line, i see a delete statement for each bid of an item, but with that, i only see one delete statement in the output. is my assumption wrong - i can get rid of the
CascadeType.REMOVEline withOnDelete? - cascading state transitions - entities are independent by default. however, we might want for e.g. bids to be persisted when an item is persisted, bids to be deleted when an item is deleted. for this, we already saw -
CascadeType.PERSIST,CascadeType.REMOVE. along with that, we haveorphanRemovalto delete a bid removed fromitem#bidsand finally, remember our ddl can containon delete cascade - some lombok specific annotations worth adding to one to many -
@Builder.Default @EqualsAndHashCode.Exclude @ToString.Exclude - it might be more feasible to use
@Embeddablefor one to one associations. use one to one when we need to track the entity lifecycle separately i.e. if there are shared references. meaning - if a user just has a billing address and a shipping address, address can be marked as an embeddable. lets say another entity shipment has an address as well. we might want a shipment and a user to maintain reference to the same address instance. in this case, OneToOne becomes more feasible - sometimes, when having one to one mapping, people end up using the same primary key for both tables. in this case, we can use the
@PrimaryKeyJoinColumn - normally, we would map one to one mapping using a separate foreign key / surrogate key combination, which is when we can use
@OneToOne - lastly, if we would like to track one to one relationships via a separate table, we can use the
@JoinTableannotation. some use cases i can think of- the relation itself (and not one of the entities) has some attributes
- storing nulls for foreign keys can be troublesome sometimes. so, it might be better to store all possible relations if any in a separate table altogether
- for one to many side, when defining the field, our options are (recall how it is advisable to use java collections interface on lhs, and not concrete implementations) -
- sets (
Set) - no duplicates, no order - lists (
List) - duplicates, order - bags (
Collection) - duplicates, no order
- sets (
- so based on above, for performance, the best type to use is bags. both de duping and maintaining order are expensive operations for hibernate
private Collection<Bid> bids = new ArrayList<>(); - disadvantage - we cannot eager fetch two or more collections of bags simultaneously, because it results in a cartesian product (discussed later)
- again to customize column names etc, the many side of one to many relation can have the
@JoinColumn, while the one side will have themappedByto indicate it is not the owning side of the relationship - my understanding of list - probably, using
Listinstead ofCollectionnever makes sense, unless we want to use@OrderColumn. this annotation basically orders elements inside the list and maintains the index of the element in a separate column of the table via the column name specified in the@OrderColumn(note - of course,@OrderColumnwould be present on the field having the@OneToMany). now, this results in a performance degradation - hibernate will all the time do the reordering when we insert an element to the list etc (e.g. inserting / deleting element not at the ends of the list can be an o(n) operation). so, we might be better off just treating order as a separate field using@Column, forget about@OrderColumn, and let the ui do the grunt work of sorting / maintaining this order. now, we can useCollectioninstead ofList. however, if one must -// ... @OneToMany(mappedBy = "item") @OrderColumn(name = "bid_rank") private List<Bid> bids = new ArrayList<>(); // ... @ManyToOne private Item item; - output -
![order column]()
- again, we can have a
@JoinTablein case the one to many is optional / the relationship itself has some attributes, and moving them to the many side is logically incorrect// ... @OneToMany(mappedBy = "item") @OrderColumn(name = "bid_rank") private List<Bid> bids = new ArrayList<>(); // ... @ManyToOne @JoinTable( name = "item_bids", joinColumns = {@JoinColumn(name = "bid_id")}, inverseJoinColumns = {@JoinColumn(name = "item_id")} ) private Item item; - output -
![join table one to many]()
- many to many - one side can just have
mappedByfor the@ManyToMany, the other side can define the@JoinTable// ... @ManyToMany @JoinTable( name = "item_categories", joinColumns = {@JoinColumn(name = "item_id")}, inverseJoinColumns = {@JoinColumn(name = "category_id")} ) private Collection<Category> categories = new ArrayList<>(); // ... @ManyToMany(mappedBy = "categories") private Collection<Item> items = new ArrayList<>(); - output -
![many to many]()
- cascading options of remove might not make sense for many to many
- using an intermediate table to track the join table using a separate entity altogether. we can use
@EmbeddedIdto track the composite key. jpa does not pass without setting insertable / updatable to false and specifying column name explicitly inside theIdclass@Entity @Data @AllArgsConstructor @NoArgsConstructor @Builder public class ItemCategories { @EmbeddedId private Id id; @ManyToOne @JoinColumn(insertable = false, updatable = false) private Item item; @ManyToOne @JoinColumn(insertable = false, updatable = false) private Category category; private String linkedBy; @Data @AllArgsConstructor @NoArgsConstructor @Builder private static class Id implements Serializable { @Column(name = "category_id") private Long categoryId; @Column(name = "item_id") private Long itemId; } } // ... @OneToMany(mappedBy = "item") private Collection<ItemCategories> itemCategories = new ArrayList<>(); // ... @OneToMany(mappedBy = "category") private Collection<ItemCategories> itemCategories = new ArrayList<>(); - output of
show create table item_categories-
![many to many with entity]()
- note - we do not have to touch the id column for the most part - we will just call
setItem/setCategory, and let hibernate do the rest for us - entity states -
- transient - when we create a new instance using the
newoperator, the instance is in transient state i.e. it would be lost when no longer referenced. a transient instance will become persistent in multiple ways - e.g.EntityManager#persistis called on it directly, or there is a cascading operation from another instance which references this transient instance, etc - persistent - it has a representation in the database. it has a primary key / id set. an instance can become persistent in multiple ways - via
EntityManager#persist, or it is fetched using a query directly, fetched due to for e.g. lazy loading, etc. persistent instances are always associated with a persistent context - removed - an entity can be deleted from the database in multiple ways - via
EntityManager#remove, removed via orphan removal, etc - detached - e.g. we find an entity using
EntityManager#find, and then close the persistence context. our application logic still has a handle to this instance. the instance is now in detached state. we can make modifications on this instance and callmergelater using a newEntityManageri.e. a detached instance from one persistence context can be merged into another persistence context
- transient - when we create a new instance using the
- persistence context - a persistence context is created when we call
EntityManager em = emf.createEntityManager(), and closed when we callem.close() - when persistence context is closed (
em.getTransaction().commit()?), hibernate performs dirty checking to get the changes made by application - then, it performs a sync with the underlying database using right dml. this sync process is called flushing. we can also call
em.flush()manually when needed to achieve the same? - e.g. hibernate can perform the flush before a query to ensure the updated data is reflected in the query
- the persistence context also represents a unit of work
- the persistence context also acts as a first level of cache - if an entity is queried “again” in a persistence context, the same instance is returned again instead of hitting the database again. this way, during the entire unit of work i.e. inside the persistence context, the entity seen is the same everywhere, and then after the end, the entity can be safely written to the database
- recall impedance mismatch - so, based on above, hibernate guarantees instance identity, therefore instance equality and database identity both automatically. to validate - will this be true then -
repo.findById(1) == repo.findAll().findFirst(where id = 123)- does this mean we do not have to override equals? we should, and that too using a business key (discussed later)
- persistence context is scoped to a thread
- my understanding, tying things together - when we call
EntityManager#persist, the instance goes into persistent state. during this, hibernate has to assign an identity to the instance. now, if we use something like auto increment, hibernate has to actually perform the insert into the database. if we do not use sequence generator etc, hibernate can delay this execution till flushing! - by techniques like delaying flushing dml to the end, batching, etc, hibernate ensures that the database locks are acquired for a short duration (database locks are needed for write operations)
- lazy - further, when we for e.g. run
Item item = em.getReference(Item.class, itemId);, hibernate does not immediately run the sql. the id of the item instance is initialized (since we provided it) but other properties are not. the item object is like a proxy, and the sql is not run until another property is accessed, e.g.item.getName() - if for e.g. we try to access
item.getName()after closing the persistence context, we will get aLazyInitializationException - refresh - e.g. “someone else” makes changes to the database. we can cause hibernate to refetch our instance using
em.refresh(item) - one seemingly clever approach - override the equals method to use the database identifier for equality. disadvantages -
- multiple transient instances added to a set will coalesce into one, since all have their id set as null
- when we call save on transient instances in a set, since their id changes, their hash code changes, and therefore they break the collection
- solution - use a business key i.e. a combination of other attributes which make it unique
- therefore, do not use the surrogate key for equals - hibernate already uses it for its first level of cache as discussed earlier
- we can use the foreign entity association for equals and hash code - e.g. for the bid entity, the business key can be a combination of item and its amount. this might mean using the business key of the foreign entity association internally
- initial databases had 2 phase locking, while modern databases have mvcc
- mvcc - multi version concurrency control - with this, the locking is reduced even further, so that -
- readers do not block writers
- writers do not block readers
- multiple writers can however still not access a record
- for this to work, multiple versions of the same record need to exist
- some common problems have been discussed now -
- the lost update problem -
- transaction one starts to add 10 to our balance
- so, transaction one reads the balance as 100
- transaction two starts to add 20 to our balance
- so, transaction two also reads the balance as 100
- transaction one commits 110 to the database
- transaction two commits 120 to the database
- so the final state is 120, which should have ideally been 130, i.e. the update of transaction one is lost
- unrepeatable read problem -
- transaction one tries finding current balance and reads 100
- transaction two comes in, adds 10 and commits changes to database
- transaction one tries finding current balance again and reads 110 this time
- so, transaction one has read different values for the same row during its execution
- phantom read problem -
- transaction one tries generating a statement and finds 110 transactions for the month of february
- transaction two comes in, adds 10 and commits changes to database
- transaction one tries generating a statement and finds 111 transactions for the month of february
- so, transaction one has read different result sets for the same query during its execution
- my understanding - basically, it is like unrepeatable read, but instead of just the values, the amount of rows increase or decrease, so its due to insert or delete, unlike unrepeatable read which is due to update
- so, both jpa and sql have isolation levels (recall i of acid!). remember - as we increase isolation level, performance degrades. in multi user concurrent systems like today, we might have to sacrifice some amount of isolation for better performance and scalability. just remember the name, the definition will become obvious -
- read uncommitted isolation - all problems are allowed
- read committed isolation - dirty reads are not permitted
- repeatable read isolation - nothing is permitted except phantom reads
- serializable isolation - emulates serial execution i.e. transactions are executed one after another and not concurrently. none of the four problems are permitted. this relies on table locks and not just row level locks
- my understanding 😠 - despite what i wrote above, apparently, due to the change in industry standard from 2 phase locking to mvcc, at least in mysql, lost update is not prevented by an isolation level of repeatable read as well. it is prevented by serializable isolation level, which does not use mvcc at all, and uses 2 phase locking!! this is why, we should use
@Versionalways, or at least that is what i understand from this answer - jpa uses the isolation level of database connection - most resolve to read committed, but mysql uses repeatable read
- however, recall how persistence context cache is used when we attempt to retrieve the same row twice. this means that while isolation level is read committed, we are effectively using repeatable read
- optimistic concurrency control - hibernate supports maintaining version columns for us automatically, using which ensures first commit wins in case of parallel transactions. it is easy to use, so probably use it always
- note - use optimistic concurrency control only when it is acceptable to detect conflicts late in a unit of work. concurrent updates should not be a frequent scenario, otherwise a lot of cpu cycles would be wasted i.e. the computation would be performed and then the update would have to be rejected
- to enable versioning, we use
@Version - we should not have to set version manually, it should be handled by hibernate for us automatically - if hibernate feels that the entity has changed during dirty checking, it would automatically bump up the version number for us bts
- when updating, instead of the where clause having
where id = ?, the where clause now haswhere id = ? and version = ? - we can use int, short, long, and hibernate will wrap again from 0 if the version limit is reached
OptimisticLockExceptionis raised if version is changed by another concurrent transaction- we might not like the extra version column. hibernate can use the timestamp fields like last modified by to help achieve optimistic locking
@Version private LocalDateTime lastUpdatedAt; - tip - due to jvms being possibly deployed on different operating systems, the time might not be guaranteed to be accurate / synchronized in all of them (clock skew). so, we can tell hibernate to ask the database for the timestamp. disadvantage - a database hit is required every time, just like when using auto incremented ids
- how i tested if optimistic locking is working in my application - try updating using same version twice - the second update should throw an exception. also note how i disable the transaction on the test method so that this test is executed “out of a transaction”. finally, recall how exception would be wrapped by
ServletExceptionwhen using mock mvc@Test @SneakyThrows @Transactional(propagation = Propagation.NOT_SUPPORTED) void updateBeerByIdOptimisticLockingCheck() { PersistentBeer beer = beerRepository.findAll().get(0); BeerDto beerDto = beerMapper.map(beer); beerDto.setBeerName("updated beer name"); mockMvc.perform(put("/api/v1/beer/{beerId}", beerDto.getId()) .contentType(MediaType.APPLICATION_JSON) .accept(MediaType.APPLICATION_JSON) .content(objectMapper.writeValueAsString(beerDto))) .andExpect(status().isNoContent()); beerDto.setBeerName("updated beer name again"); ServletException e = assertThrows( ServletException.class, () -> mockMvc.perform(put("/api/v1/beer/{beerId}", beerDto.getId()) .contentType(MediaType.APPLICATION_JSON) .accept(MediaType.APPLICATION_JSON) .content(objectMapper.writeValueAsString(beerDto))) .andExpect(status().is5xxServerError()) ); assertTrue(e.getMessage().contains("ObjectOptimisticLockingFailureException")); } - optimistic lock mode - imagine item to category is many to one. we have many categories and items, and we would like to find the sum of prices for all items for each category. however, when we were iterating through categories, midway through, category for an item was changed, thus making us consider an item into two (or maybe no) categories
- basically, we have the unrepeatable read problem (category_id of item has been updated). note - recall how we discussed that hibernate has default of read committed, and with the help of hibernate persistence context cache, it kind of becomes repeatable read. so, why do we still have the problem? in our case, a result set is returned for every query. so, while hibernate persistence context cache would contain the older version of the item, it would load this item in the result set. yes, the older version of the item is loaded but it can still happen that multiple result sets contain an item / no result sets contain an item
- so, we can set lock mode = optimistic. this way, after performing all the operations (during commit), for each item that we loaded, hibernate would rerun a select and match the version column. if it has changed, it would throw the
OptimisticLockExceptionEntityManager em = emf.createEntityManager(); em.getTransaction().begin(); for (Long categoryId : CATEGORIES) { List<Item> items = em.createQuery("select i from Item i where i.category.id = :catId", Item.class) .setLockMode(LockModeType.OPTIMISTIC) .setParameter("catId", categoryId) .getResultList(); for (Item item : items) totalPrice = totalPrice.add(item.getBuyNowPrice()); } em.getTransaction().commit(); em.close(); - my understanding - why do i even need
LockModeType.OPTIMISTICif i already added@Version- e.g. understand in above example that we actually never modified Items for our query! our problem was that items that we read were modified! by default, jpa will only perform version checking using@Versionfor updates (maybe deletes as well, not sure). here, we want it to perform the version checking for the items we selected as well! so, we useLockModeType.OPTIMISTIC - of course, for
LockModeType.OPTIMISTICto work, we need to have a@Versioncolumn, otherwise what will it check! - note - i think we can annotate jpa repository methods with
@Lock(LockModeType.OPTIMISTIC)as well - disadvantage of lock mode - if we use 100 locks, we will get 100 additional queries for checking the version as described earlier
- i think that the point is that while transaction’s isolation applies to the whole unit of work, the lock would apply to particular operations inside that transaction
- optimistic force increment lock mode - another problem - e.g. we want to find an item’s highest bid. while performing the calculation, someone concurrently added a new bid. so, essentially our highest bid might be wrong. this cannot be caught by adding a version to bid as well
- a trick to solve this - enforce that when the item is read, its version is incremented. this way, when there is a flush, it would be noticed that the item version had changed (because a new bid was added to it)
Item item = em.find(Item.class, itemId, LockModeType.OPTIMISTIC_FORCE_INCREMENT); bid.setItem(item); bidRepo.save(bid); // saving bid increments item version as well // even though item did not change (bid has item_id, bid to item is many to one) - this is a common operation - forceful increment of a root instance when child data is modified
- another advantage of optimistic force increment lock mode - recall how in optimistic lock mode, the version checking happens and then the transaction is committed. it can happen that during this phase itself, there is an update to the database! this is what optimistic force increment lock mode helps solve - i think because the root item’s version needs to be incremented, it needs to be locked, just “reading” the version is not enough
- pessimistic locks - optimistic locks (we discussed two of them above) are implemented by jpa / hibernate using the version column, but pessimistic locks take help of the actual underlying database locks
- the difference between optimistic locks and pessimistic locks -
- optimistic locks use version checks in for e.g. where clause of dml statements, e.g. update only when version = 2
- pessimistic locks use database locks. they can be shared (read locks are usually shared) or exclusive (e.g. write locks are usually exclusive). e.g. of doing this in mysql etc is
select ... for update. the idea is the rows which match the select clause cannot be touched till the lock is released / update is over
- pessimistic force increment lock mode - just the like its optimistic counterpart. the only difference is that here, we increment the version at the beginning of the transaction, and not at the end. we now have a db lock on that record as well till the transaction gets over, so concurrent transactions cannot write to that row. whether they can read or not depends on whether the database uses is 2 phase locking or mvcc. syntax -
LockMode.PESSIMISTIC_FORCE_INCREMENT - pessimistic read - acquire a read (recall how it is implemented as shared) lock
- pessimistic write - acquire a write (recall how it is implemented as exclusive) lock
- so five locks have been discussed - optimistic, optimistic force increment, pessimistic force increment, pessimistic read, pessimistic write
- deadlocks - deadlocks can happen easily in concurrent applications, e.g. one thread tries updating item 1 and then item 2, while another thread tries updating item 2 then item 1. thread 1 waits for lock 2, thread 2 waits for lock 1. “underlying dbms” have capabilities around realizing this and aborting one of the transactions
- one solution - set
hibernate.order_updatesproperty to true, so that updates are processed in order by all applications - spring data jpa has an “implicit transactional context” that kicks in for the repository methods we call if there is no existing transaction. however, when we use for e.g.
@DataJpaTest, it has its own@Transactional. so, behavior of test (using explicit transaction provided by the jpa test) might not be the same as the actual service layer code (using implicit transaction of repositories). so, we should try using explicit transactions as a best practice - both spring and jakarta have the transactional annotations, i believe either can be used
- we can also use
@Transactionalon repository methods - because of how spring proxies / aop works,
@Transactionalwould not kick in when calling internal methods - tests - annotate classes with
@DataJpaTest, it does have its own@Transactional. reason for writing jpa tests - e.g. we use jpa’s query dsl. while it does have compile time checking, we should assert the functionality of our query - note - the
@DataJpaTestannotation wasn’t picking up the properties file, where i had configured h2 url and parameters like MODE=MYSQL (otherwise flyway migration scripts were failing). so, i had to add the below based on this@DataJpaTest @AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE) - if we annotate our test class with
@Transactional, it rolls back the transaction at the end of each test method by default. caveat - remember when usingRANDOM_PORT,DEFINED_PORT, etc. a real servlet environment is used bts. thus, client and server run on different threads. therefore, only client side transaction is rolled back - if a method in bean 1 calls a method in bean 2, which transaction is the method in bean 2 executed? this is defined via transaction propagation -
- required - if a transaction exists, the process is continued in that transaction. else, a new transaction is created
- supports - if a transaction exists, the process is continued in that transaction. else, no transaction is created
- mandatory - if a transaction exists, the process is continued in that transaction. else,
TransactionRequiredExceptionis thrown - requires new - if a transaction exists, it is suspended and a new transaction is created. else, a new transaction is created
- not supported - if a transaction exists, it is suspended. else, no transaction is created
- never - if a transaction exists,
IllegalTransactionStateExceptionis thrown. else, no transaction is created - nested - if a transaction exists, a sub transaction would be created. this means a save point is created and then the processes continues. if there is an error in the sub transaction, the changes would be rolled back up to the save point and then continued. if no transaction was present, a new transaction would be created
- optionally, we can specify
rollbackForto rollback the transaction for certain exceptions, ornoRollbackForto not rollback the transaction for certain exceptions - inside
@Transactionalapart from propagation, isolation, (rollback for / no rollback for), etc. we can specify -- time out - after this, the transaction will automatically rollback
- read only - marking transactions as read only allows jpa to make optimizations. so, remember parameters like this,
@Immutable, etc
- using
@Transactionalis the declarative, preferred approach. we can use an imperative approach viaTransactionTemplateTransactionTemplate transactionTemplate = ...; transactionTemplate.setIsolationLevel(...); transactionTemplate.setPropagationBehavior(...); transactionTemplate.execute((status) -> { return ""; }); - we can load data by navigating the entity graph -
item.getSeller().getAddress().getCity()- the focus of the next few points - fetch plan - what to load
- fetch strategy - how to load
- fetch profile - store the fetch plan and fetch strategy as a fetch profile to reuse it later
- we define the default - lazy or eager in the domain models mapping
- we should try defaulting to lazy when possible, so that data is loaded on demand
- again, hibernate proxies are used to implement this functionality for us
- if for e.g. our entity is in detached state, we might get a
LazyInitializationExceptionwhen trying to access the lazily loaded fields - my understanding - e.g. we want to find the size of a collection in one to many. if we run
item.getBids().size(), i think the entire collection would be loaded due to the proxy nature. we can instead useHibernate.size(item.getBids())to avoid this full query. this way, only thecount(*)query would be run, and theitem.getBids()still remains uninitialized. similarly, we haveHibernate.containsetc - issues -
- lazy loading leads to n + 1 selects problem
- eager loading can lead to cartesian product problem
- we should avoid both extremes, and try finding a middle ground between both
- n + 1 selects problem - 1 query for fetching all items, then n queries for each item’s seller
List<Item> items = em.createQuery("select i from Item i").getResultList(); for (Item item : items) { assertNotNull(item.getSeller.getUsername()); } - cartesian product problem - when we try eager loading of two collections with one sql query. e.g. an item has 3 images and 3 bids. it would result in an sql table with 9 rows. while it is automatically deduped for us if we use
Set, this is not a desirable outcome, since a lot of duplicated rows are sent across the network from database to application. it is more performant to break the query into smaller individual parts - apart from the above problem, we can have a lot of nested eager fetch statements, e.g. item has bids, which can have seller, which can have address and so on. hibernate has a
hibernate.max_fetch_depthproperty. my understanding - after this depth is reached, hibernate will start issuing individual select statements like in lazy loading. by default, there is no preset limit for this property, while sql dialects like mysql set it to 2 by default - batch size is one possible solution for n + 1 selects query problem. we annotate the User entity with
@BatchSizelike below -@Entity @BatchSize(size = 10) public class User { } - refer the item example above, where each
item.getSeller().getUsername()was resulting in a separate db call. with the current method, there would be a call like below - 10 user proxies would be initialized in one go -select * from users where id in (?, ?, ...) - apparently, hibernate is more optimized then i thought it is! it will internally create several batch loaders, which i assume hopefully run in parallel, i.e. if i specify batch size to be 32, and i have to load 31 items, there would be three fetches of sizes 16, 10 and 5, instead of one big fetch of 32. this behavior is configurable via
batch_fetch_style - the
BatchSizeargument can also be set on collections -@BatchSize(size = 10) private Set<Bid> bids = new HashSet<>(); - fetch mode - subselect is another solution for n + 1 selects query problem. we annotate with
@Fetchlike below -@Fetch(FetchMode.SUBSELECT) private Set<Bid> bids = new HashSet<>(); - refer the item example above, where each
item.getSeller().getUsername()was resulting in a separate db call. with the current method, there would be a call like below - fetch all users for all items in one go -select * from bid where item_id in ( select id from item where id in (?, ?, ...) ) - of course, such optimizations are restricted to a persistence context, because after that, probably hibernate discards the entities it stores in memory, and they are garbage collected
- fetch mode - select is a solution for the cartesian product problem. we annotate with
@Fetchlike below -@Fetch(FetchMode.SELECT) private Set<Bid> bids = new HashSet<>(); @Fetch(FetchMode.SELECT) private Set<Image> images = new HashSet<>(); - with the current method, there would be separate calls for bids and images
- now cartesian product of course happens when setting fetch type as eager. since it is a global setting, it is not a reommended approach. the best approach is to dynamically fetch eagerly as and when needed
- dynamic eager fetching in jpql -
select i from Item i left join fetch i.bids - same support is present in criteria builder as well (not discussed)
- fetch profiles - global metadata, so while we can place it on a class, the best place for them is inside package-info.java
@FetchProfiles({ @FetchProfile( name = "fetch_bids", fetchOverrides = @FetchProfile.FetchOverride( entity = Item.class, association = "bids", mode = FetchMode.JOIN ) ), @FetchProfile( name = "fetch_images", fetchOverrides = @FetchProfile.FetchOverride( entity = Image.class, association = "images", mode = FetchMode.JOIN ) ) }) - since fetch profile is a hibernate specific feature, entity manager by itself is not enough for it. this technique of using unwrap to obtain a hibernate session from jpa entity manager is common -
em.unwrap(Session.class).enableFetchProfile("fetch_bids"); Item item = em.find(Item.class, 123); - jpa also has entity graphs for similar functionality
- filtering data - examples -
- when data is read from database by hibernate, restrict some data
- when data is written to database by hibernate, add some audit logs
- we can execute side effects using event listeners, which help hook into the lifecycle of hibernate
@PostPersist- invoked after the entity is stored inside the database- we can anotate any method with this, the class need not extend any special interface etc
- we can use the argument as
Objectto capture for all entities, or specify the type of the entity to capture it only for specific entitiespublic class PersistEntityListener { @PostPersist public void logMessage(Object entityInstance) { User currentUser = CurrentUser.INSTANCE.get(); log.save("Entity instance persisted by " + currentUser.getUsername() + ": " + entityInstance ); } } - we have many more annotations like
@PostPersistfor different points in the lifecycle - for the entity listener above to work, the entity must be annotated with the right listeners -
@EntityListeners(PersistEntityListener.class) @Entity public class Item { // ... - we can also place it directly inside the entity itself, in which case the method will not have any arguments - we would use
thisinstead@Entity public class User { // ... @PostPersist public void logMessage() { User currentUser = CurrentUser.INSTANCE.get(); log.save("Entity instance persisted by " + currentUser.getUsername() + ": " + this ); } } - this was all jpa i.e. annotations like
@PostPersist,@PreRemove, etc. hibernate has an even more powerful api - hibernate interceptors (skipping for now since code is a bit more involved) - envers - helps maintain multiple versions of the data
- we need to annotate entity we would like to audit using
@Audited, and the properties we would like to skip for auditing using@NotAudited - whenever we modify the data in some way, a new record is inserted in the revinfo table. this contains a primary key (rev) and a timestamp. use of timestamp - “give me a list of items as they were on last friday”
- now, each audited table will have a corresponding foreign key (rev) pointing to the revinfo table, and a revtype column which indicates whether the item was inserted, updated or deleted
![envers]()
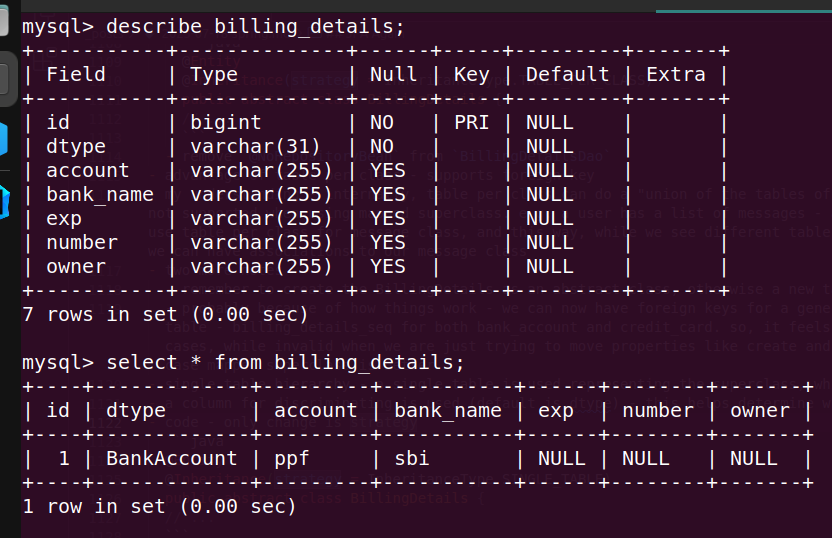
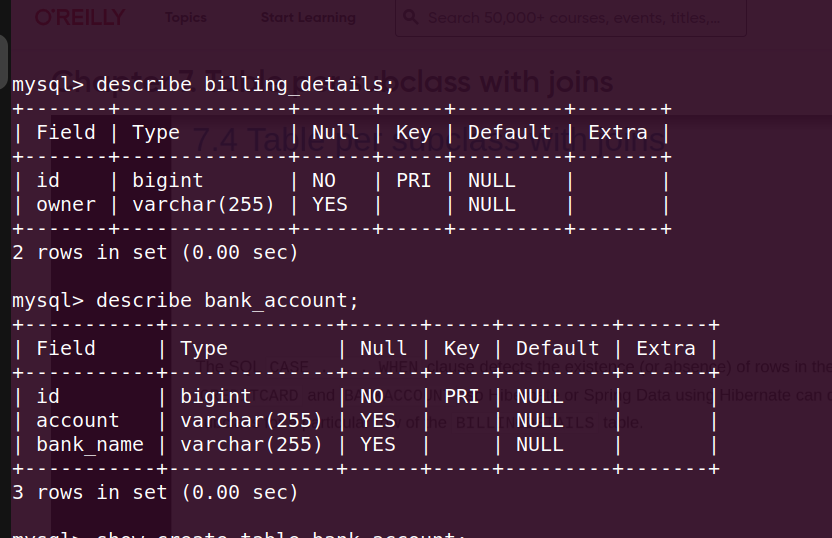
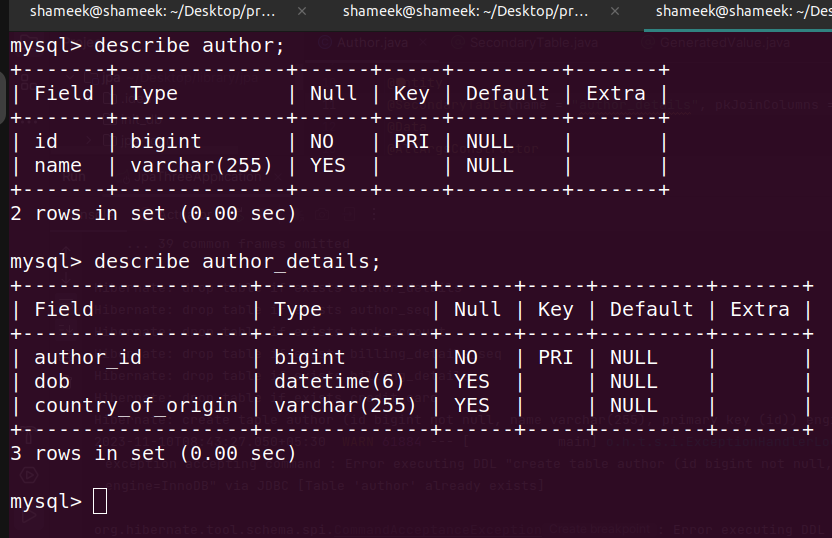
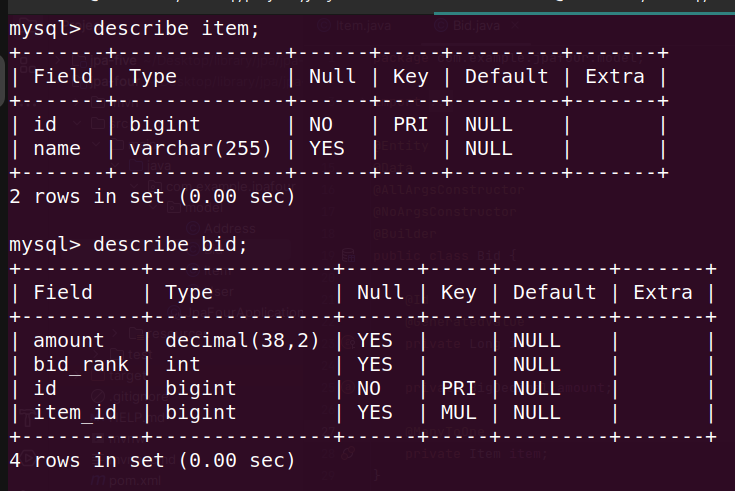
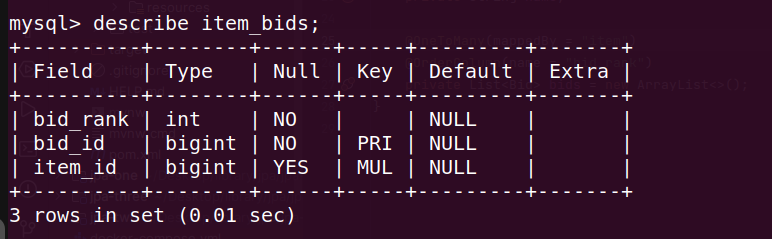
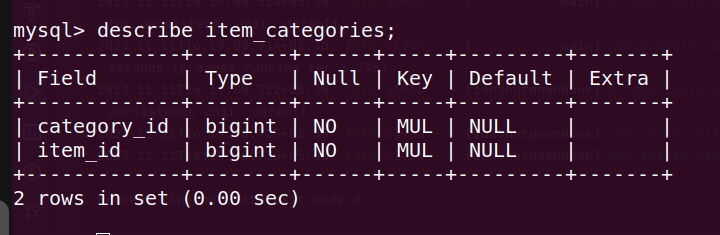
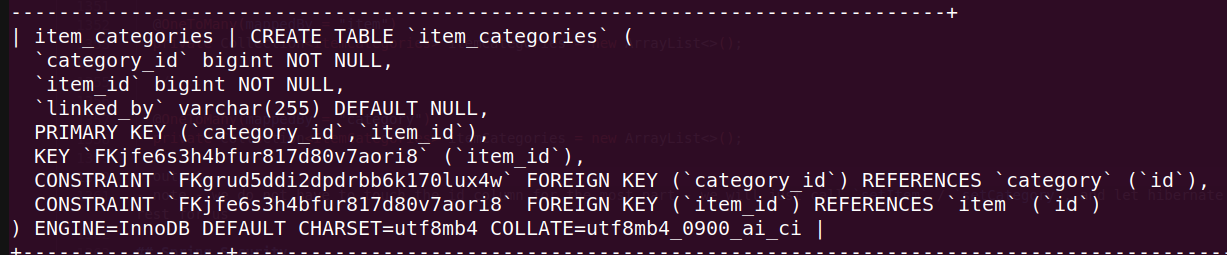
Spring Security
- security is a non functional requirement i.e. it isn’t a part of business concerns, but it is critical
- includes https, firewalls, and application security (the focus of spring security)
- when we add the spring security dependencies, we get a session based authenticated app by default, where the default user name is user and the password is printed in console
- why spring security -
- supports a lot of different mechanisms like basic username / password authentication, oauth, jwt, etc
- supports lot of features like path or method level security with authorization etc
- recall flow - user <-> servlet container <-> filters <-> dispatcher servlet <-> controller handler
- spring security adds a lot of its own filters as well
- spring security architecture -
- user sends their details
- spring security filters will populate the “authentication object” with the user auth details - in spring security, this “authentication object” is the standard responsible to hold details related to current user
- then, this “authentication object” is forwarded to “authentication manager”
- the “authentication manager” talks to different “authentication providers”. it tries all the “authentication providers” our application has configured, and selects the one that is successful
- the “authentication provider” takes the “authentication object” populated with credentials as input, and returns the “authentication object” populated with principal, authorities, etc as output
- we can have different “authentication provider”s - like ldap, oauth, username and password, etc
- “authentication providers” can take help of classes like -
- “user details service” / “user details manager” (which can retrieve users from the given principal)
- note how the communication between “user details service” and “authentication provider” is using “user details” object, and not “authentication object” like the rest of the flow
- “password encoder”
- “user details service” / “user details manager” (which can retrieve users from the given principal)
- finally, the authentication object is stored in the “security context”
- diagram -
![spring security architecture]()
- some concrete implementations of classes discussed above - no need to remember these, this just validates our understanding of the above diagram
UsernamePasswordAuthenticationTokenis an implementation of theAuthenticationobjectProviderManageris an implementation ofAuthenticationManagerDaoAuthenticationProvideris an implementation ofAuthenticationProviderInMemoryUserDetailsManageris an implementation ofUserDetailsManagerUseris an implementation ofUserDetails
- by default, the following
SecurityFilterChainis configured for us, visible insideSpringBootWebSecurityConfiguration@Bean @Order(SecurityProperties.BASIC_AUTH_ORDER) SecurityFilterChain defaultSecurityFilterChain(HttpSecurity http) throws Exception { http.authorizeHttpRequests((requests) -> requests.anyRequest().authenticated()); http.formLogin(withDefaults()); http.httpBasic(withDefaults()); return http.build(); } - this says -
- any request should be authenticated
- for ui as in when hitting endpoints from browser, show the basic form
- when hitting endpoints from postman etc, use basic authentication
- when we specify our own
SecurityFilterChain, this bean would not be used - for e.g. protecting all paths except some -
@Bean public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception { http.authorizeHttpRequests((requests) -> requests .requestMatchers("/notices", "/contact").permitAll() .requestMatchers("/**").authenticated() ); http.formLogin(Customizer.withDefaults()); http.httpBasic(Customizer.withDefaults()); return http.build(); } - recall how authentication providers use
UserDetailsManager. there are multiple implementations ofUserDetailsManagerlike -InMemoryUserDetailsManagerJdbcUserDetailsManagerLdapUserDetailsManager
- all the
UserDetailsManagerimplementations we discussed deal with theUserDetailsobject, which has functionality for getting authorities, username, password, etc - recall we discussed that we use
Authenticationfor communication between spring security classes. so, since theUserDetailsManagerdeals withUserDetails, theAuthenticationProviderconverts theUserDetailsobject intoAuthenticationobject - one of the
UserDetailsManagerimplementations isJdbcUserDetailsManager. it expects tables to be present in a certain way e.g. tables for users, groups, authorities, etc. e.g. refer the ddl here - then, after ensuring the database has these tables, we can add a few records to the users and authorities tables
- then, we just add spring-data-jpa and correct driver for the database connection to the dependencies
- finally add the bean below -
@Bean public UserDetailsManager userDetailsManager(DataSource dataSource) { return new JdbcUserDetailsManager(dataSource); } - what if JdbcUserDetailsManager is not good for us due to the schema rigidity, and we want something custom, we can implement our own
UserDetailsService. what isUserDetailsService😫 - it isUserDetailsManagerwith onlyloadByUsername. our goal is to map the user representation in our system (customer in this case) that our data source understands toUserDetailsobject, which is implemented byUser@Bean public UserDetailsService userDetailsService() { return (username) -> customerDao.findByEmail(username) .map(customer -> new User( customer.getEmail(), // username customer.getPassword(), // password List.of(new SimpleGrantedAuthority(customer.getRole())) // authorities )) .orElseThrow(() -> new UsernameNotFoundException("customer with email " + username + " not found")); } @Bean public PasswordEncoder passwordEncoder() { return new BCryptPasswordEncoder(); } - notice how with so less lines of code, we have a custom authentication + authorization built! - all we did was
- specify the
UserDetailsManagerslice to use viaUserDetailsService - the password encoder to use
- authenticate endpoints using a bean of
SecurityFilterChain
- specify the
- why did we not have to do any password validation? because
AuthenticationProvider(concrete implementation isDaoAuthenticationProvider) does it for us automatically based on the password encoder we configure! remember, we configured user details manager, not authentication provider - password encoder -
- encoding - e.g. base64. an algorithm is used to encode. this doesn’t involve any secret. we can usually use decoding to retrieve the actual value. so, it is not ideal for passwords
- encryption - a secret key is used, so it is more secure than encoding. however, we can still use decryption to get back the original value, if the secret is leaked
- hashing (1 way) - e.g. bcrypt. use a function to obtain a hash value. it is not reversible, so it is very secure. to validate, we pass the input and match it with the stored hashed value. now what does match it actually mean -
- every time the hash is generated for the same input, the output is different! this way, if two users have the same password, the same representation is not stored inside the database, thus making it even more secure. the hashing algorithm knows if the raw input matches the stored hash value
- since i used the bcrypt password encoder, the stored value looks like this -
$2a$10$aj6zt3F9zLr9U39kwVUCxusnd.DvqakuP9/lxp8n8yFHnKrOvIuIK. here, the beginning i.e. $2a gives the version of bcrypt used, and after that, $10 gives the number of rounds used - for brcypt (or generally any hashing algorithm?) we can configure -
- strength
- number of rounds
- salt
- a simple registration process based on the
UserDetailsServiceandAuthenticationProviderwe configured above -@PostMapping("/register") @ResponseStatus(HttpStatus.CREATED) public void registerUser(@RequestBody PersistentCustomer customer) { customerDao.findByEmail(customer.getEmail()).ifPresent((existing) -> { throw new RuntimeException("customer with email " + existing.getEmail() + " already exists"); }); customer.setPassword(passwordEncoder.encode(customer.getPassword())); customerDao.save(customer); } - if we wanted more customization, instead of providing implementation of
UserDetailsManagerviaUserDetailsService#loadByUsername, we can provide a bean ofAuthenticationProvider - understand how based on flow diagram we saw, unlike returning
UserDetailsobject via concrete implementationUser, we now have to returnAuthenticationobject via concrete implementationUsernamePasswordAuthenticationToken@Component @RequiredArgsConstructor public class CustomAuthenticationProvider implements AuthenticationProvider { private final CustomerDao customerDao; private final PasswordEncoder passwordEncoder; @Override public Authentication authenticate(Authentication authentication) throws AuthenticationException { PersistentCustomer customer = customerDao.findByEmail(authentication.getName()) .orElseThrow(() -> new BadCredentialsException("customer with email " + authentication.getName() + " does not exist")); if (!passwordEncoder.matches(authentication.getCredentials().toString(), customer.getPassword())) { throw new BadCredentialsException("passwords do not match for customer with email " + authentication.getName()); } return new UsernamePasswordAuthenticationToken( customer.getEmail(), customer.getPassword(), List.of(new SimpleGrantedAuthority(customer.getRole())) ); } @Override public boolean supports(Class<?> authentication) { return (UsernamePasswordAuthenticationToken.class.isAssignableFrom(authentication)); } } - cors - cross origin resource sharing
- origin = protocol (http) + domain + port
- communication is stopped across origins by browsers to prevent security issues
- so, for e.g. a different website cannot use our api unless our apis allow this website’s domain explicitly
- browsers make a preflight request - the request is made by the browser, to which the backend responds with what methods and endpoints are allowed
- we can either configure cors using
@CrossOrigin(domain)on a per controller basis (usually not ideal), or use the below -// configure the SecurityFilterChain bean like so http.cors(Customizer.withDefaults()); @Bean public CorsConfigurationSource corsConfigurationSource() { CorsConfiguration configuration = new CorsConfiguration(); configuration.setAllowedOrigins(List.of("http://localhost:4200/")); configuration.setAllowedMethods(List.of("*")); configuration.setAllowedHeaders(List.of("*")); configuration.setAllowCredentials(true); UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource(); source.registerCorsConfiguration("/**", configuration); return source; } - something i didn’t know - for e.g. recall the action method on forms? from my understanding, this is not protected by cors, i.e. if a website evil.com has its action set to netflix.com, even if netflix configures cors correctly, this form action would go through! this concept is important in csrf discussed below
- also my understanding of where csrf might be important - cors depends on browser the client uses, what if the client uses a browser that does not have cors functionality?
- csrf - security vulnerability (unlike cors, which is a guard rail provided by browsers)
- csrf - cross site request forgery
- example -
- we log into netflix.com, and netflix stores a cookie in our browser - recall how cookies are scoped to a domain
- assume we click on a malicious link, which actually makes a put api call to netflix.com, to for e.g. change the password of the current user
- since netflix had already stored a cookie in our browser, the request goes through, and netflix thinks it is a request from a legitimate user, and the password of our account is changed easily!
- solution - a secure random csrf token is generated, which is unique per session
- so, assume with csrf implemented correctly, our ui receives a csrf token inside a cookie / response header, etc along with a separate cookie for authentication
- for further requests, we forward this csrf token inside the request header / request body along with the authentication cookie. do not send csrf token as a cookie, since then we are back to the same problem as authentication cookie! we can receive the csrf token as a cookie, but then we need to parse it and send it as a request body / header. this parsing cannot be done by evil.com, since it is a different domain, so it does not have access to cookies
- disabling csrf -
http.csrf(csrf -> csrf.disable());/http.csrf(AbstractHttpConfigurer::disable); - configuring csrf correctly - we can use
CookieCsrfTokenRepository, which writes the csrf token to a cookie namedXSRF-TOKENand reads it from an http request header namedX-XSRF-TOKENor the request parameter_csrf - this documentation seems to have a good explanation for csrf, skipping for now
- my doubt - if we for e.g. send jwt not as a cookie but as a header, wouldn’t we automatically be protected by csrf? because the malicious website cannot “parse” or “access” the jwt, just like it cannot access or parse the csrf cookie
- authentication error - 401, authorization error - 403
- authentication happens before authorization
- authorities are stored via interface
GrantedAuthorityand concrete implementationSimpleGrantedAuthority - these authorities are available on both
UserDetails(used betweenUserDetailsManagerandAuthenticationProvider) andAuthenticationobject (used betweenAuthenticationProviderandAuthenticationManager) - code example -
http.authorizeHttpRequests((requests) -> requests .requestMatchers("/myAccount").hasAuthority("view_account") .requestMatchers("/myBalance").hasAnyAuthority("view_account", "view_balance") .requestMatchers("/user").authenticated() .requestMatchers("/contact").permitAll() ); - like authority, we have hasRole and hasAnyRole as well
- my understanding - spring requires that roles have the
ROLE_prefix- so when using hasRole etc, do not specify the
ROLE_prefix.requestMatchers("/myBalance").hasAnyRole("user", "admin") .requestMatchers("/myLoans").hasRole("user") - either save to the database with the
ROLE_prefix, or when mapping toGrantedAuthorityinsideUserDetailsService, add theROLE_prefix (internally, our schema stores one to many forPersistentCustomerandPersistentAuthority)@Entity @Data @AllArgsConstructor @NoArgsConstructor @Table(name = "authorities") public class PersistentAuthority { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; private String name; @ManyToOne @JoinColumn(name = "customer_id") private PersistentCustomer customer; public GrantedAuthority map() { return new SimpleGrantedAuthority("ROLE_" + name); } }
- so when using hasRole etc, do not specify the
- authority - individual actions like “view account”, “view balance”, etc
- role - group of authorities
- one practice used at my firm -
- think of privilege as action + resource combination - “view balance”, “view card”, etc - these map to authorities
- different roles have different authorities - admins and ops can have “edit card”, all users will have “view account” etc
- allow assigning multiple roles to users
- filters - we can write our own filters and inject them into the spring security flow
- filter chain - represents a collection of filters which have to be executed in a defined order
- so, on
HttpSecurity http, we can callhttp.addFilterBefore,http.addFilterAfterandhttp.addFilterAt@Slf4j public class UserLoggingFilter implements Filter { @Override public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException { // typically this typecasting might be needed, not used here though HttpServletRequest request = (HttpServletRequest) servletRequest; HttpServletResponse response = (HttpServletResponse) servletResponse; Authentication authentication = SecurityContextHolder.getContext().getAuthentication(); if (authentication != null) { log.info("user {} with authorities {} has logged in", authentication.getName(), authentication.getAuthorities()); } filterChain.doFilter(servletRequest, servletResponse); } } http.addFilterAfter(new UserLoggingFilter(), BasicAuthenticationFilter.class); - we implemented
Filterabove. we can instead use -GenericFilterBean- has access to a lot of other things like context, environment, etcOncePerRequestFilter- to ensure that the filter is executed only once, even if it is invoked multiple times by the underlying logic
- tokens - when the clients login successfully, they are returned a token from the backend. the clients should then attach this token to every request to access protected resources
- advantage of using tokens
- we do not share our credentials for every request every time like in for e.g. basic auth, we just pass around the token every time
- if tokens are compromised we can easily regenerate them. credentials cannot be changed easily for every user
- tokens can have a expiry attached to them, post which they have to be regenerated
- tokens allow storing of other user related information like name, email, roles, etc. this way, the backend can simply use these without every time for e.g. “fetching” this information
- we can reuse tokens for different kinds of applications like maps, email, etc
- statelessness - for horizontally scaled applications since it doesn’t need sessions
- jwt tokens - they have the format
<<header>>.<<payload>>.<<signature>> - header - metadata like algorithm used for generating token, e.g. hs256 (stands for hmacsha256?). it is in base64 encoded format
- payload - name, email, roles, who issued the token, expiry, etc. it is also in base64 encoded format
- e.g. someone can easily decode the payload using base64 and add a role to it and encode it back again using base64. solution - signature
- signature - a digital signature for tokens. it helps ensure that the token has not been tampered
- the algorithm in header is used to generate this signature -
hmacsha256(base64(header) + '.' + base64(payload), secret). the secret here is only known to the backend - on receiving the token, the backend can recompute the signature using the provided header and payload. if the signatures do not match, the backend can conclude that the token is invalid
- try to compare how jwt matches all the advantages we had mentioned for using tokens
- add these maven dependencies -
<dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt-api</artifactId> <version>${jjwt.version}</version> </dependency> <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt-impl</artifactId> <version>${jjwt.version}</version> <scope>runtime</scope> </dependency> <dependency> <groupId>io.jsonwebtoken</groupId> <artifactId>jjwt-jackson</artifactId> <version>${jjwt.version}</version> <scope>runtime</scope> </dependency> - disable spring security’s session creation
http.sessionManagement(session -> session.sessionCreationPolicy(SessionCreationPolicy.STATELESS)); - we generate the jwt using
OncePerRequestFilter. notes- we should do this when we can be sure that the authentication is successful, so we use
addFilterAfter - using
shouldNotFilter, we ensure that this token is generated only when the user logs in, which happens using the /user path
// secret can come from application.properties http.addFilterAfter(new JWTTokenGeneratorFilter(secret), BasicAuthenticationFilter.class); @RequiredArgsConstructor public class JWTTokenGeneratorFilter extends OncePerRequestFilter { private final String secret; @Override protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException { Authentication authentication = SecurityContextHolder.getContext().getAuthentication(); if (authentication != null) { SecretKey key = Keys.hmacShaKeyFor(secret.getBytes(StandardCharsets.UTF_8)); String serializedAuthorities = authentication .getAuthorities() .stream() .map(GrantedAuthority::getAuthority) .collect(Collectors.joining(",")); String jwt = Jwts.builder() .claim("username", authentication.getName()) .claim("authorities", serializedAuthorities) .issuedAt(new Date()) .expiration(new Date(new Date().getTime() + (24 * 60 * 60 * 1000))) .signWith(key) .compact(); response.setHeader(HttpHeaders.AUTHORIZATION, jwt); } } @Override protected boolean shouldNotFilter(HttpServletRequest request) throws ServletException { return !request.getServletPath().equals("/user"); } } - we should do this when we can be sure that the authentication is successful, so we use
- verifying the token - this time, we use
addFilterBeforeand also invert the condition insideshouldNotFilterhttp.addFilterBefore(new JWTTokenValidatorFilter(secret), BasicAuthenticationFilter.class); @RequiredArgsConstructor public class JWTTokenValidatorFilter extends OncePerRequestFilter { private final String secret; @Override protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException { String jwt = request.getHeader(HttpHeaders.AUTHORIZATION); if (jwt != null) { try { SecretKey key = Keys.hmacShaKeyFor(secret.getBytes(StandardCharsets.UTF_8)); Claims payload = Jwts.parser() .verifyWith(key) .build() .parseSignedClaims(jwt) .getPayload(); Authentication authentication = new UsernamePasswordAuthenticationToken( payload.get("username"), null, AuthorityUtils.commaSeparatedStringToAuthorityList(payload.get("authorities", String.class)) ); SecurityContextHolder.getContext().setAuthentication(authentication); } catch (Exception e) { throw new BadCredentialsException("invalid token received"); } } } @Override protected boolean shouldNotFilter(HttpServletRequest request) throws ServletException { return request.getServletPath().equals("/user"); } } - method level security - add
@EnableMethodSecurityon any@Configuration/@SpringBootApplicationclass@Configuration @RequiredArgsConstructor @EnableMethodSecurity public class SecurityConfig { - in the pre and post annotations, we can also use spel (spring expression language)
@PreAuthorize- decide if a user is authorized to call a method before actually invoking the method@PreAuthorize("hasAnyRole('user', 'admin')") @PreAuthorize("hasAuthority('view_details')") @PreAuthorize("#username == authentication.principal.username") public void preAuthorizeExample(String username) { }- for complex requirements - we can call custom methods, methods on beans, etc afaik from inside these annotations. then we can for e.g. pass the authentication object from inside the annotation to these methods as well
@PostAuthorize- would not stop the method from being executed, but would run after the invocation- spring aop is used for implementing these annotations bts
@PreFilterand@PostFilter- works on objects of type collections. helps filter inputs / outputs. i don’t see its use case as of now