Downsides of File Based Systems
- data redundancy - data repeated at different places
- data inconsistency - data update at one place might not be reflected at another place
- difficult data access - searching through records can be difficult
- security problems - granular control to allow access to databases
- difficult concurrent access - erroneous updates if people try editing files simultaneously, file locks allow only one person to edit files at a time
- integrity constraints - we can’t enforce constraints like ensuring a specific data type for an attribute
- databases backup and recovery features are less efficient
Entity Relationship Data Model
- er model is a high-level conceptual data model
- they are used in documentations via er diagrams
- entity - an object like a particular employee or project e.g. an employee jack
- entity type - type of the entity e.g. Employee
- entity set - group of all entities (not entity types)
- attribute - an entity has attributes like age, name
- an entity type is represented as a rectangle
- an attribute is represented as an oval. it can be of following types -
- simple attribute
- composite attribute - composed of multiple attributes e.g. name from first name and last name. it is represented as a tree of ovals
- multivalued attribute - can take an array of values e.g. phone number. the oval has a double outline
- derived attribute - calculated from other attributes e.g. age from birthdate. the oval has a dotted outline
- key attribute - has a value which is distinct for each entity, also called primary key e.g. ssn (social security number) of an employee. represented by an underline on the attribute
- composite key - multiple keys combine to uniquely identify an entity. e.g. vin (vehicle identification number) using state and a number. represent as a composite attribute and underline the key attribute as well
- natural key - use an attribute to uniquely identify an entity. e.g. isbn of book
- relationship - an association between two entities e.g. jack works on project xyz
- relationship type - type of relation e.g. works_on
- relationship set - group of all relationships (not relationship types), just like entity set
- a relationship type is represented as a diamond
- degree - defined on a relationship type, it represents the number of participating entities. it can be of the following types -
- unary (recursive) - an entity type is linked to itself, e.g. an employee supervises another employee
- binary - two entity types are linked, e.g. employee works on a project
- ternary - three entity types are linked, e.g. supplier supplies parts to project
- binary relationship constraints -
- cardinality - represent by writing 1 / N on the arrow
- one to one - an entity in set a can be associated to at most one entity in set b and vice versa as well e.g. an employee manages a department
- one to many - an entity in set a can be associated to many entities in set b but an entity in set b can be associated to at most one entity in set a e.g. employees are a part of a department
- many to many - an entity in set a can be associated to many entities in set b and vice versa e.g. employees work on a project
- participation -
- total participation - each entity must participate at least once in the relation, e.g. in employees working on a project, a project has total participation, represented as a double line
- partial participation - an entity need not participate in the relation, e.g. in employees working on a project, an employee has partial participation (e.g. hr), represented as a single line
- cardinality - represent by writing 1 / N on the arrow
- attributes on relation types - unless cardinality is many to many, since a table is created for many to many, we should try and move attributes of relationships to one of the tables
- weak entity - they cannot exist independently e.g. a course cannot exist without a program. they don’t have key attributes (look above) of their own. they are identified via their owner or identifying entity type, and the relation between the weak and identifying entity is called identifying relationship. the attribute which helps in differentiating between the different weak entities of an identifying entity is called a partial key. e.g. dependents of an employee. weak entity is represented as a double line for the rectangle and identifying relationship is represented as a double line for the diamond. partial key is represented as a dotted underline. weak entity should of course, have a total participation
- strong entity - have their own key attributes
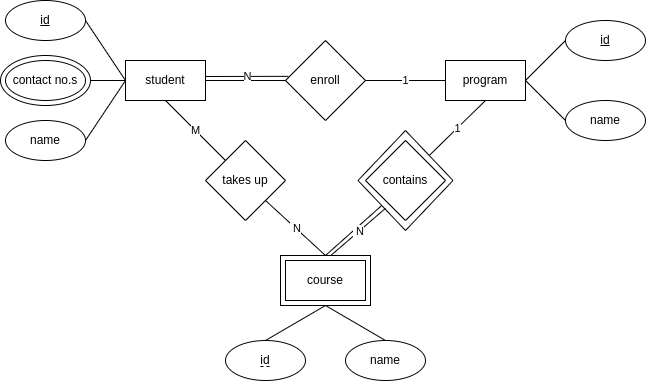
ER Diagram Example
- entities -
- students have a name, a student identifier, one or more contact numbers
- programs have a name, a program identifier
- courses have a name, a course identifier
- relationships -
- student takes up one or more courses
- student must enroll in a program
- program contains courses
Relational Model
- relation - collection of related data, represented as a table
- tuple - also called records, represented as a row, an instance of the type of object stored in the table
- attribute - represented as a column, describe the record
- relation schema - relation name with its attributes’ names e.g. employee(id, name, phone number)
- database schema - combination of all relation schemas
- database instance - information stored in a database at a particular time
- domain - set of acceptable values an attribute can contain
- in a relation, sequence of rows and columns are insignificant
- keys - we need keys to fetch tuples easily and to establish a connection across relations
- different types of keys are -
- super key - set of attributes that can uniquely identify any row. super key is like a power set. e.g. in employee, (id), (phone), (id, name), (name, phone), (id, phone), (id, name, phone) are all super keys
- candidate key - minimal set of attributes that can uniquely identify any row e.g. id, phone number. (id, name) is not a candidate key as id itself can uniquely identify any row
- primary key - one out of all the candidate keys is chosen as the primary key e.g. id of employee
- composite key - candidate keys that have two or more attributes e.g. vehicle(state, number)
- alternate key - any candidate key not selected as the primary key
- foreign key - the primary key of a relation when used in another relation is called a foreign key. it helps in connecting the two relations, the referencing and referenced relation
- integrity constraints - to maintain the integrity of database i.e. maintain quality of information as crud keeps happening, following rules are present -
- domain constraint - each value of an attribute must be within the domain
- entity constraint - all relations must have primary key, it cannot be null
- referential constraint - foreign key must either reference a valid tuple or be null
- key constraint - primary key must be unique
- common relational database operations - crud i.e. create, read, update, delete
Functional Dependency
- X ➔ Y means given X, we can determine Y e.g. in student(id, name), id ➔ name but reverse is not true
- X is called determinant while Y is called dependent
- armstrong’s axioms are a set of inference rules to determine all functional dependencies
- axiom of reflexivity - if Y ⊆ X, then X ➔ Y
- axiom of augmentation - if X ➔ Y, then XZ ➔ YZ
- axiom of transitivity - if X ➔ Y and Y ➔ Z, then if X ➔ Z
- prime attribute - a part of any candidate key
- partial dependency - when a non-prime attribute is dependent on a prime attribute
- transitive dependency - when a non-prime attribute is dependent on another non-prime attribute
Normalization
- normalization helps in determining the level of redundancy in a database and providing fixes for them
- there are six normal forms, but only 1nf, 2nf, 3nf and bcnf have been discussed
- sometimes, we do not normalize our database entirely. it not only improves performance for analytics, but if data is duplicated, it works like a double check, thus reducing chances of corrupt data
First Normal Form
for being in first normal form or 1nf, relation shouldn’t have a multivalued attribute. e.g.
| id | name | phone |
|---|---|---|
| 1 | jack | 8745784547, 6587784512 |
| 2 | jane | 3412478452 |
should be converted to
| id | name | phone |
|---|---|---|
| 1 | jack | 8745784547 |
| 1 | jack | 6587784512 |
| 2 | jane | 3412478452 |
Second Normal Form
for being in second normal form or 2nf, relation should be in 1nf and shouldn’t have partial dependencies. e.g.
| student_id | course_id | course_fee |
|---|---|---|
| 1 | 1 | 120 |
| 2 | 2 | 150 |
| 1 | 2 | 150 |
this has partial dependency course_id ➔ course_fee since primary key is (student_id, course_id).
so, it should be split into two tables
| student_id | course_id |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 1 | 2 |
| course_id | course_fee |
|---|---|
| 1 | 120 |
| 2 | 150 |
note how this also reduced data redundancy by storing the course_fee values only once
Third Normal Form
for being in third normal form or 3nf, relation should be in 2nf and shouldn’t have transitive dependencies. e.g.
| student_id | country | capital |
|---|---|---|
| 1 | india | delhi |
| 2 | nepal | kathmandu |
| 3 | nepal | kathmandu |
this has transitive dependency country ➔ capital since the capital can be derived from country, and the primary key is student_id. so, it should be split into
| student_id | country |
|---|---|
| 1 | india |
| 2 | nepal |
| 3 | nepal |
| country | capital |
|---|---|
| india | delhi |
| nepal | kathmandu |
Boyce Codd Normal Form
- for being in boyce-codd normal form or bcnf, relation should be in 3nf and a dependency A ➔ B is allowed only if A is a super key, doesn’t matter what B is which make sense, as super keys should be able to find everything. so to check for bcnf, only check if lhs of dependency is super key or not
- e.g. - AB ➔ C and C ➔ B. candidate keys are AB and AC. neither of the dependencies are partial or transitive, so it is in 3nf already. however, C is not a super key, yet we have C ➔ B. so, it is not in bcnf
- my understanding - for bcnf, split into two tables - AC (AC is candidate key) and BC (C is candidate key)
- basically, since prime ➔ non-prime was covered in 2nf, non-prime ➔ non-prime was covered in 3nf, we wanted to remove (prime / non-prime) ➔ prime in bcnf
About SQL
- sql is a standard that has been adopted by various vendors for their implementations. the implementations include db2 by ibm, oracle rdbms by oracle, sql server by microsoft, postgresql and mysql which are opensource, etc. this blog is about mysql implementations of concepts, so things can be different for other distributions
- application / client layer - helps in client connections, authentication and authorization
- server layer - it parses, analyzes and optimizes queries. it also maintains cache and buffers. it makes an execution plan which gets fed into the storage engine layer
- storage engine layer - this layer actually writes and retrieves data from the underlying physical storage. mysql supports different storage engine layers like InnoDB, MyISAM, etc. which we can view by
show engines. InnoDB is the default. e.g. the way transactions are carried out in them can be different
Database Commands
show databases- list all the database. it would only show the databases that we are authorized to viewuse database_name- selecting the database with name database_name. future queries would be performed on the selected databaseshow create database mysql- shows the command using which the database was createdshow tables- display the tables in the current databasecreate database if not exists movie_industry- create the database if it doesn’t existdrop database if exists movie_industry- drop the database if it exists
Table Commands
- we have a lot of data types in mysql, look here, categorized into numeric data types, date and time data types, string data types, spatial data types, json data type. e.g. numeric data type can have int, bigint, tinyint, decimal
describe user- describe the structure of a tableshow create table user- shows the command using which the table was created- we can provide a constraint for non-nullable fields using
not null - we can provide a default value using
default - we can automatically assign the next integer using
auto_increment. auto increment has a few restrictions -- there can be only one column in a table marked as auto increment
- the auto increment column should be indexed
- the auto increment column cannot have a default value
- create table example -
create table if not exists actors ( id int auto_increment, first_name varchar(20) not null, second_name varchar(20) not null, dob date not null, gender enum("male", "female", "other") not null, marital_status enum("married", "divorced", "single") not null default "unknown", net_worth_in_millions decimal not null, primary key (id) ); - we can use
defaultwhile inserting data to instruct mysql to use the default value. it would work for auto increment id as well. we can also not specify the column name altogether - insert into table by not specifying id -
insert into actors (first_name, second_name) values ("jennifer", "aniston"); - insert into table by specifying id which is auto increment -
insert into actors (first_name, second_name, id) values ("jennifer", "aniston", default), ("johnny", "depp", default); - querying in tables by selecting all columns -
select * from actors; - select specific columns and filter results using
whereclause -select first_name, second_name from actors where first_name = "tom"; - we have a lot of operators in mysql, look here
- we can use the
likeoperator with where clause for pattern matching._can be used to match exactly one character,%can be used to match 0 or more characters -select * from actors where first_name like '_enn%'; -- matches jennifer - we can use
castto change data type - e.g. order query results by number, but number would be treated as strings i.e. 2 > 10
select * from actors order by cast(age as char); - we can
limitthe number of results returned, andoffsetit from a certain point. note: sql will automatically handle even if our limit or offset goes beyond the number of rows by giving back sensible resultsselect first_name from actors order by age desc limit 4 offset 3; - delete selective rows -
delete from actors where gender = "male" order by age desc limit 3; - for deleting all rows, a faster method is
truncate actors, it would delete the table entirely and recreate it - update selective rows -
update actors set age = 25 order by first_name limit 3; - we can alter name and data type of column, provide a default value. note: while altering data type, the new and old data types should be compatible -
alter table actors change first_name firstName varchar(20) default "anonymous"; - adding a column -
alter table actors add first_name varchar(20); - deleting a column -
alter table actors drop first_name; - indices help in querying data efficiently, just like we search for words in a dictionary. downside is the overhead of creating, storing and maintaining these indices. internally, mysql uses b / b+ trees with the keys of the nodes as primary indices. this helps in efficient querying of data
- we can create an index on name to speed up queries -
alter table actors add index index_name (first_name); - we can also drop that created index -
alter table actors drop index index_name; - alter table name -
alter table actors rename Actors; - delete table -
drop table if exists actors; - aliases can be used to give temporary names, as they help us write queries that are more readable
select t1.first_name as a, t2.first_name as b from actors as t1, actors as t2 where t1.net_worth_in_millions = t2.net_worth_in_millions and t1.id > t2.id; - distinct is a post-processing filter i.e. works on the resulting rows of a query & can be used on multiple columns
select distinct first_name, last_name from actors; - aggregate methods like
min,max,sum,countcan be used -select count(*) from actors; - group by - helps group rows based on a particular column. we cannot use columns not present in group by for select, having, or order by clauses
select gender, avg(net_worth_in_millions) from actors group by gender; - while the where clause helps us filter rows, the having clause helps us filter groups
select marital_status, avg(net_worth_in_millions) as avg_net_worth_in_millions from actors group by marital_status having avg_net_worth_in_millions > 200 - adding a foreign key constraint -
alter table digital_assets add constraint digital_assets_actor foreign key (actor_id) references actors(id);
Joins
- cross join - cartesian product of the rows of the two tables
- inner join - all rows of both the tables where the condition (called the join predicate) is satisfied
- left outer join - result of inner join + all rows of the left table, with null for the columns of the right table
- right outer join - result of inner join + all rows of the right table, with null for the columns of left table
- full outer join - result of inner join + all rows of the left table, with null for the columns of the right table + all rows of the right table, with null for the columns of the left table
- self join - using the same table on both sides of the join
- inner join example - assume digital_assets table contains social media links, where the asset_type is an enum containing twitter etc. and url is the link
select actors.first_name, actors.second_name, digital_assets.asset_type, digital_assets.url from actors inner join digital_assets on actors.id = digital_assets.actor_id;if the same column name is not there in the two tables, the “table.” prefix can be removed e.g.
first_namein place ofactors.first_name, though i prefer being explicit - the above query can be rewritten as below, with no performance impact
select actors.first_name, actors.second_name, digital_assets.asset_type, digital_assets.url from actors, digital_assets where actors.id = digital_assets.actor_id; - union clause - merely clubs results together, doesn’t join the tables. e.g. the following query will display a list of all actress names, followed by all male actor names
select concat(first_name, ' ', last_name) from actors where gender = 'female' union select concat(first_name, ' ', last_name) from actors where gender = 'male'note: duplicates are automatically removed since it is a “union”, which can be prevented using
union all - left outer join syntax (right join would have similar syntax, not discussed). e.g. in the below query, actors without social media handles would be displayed too, with the columns for
asset_typeandurlholding null -select actors.first_name, actors.second_name, digital_assets.asset_type, digital_assets.url from actors left outer join digital_assets on actors.id = digital_assets.actor_id; - natural join - syntactic sugar, no need to explicitly specify the columns to use for join, i won’t use it
Nested Queries
- nested queries are slower but sometimes the only way to write a query
- the following is an example of nested scalar query, since the nested query returns a single value. e.g. find all actors who had updated their digital assets most recently
select first_name from actors inner join digital_assets on digital_assets.actor_id = actors.id where digital_assets.last_updated = ( select max(digital_assets.last_updated) from digital_assets ); - e.g. find all actors who are on facebook
select * from actors where id in ( select actor_id from digital_assets where asset_type = 'facebook' ) - e.g. find actors who updated their social handles on their birthday
select actors.first_name from actors inner join digital_assets on actors.id = digital_assets.actor_id and actors.dob = digital_assets.last_updated - the following is an example of a nested query where it returns a collection of columns. the query returns the same results as the example as above
select first_name from actors where (id, dob) in (select actor_id, last_updated from digital_assets);
Correlated Queries
- the subquery references columns from the main query
- note: we can use the
existsoperator to check if the subquery returns any rows - e.g. find actors with their names in their twitter handles -
select actors.first_name from actors inner join digital_assets on actors.id = digital_assets.actor_id where digital_assets.url like concat('%', actors.first_name, '%') and digital_assets.asset_type = 'twitter' - the query returns the same results as the example as above
select first_name from actors where exists ( select * from digital_assets where digital_assets.actor_id = actors.id and digital_assets.url like concat('%', actors.first_name, '%') and digital_assets.asset_type = 'twitter' ) - difference between nested queries and correlated queries - in nested queries, the subquery runs first and then the main query runs. in correlated queries, the subquery runs for every row of the main query, and the subquery runs after the main query
Multi Table Operations
- multi table delete use case - delete related data from multiple tables
delete actors, digital_assets -- tables to delete rows from from actors, digital_assets where actors.id = digital_assets.actor_id and digital_assets.asset_type = 'twitter'we mention the tables to delete rows from, note how this isn’t required when deleting from one table
- we can similarly have multi table updates -
update actors inner join digital_assets on actors.id = digital_assets.actor_id set actors.first_name = upper(actors.first_name) where digital_assets.asset_type = 'facebook' - note: a subquery cannot have select for tables being updated or deleted in the outer query
- copy a table without the data and just the structure -
create table copy_of_actors like actors - insert data from one table into another -
insert into copy_of_actors(name) select first_name from actors
Views
- views can be created by combining multiple tables
- we can filter out rows and columns
- now, a complex query becomes a simple single table query
- we can create views from other views as well, and we can perform the same joins and filtering on views that we would otherwise perform on a table
- when we do
show tables, we see the views as well, we can see the type of table i.e. whether it is a normal table (also referred to as base table) or a view by using the commandshow full tables - e.g. of creating a view -
create view actors_twitter_accounts as select first_name, second_name, url from actors inner join digital_assets on actors.id = digitalassets.actor_id where asset_type = 'twitter' - views are basically like stored queries, so they get updated whenever the tables get updated
- we can use
create or replaceto either create a view or replace it if one already exists. e.g. for single actorscreate or replace view single_actors as select * from actors where marital_status = 'single'; - we can update or delete rows from the underlying base tables using views. however, there are conditions e.g. it shouldn’t have specific types of joins, group by statements or aggregation functions, etc.
insert into single_actors (first_name, second_name, dob, gender, marital_status, net_worth_in_millions) values ('charlize', 'theron', '1975-08-07', 'female', 'single', 130); - e.g. i try inserting a row into this view, which fails the filtering clause used to create the view
insert into single_actors (first_name, second_name, dob, gender, marital_status, net_worth_in_millions) values ('tom', 'hanks', '1956-07-09', 'male', 'married', 350); - now, since views can update their base tables, this went through and updated the table. however, since the view’s query filters out married actors, we don’t see the row in the view. we have essentially updated a row in a table through a view which will not be visible in the view. if this behavior is not desirable, we can use the check option while creating the view
create or replace view single_actors as select * from actors where marital_status = 'single' with check option; - now the insert statement for tom hanks will fail
- if we create views using other views, the check option can have scopes of local and cascade. local means that only the check option of the view being used for the update will be considered, while cascade looks at the check option of the views being used by this view itself as well
- we can drop views using
drop view single_actors
Triggers
- triggers are statements that get invoked when we perform an operation like insert, update or delete
- note: if we perform an operation like truncate which is equivalent to delete, triggers won’t be invoked
- triggers can be row level or statement level
- row level triggers are invoked once per row, e.g. if a statement updated 25 rows then it gets invoked 25 times, while statement level triggers are invoked once per statement
- triggers can be invoked at 6 phases - (before, after) * (insert, update, delete)
- e.g. of trigger -
delimiter ** create trigger net_worth_check before insert on actors for each row if new.net_worth_in_millions < 0 or new.net_worth_in_millions is null then set new.net_worth_in_millions = 0; end if; ** delimiter ; insert into actors (first_name, net_worth_in_millions) values ('tom', 350); insert into actors (first_name, net_worth_in_millions) values ('young', null); insert into actors (first_name, net_worth_in_millions) values ('old', -540); select * from actors; -- actors young and old will have net_worth_in_millions adjusted to 0 - show triggers -
show triggers; - drop triggers -
drop trigger if exists net_worth_check; - we can also include multiple statements by enclosing statements after
for each rowinside a begin-end block
Transactions
- we use transactions since we want either all the statements or none of them to go through
- there can be storage engines which don’t support transactions / apply locking using different methods
- irrespective of whether transactions are supported, databases should have some form of locking to disallow concurrent access from modifying the data. e.g. InnoDB supports row level locking so that multiple users can modify the data in the same table. this also makes it a little slower
- we can start and commit a transaction using -
start transaction; -- statements commit; - we can roll back a transaction using
start transaction; -- statements rollback;