Kafka
Setup
- note - environment should have java 8+ installed
- download the zip from here
- unzip it -
tar -xzf kafka_2.13-3.5.0.tgz - note - the 2.13… here is not the kafka, but the scala version?
Staring using Zookeeper
- in one terminal, start zookeeper -
zookeeper-server-start.sh ~/kafka_2.13-3.5.0/config/zookeeper.properties - in another terminal, start kafka -
kafka-server-start.sh ~/kafka_2.13-3.5.0/config/server.properties
Starting using Kraft
- generate a cluster uuid -
KAFKA_CLUSTER_ID="$(~/kafka_2.13-3.5.0/bin/kafka-storage.sh random-uuid)" - format log directories -
kafka-storage.sh format -t $KAFKA_CLUSTER_ID -c ~/kafka_2.13-3.5.0/config/kraft/server.properties - start kafka -
kafka-server-start.sh ~/kafka_2.13-3.5.0/config/kraft/server.properties
Concepts
- helps with system integrations. sources produce data into kafka, and targets consume from kafka
- distributed, resilient, fault tolerant
- created by linkedin, now maintained by ibm, cloudera, confluent, etc
- works with spark, flink, hadoop, etc
- a sequence of messages is called a data stream
- kafka topic - a particular stream of data
- a topic is identified by topic name
- topics support any kind of message format like json, avro, binary, etc
- we can produce data using kafka producers, and consume data using kafka consumers
- topics are split into partitions
- messages within a partition are ordered
- messages in a partition get an id called offset. note - so offsets are specific to a partition
- so, order is only guaranteed inside one partition
- offsets are not reused in a partition even if previous messages are deleted from it
- immutability - once data is written into a partition, it cannot be updated / deleted, we can just append (add) data to it
- my understanding - we basically interact with kafka producers and consumers in our code, and they internally do things like batching, where we provide network configuration, security parameters, etc
- producers can optionally send a key along with the message. this key can be a string, number, binary, etc
- if this key is null, then the message can end up in any partition
- if this key is not null, this key is hashed to produce the partition number. this partition number then determines the partition the message should go to. use case - e.g. we have a delivery service, where our trucks send its coordinates every 5 seconds. we should ensure that a truck sends its coordinates to the same partition to ensure ordering, therefore the truck can use its id as the kafka message key. messages with the same key end up in the same partition
- internally kafka partitioner determines the partition using murmur2 algorithm
- parts of a message - key, body, compression (e.g. gzip, snappy, etc or even none), headers (key value pairs) and a timestamp (can be set by the system or by the user)
- kafka message serializer - help in serializing our messages which are objects into bytes. e.g. if our key is an integer and our value is a string, kafka will use its inbuilt integer and string serializer respectively for this
- consumers - pull model i.e. consumers request for data from the brokers, and not the broker pushing data into the consumers
- consumers can deserialize using deserializers similar to serializers
- best practice - do not change serializer in the producer, since that will break the deserializers in the consumers. so, create a new topic instead and have the consumers to start pulling from this new topic
- consumers in kafka read as a consumer group
- consumers in a group read from exclusive partitions i.e. multiple consumers of the same group cannot read from the same partition
- so, if we have more consumers in a consumer group than the number of partitions, (number of consumers - number of partitions) consumers remain idle
- however, a consumer in a consumer group can read from multiple partitions (e.g. when number of partitions > number of consumers)
- of course consumers from different consumer groups can read from the same partition
- if suppose a consumer from a consumer group is removed, the partitions that consumer was responsible for is automatically distributed among the other members of that consumer group
- a consumer group id is used to help identify the consumers part of the same group
- consumer offset - consumers store the offsets they have read up till in a topic called __consumer_offsets periodically. this way, if they die and come back up, they can continue reading from the same position in the partition where they left off
- a kafka cluster has multiple kafka brokers. each broker is identified by an id
- each broker only contains some partitions of a topic - so data is distributed. understand the implication of this - this way, our topic is not limited to scale by the capability of only one worker node in our kafka cluster
- broker discovery mechanism - consumers do not need to connect to all brokers in advance. they only need to connect to one broker, and by that they are automatically able to connect to all brokers since on initiating connection with one broker, all metadata related to the other brokers, partitions, etc is sent
- topic replication factor - if a broker is down, another broker is still available to produce data to and receive data from. replication factor = how many copies i.e. how many brokers will have the same partition’s copy
- in sync replicas (isr) - all replica brokers that have caught up with the broker
- since there are multiple partitions, there is a leader among these partitions, and producers can only send data to this leader
- consumers by default only consume from the leader. so i think the replication factor only helps with disaster recovery in this case
- however, in newer versions, kafka consumers can read from replica brokers as well, if the replica broker is closer to them (e.g. we should have the consumer read from the isr in same az and not the leader / another isr in a different az to help reduce network latency and costs). this feature is called rack awareness, and for this to work,
rack.idon the broker should have the same value asclient.rackon the consumer - producer acknowledgements -
- acks = 0 means producer will not wait for acknowledgement
- acks = 1 means producer will wait for acknowledgements from leader. data can be lost if leader goes down unexpectedly before replication goes through to other brokers. it was the default earlier
- acks = all (or -1) means producer will wait for acknowledgement from all replicas along with the master as well. default kafka 3.x onwards
- this option goes hand in hand with the
min.insync.replicasoption, which states how many replicas should acknowledge the data. if its value is 1, it means that only the leader has to acknowledge the data - so, one ideal configuration to start with would be setting min isr to 2, acknowledgement mode to -1 and setting replication factor to be 3. this way, at least one replica and the leader have the write before the producer can consider the message successfully written into kafka
- this option goes hand in hand with the
- topic durability - if replication factor is m, and say we want isr to be n, then we can tolerate m - n brokers going down. so, for e.g. don’t over optimize i.e. if min in sync replicas are 3, (acknowledgement mode is all) and replication factor is 3, that means we cannot withstand any broker going down, which might be too much
- retries - note - this is producer retries not consumer, don’t confuse with concepts like dlq here 😅. retries here refer to transient failures like kafka saves the message but acks fail, required number of brokers (min insync replicas) are unavailable at the time so kafka cannot save the message, etc. focussing on the newer versions here -
- retries (
retries) are set to infinite (2147483647) by default. so, after the producer sends the message and if there is a failure for some of the transient reasons discussed above, the producer would again retry sending the message - idempotence (
enable.idempotence) is set to true by default. imagine that kafka was able to save the message i.e. write it to the replication factor number of partitions, but the ack failed. so, the producer thinks that some stuff have failed and will retry sending. so, since this property is set to true, kafka would know not to re add this message to the partitions, and would just try sending the ack again. this helps with exactly once semantics (and not duplicating thus resulting in at least once). now, from what i understood, it also helps with ordering. so, if for example the producer sends the first batch and kafka fails to commit it, when the second batch is received by kafka, kafka would throw an out of order exception to the producer. with this property, its almost like a sequence number is sent with each batch. this way, both ordering and exactly once semantics are ensured - max in flight requests (
max.in.flight.requests.per.connection) is set to 5 by default. this is basically how many concurrent requests producer will send without receiving the acknowledgements for them. after this number, if our application calls send on the producer, it will start blocking. this needed to be 1 in older versions to maintain ordering, but with idempotence now, it is enough to keep this <= 5 based on what we discussed above and this - delivery timeout (
delivery.timeout.ms) is set to 120000 i.e. 2 minutes by default. now retries is infinite does not mean producer would just keep retrying endlessly in case of failure, since the time it first sent the message, it would keep retrying until this timeout occurs. again remember that this retrying decision is being done by the producer which we write, so we can configure it in the properties
- retries (
- zookeeper - helps with managing multiple brokers. so, helps with issues like leader election, sending notifications to other brokers if a brokers goes down, etc
- kafka up to 2.x cannot work without zookeeper. however, kafka from 3.x can work without zookeeper using kraft, and kafka 4.x onwards will not use zookeeper at all
- zookeeper itself too runs in master slave mode, runs odd number of servers underneath
- because of this change of migrating away from zookeeper, we should not mention zookeeper configuration inside our connections, but only mention broker endpoints. this change can even be seen in the kafka cli etc, e.g. when running kafka-topics.sh, we do not specify the zookeeper endpoint. this way when we change from 3.x to 4.x, there would be slim to no change required from us
- understand how the offsets are associated to a consumer group on a per partition basis
- as we add / remove more consumers to a group, the existing consumers are notified of this and they accordingly adjust the partitions that they listen to
- when a new partition is added to a topic, this new partition also needs to be assigned to one of the consumers of a group subscribed to the topic
- partition rebalance - moving of partitions between consumers - can happen due to adding new partitions to the topic / adding or removing consumers in a group
- there are different strategies to partition rebalance (
partition.assignment.strategy) -- eager rebalance - all consumers give up their ownership i.e. the partition they were responsible for. then a fresh calculation is made and the consumers are randomly assigned the partitions again. issue - it might happen that an existing consumer now starts listening to a new partition. also, for albeit a brief period when the rebalancing is happening, there would be no consumers at all, this phenomenon where there are no consumers at all during a brief period is called stop the world event
- cooperative rebalance / incremental rebalance - process is uninterrupted for unaffected partitions, e.g. imagine consumer 1 was subscribed to partition 1, and consumer 2 was subscribed to partitions 2 and 3. if a new consumer is added, only for e.g. partition 3 would be reassigned to this new consumer, but data from partitions 1 and 2 continues flowing uninterrupted
- static group membership - by default, when a consumer leaves a group, the partition they owned is reassigned. we can specify a
group.instance.idwhich makes the consumer a static member. this way there is no rebalance untilsession.timeout.ms(heartbeat mechanism discussed later), so the consumer has this much time to be able to come back up, otherwise the partition would be rebalanced. use case - consumers for e.g. maintain a cache and this way, a rebuilding of that cache is not required by the new consumer. feels like without this property, the partition would be reassigned to another consumer and not wait for the session timeout? - quick question - how to implement a fan out pattern in kafka - do not assign the consumer group id / specify a different value for the consumer group id for each of your horizontally scaled instances - this way all the instances will receive the message
- producer compresses the batch of messages before sending it to the broker
- this helps with things like better utilization of disk on kafka, better throughput, etc
- compression can be specified at producer / topic level
- compression can be specified at producer level or the broker level as well using
compression.type-- producer - the default. use the compressed batch from the producer as is and write directly without recompression
- none - all batches are decompressed by the broker
- specify a type like lz4 explicitly. if the compression format is the same as done by the producer then store as is, else decompress and recompress using the specified format
- so, the summary of above according to my understanding is, leave compression type at broker level to be producer (it is the default), and set the compression type to be snappy or something at the producer config (default is none)
- batching settings - increasing batch sizes improves throughput, means lesser network calls, compression becomes more effective, etc. but of course it introduces latency for downstream consumers
linger.ms- how long the producer should wait before sending the message to kafka. default is 0batch.size- if the batch fills to this value beforelinger.msis over, send the batch. default is 16 kb
partitioner.class- in earlier versions of kafka, if we specify no key for our message, the messages are sent to partitions in round robin fashion using round robin partitioner. disadvantage - for e.g. remember batching happens at partition level, so this means we cannot utilize batching effectively, since there is a batch being created for every partition. sticky partitioner is the default in newer versions of kafka. this means that instead of round robbin, producer would fill one batch (untillinger.msorbatch.size) and then send to one partition. after this, a new batch is started. so we can leave this property untouched in newer versions- delivery semantics - this is for consumers
- at least once - default and usually preferred. commit offset after processing of message is over. if processing of message fails or imagine consumer crashes after receiving messages, message will be read again and reprocessed since the offset was not committed. so, the processing logic must be idempotent
- at most once - commit offset as soon as message is received. if processing of message fails or imagine that after receiving messages, the consumer crashes, messages will be lost and not read again. this case ensures a message would not be processed multiple times
- exactly once - this would only be possible if both source and sink is kafka. we use the transactional api in this case. e.g. when using kafka streams for transformations, we can use this
- to make our processing idempotent with at least once semantics, for a given message, we should add an id, e.g. imagine how we know for an object if it needs to be updated or created in the database based on its id property. otherwise, we can use kafka coordinates - every message will have a unique (topic + partition + offset) combination, so for e.g. we could generate an id like this -
<topic>_<partition>_<offset>(understand why a separator like _ is needed - otherwise there is no way to differentiate between partition 2 offset 22 and partition 22 offset 2) - offsets are committed after at least
auto.commit.interval.mstime has passed since us calling poll(). the default value of this is 5 seconds. my understanding - e.g. we poll every 7 seconds, and auto commit interval is 5 seconds. when the second poll is called, the first poll would be committed. however, if we poll every 5 seconds, and auto commit interval is 7 seconds, the first poll would be committed when the third poll is called - for staying inside at least once semantics, because of what was described above, our processing should be synchronous - before we call poll the next time, our current batch should have been successfully processed, so that if by chance the next poll has to commit, it can be sure that we have already successfully processed our current batch. in auto commit, commitAsync is called
- we can disable auto committing as well, and instead manually commit offsets using
consumer.commitSync()/consumer.commitAsync() - the auto offset reset (
auto.offset.reset) property defines how to consume from a topic if there is no initial offset i.e. a new consumer group has just started listening - the default is latest i.e. start consuming from the end of the partition. we can set it to earliest. my understanding - earliest corresponds to the--from-beginningflag in the cli for kafka console consumer - we can also reset consumer offsets. internally, feels like this might be possible since it is as simple as adding a message to the __consumer_offsets topic, due to the cleanup policy being compact? (discussed later)
- consumers send a heartbeat every
heartbeat.interval.msseconds (3 seconds by default), and if no heartbeats are received forsession.timeout.msseconds (45 seconds by default), the consumer is considered dead. this heartbeat related functionality is carried out by the heartbeat thread - if a new poll call is not made in
max.poll.interval.ms, the consumer is considered to have failed processing of that message. my understanding - this is important because all offset commits are done by newer poll calls for the previous polls? so maybe this way, kafka can know that for some reason, message processing has been stuck or has failed, and it has to re send the message for processing? - for replicating data across kafka clusters, e.g. if cluster is across regions, or for e.g. when we are hitting performance limits with one kafka cluster and need multiple kafka clusters, etc, we can use tools like mirror maker 2. replication can be active active (two way replication, e.g. data producers in multiple regions) or active passive (one way, e.g. for global resiliency)
- when we try to connect to kafka, kafka brokers have a setting called
advertise.listeners. this way, when the client tries connecting to the kafka broker, the broker returns this value and the client instead tries connecting using this value if the value it initially tried connecting using was different. e.g. imagine client tries connecting using a public ip, but the value returned by the broker usingadvertise.listenersis the private ip address - partition count - if we change the partition count suddenly, understand it would affect ordering of messages with same keys etc
- more partitions = more parallelism
- partitions should be usually 3 times the number of brokers, so 3 partitions per broker
- replication factor - if we change this, we increase load on our kafka custer, since there is more network calls etc involved for the replicas
- replication factor should be usually 3
- topic naming guide -
<message type>.<dataset name>.<data name>. for message type, all possible values are mentioned in the link, some common ones arequeuingfor classic use cases,etlfor cdc, etc. dataset name is like database name and data name is like table name. also use snake case - debezium uses kafka connectors and kafka ecosystem underneath, and helps do realtime cdc by using database’s transaction logs
- so, two common patterns with kafka -
- use applications like spark, flink, (or even kafka itself) etc to read from kafka and generate realtime analytics
- use kafka connect to write to s3, hdfs, etc from kafka and generate batch analytics from this
- kafka metrics - monitor a lot of things like how many under replicated partitions exist i.e. how many partitions have issues with in sync replicas
- we can enable in flight encryption ssl, authentication and authorization
- kafka has data retention for 7 days by default
- but until then, everything is internally in file formats, e.g. i tried poking around in the log.dir folder on my local i.e. inside /tmp/kraft-combined-logs/
- partitions are internally made up of segments
- so, there is one (the latest) active segment, and other segments can be consider obsolete
- a segment is closed means it is available for log cleanup - this helps delete obsolete data from the disk of kafka
- how to cleanup logs - there are two possible values for
cleanup.policyon a topic -compact(default for __consumer_offsets) anddelete(default for all user defined topics) - a segment is closed and a new one is started when either the
log.segment.bytessize is reached, or iflog.retention.hoursis reached - if we set cleanup policy to be compact - a new segment is created, and only the values for the latest keys for a topic is retained, and others are discarded. so e.g. segment 1 has value a for key x and value b for key y, and segment 2 has value c for key y, the newly created segment would have value a for key x and value c for key y. this behavior also makes sense for the consumer offsets topic if i think about it
- for very large messages, either tweak configuration parameters to increase maximum limits, or better, use something like sqs extended client of aws is possible
Example
program to read from a json file - each line in the file is a json object representing an invoice
import json
from kafka import KafkaProducer
class InvoicesProducer:
def __init__(self):
self.producer = None
self.topic = 'invoices'
self.client_id = 'shameek-laptop'
def initialize(self):
self.producer = KafkaProducer(
bootstrap_servers='kafka-383439a7-spark-streaming-56548.f.aivencloud.com:19202',
sasl_mechanism='SCRAM-SHA-256',
sasl_plain_username='avnadmin',
sasl_plain_password='<<plain-password>>',
security_protocol='SASL_SSL',
ssl_cafile='kafka-ca.pem',
api_version=(3, 7, 1)
)
def produce_invoices(self):
with open('data/invoices/invoices-1.json') as lines:
for line in lines:
invoice = json.loads(line)
store_id = invoice['StoreID']
self.producer.send(self.topic, key=store_id.encode('utf-8'), value=line.encode('utf-8'))
self.producer.flush()
if __name__ == '__main__':
invoices_producer = InvoicesProducer()
invoices_producer.initialize()
invoices_producer.produce_invoices()
RabbitMQ
- messaging systems -
- used for application to application communication
- they are near realtime - messages can be processed by consumers instantly
- helps establish a standard - both producers and consumers would have to obey this messaging system specifications, instead of each source having integration logic for each target
- rabbitmq features -
- rabbitmq is open source
- multiple instances can be deployed into a cluster for high availability
- web interface for management and monitoring
- built in user access control
- built in rest apis (mostly for diagnostic purposes but can be used for messaging, not recommended)
- running rabbitmq -
1
docker container run -d -p 5672:5672 -p 15672:15672 rabbitmq:3.13.1-management
- publisher / producer - sends message on the exchange
- subscriber / consumer - consumes message from the queues
- queue - the buffer tht stores messages before the consumers consume from this queue
- exchange - routes messages to the right queue
- routing key - the exchange uses this parameter of the messages to decide how to route it to the queues
- binding - link between exchanges and queues
- message durability - guarantees that messages survive server restarts and failures
- by default, everything is “transient” i.e. lost on rabbitmq server restarts!
- to ensure message durability, we need to set two parameters -
- mark queues as durable - we need to set this when creating queues
- use persistent delivery mode when publishing messages. spring does this by default for us
- rabbitmq also has two types of queues -
- “classic” - the default. has good performance, but cannot withstand node failure, since it is only present on the primary node
- “quorum” - replicated across different servers. maintains consistency using quorum
- rabbitmq can store messages either in memory or on disk
- the “default exchange” is used if we do not specify the exchange and just specify the routing key
rabbitTemplate.convertAndSend("example.rabbitmq", "hello world"); - some consumers -
@Component @Slf4j public class Consumer { @RabbitListener(queues = "example.rabbitmq") public void consume(String message) { log.info("consumed: [{}]", message); } } - assume our producer is faster than the consumer. using below, 3 threads are created, one for each consumer. this way, our slow consumers can keep up with the fast producer, without us having spun up additional instances of the consumer
@RabbitListener(queues = "example.rabbitmq", concurrency = "3") - spring rabbitmq uses jackson for serialization / deserialization of pojos
- a naming convention example - x.name for exchanges, q.name.sub_name for queues
- “fan out exchange” - implements the publish subscribe pattern - it broadcasts the message to all queues bound to it
- e.g. we have a direct exchange x.hr
- it has bindings for two queues - q.hr.marketing and q.hr.accounting
- when binding, the binding key can be empty
- similarly, when producing, the routing key can be empty
- now, any messages put on the exchange x.hr will flow to both the queues
- in the snippet below, we specify the exchange name. the routing key is ignored, hence it is set to an empty string
rabbitTemplate.convertAndSend("x.hr", "", employee);
- “direct exchange” - send messages to selective queues instead of broadcasting to all queues
- e.g. we have a direct exchange x.picture
- we have two queues - q.picture.image and q.picture.vector
- q.picture.image is bound using two binding keys to the exchange - png and jpg
- q.picture.vector is bound using one binding key to the exchange - svg
- now, when our routing key is png / jpg, it goes to the image queue
- when our routing key is svg, it goes to the vector queue
- so, exchange sends the message to queues where routing key = binding key
- note - if the routing key does not match any rule, the message would be discarded
- “topic exchange” -
- with direct exchange, we can only route messages using a single criteria - e.g. we only used image type above
- using topic exchange, we can route messages based on multiple criteria
- note about wildcards -
*can substitute for 1 word#can substitute for 0 or more words
- e.g. we have a topic exchange x.picture
- we can send images to different queues based on image size, image type, source of image, etc
- the producer will just produce the messages using routing keys like source.size.type, e.g. mobile.large.png, desktop.small.svg and so on
- e.g. we have queues for different purposes. e.g. we want an image queue like earlier. we can have binding keys of the form either
#.pngand#.jpgor*.*.pngand*.*.jpg - this is true decoupling - the producer just tells the kind of messages being published, while the consumer selectively decides the messages it wants to receive based on the binding key
- similarly, if we need a consumer to consume messages for all large svg, we would use
*.large.svg
- dead letter exchanges -
- in case of an error during consumption, spring will by default requeue the message
- we could be stuck in an infinite loop during this consumption and requeueing
- thus, we can use a “dead letter exchange” - the message after failure is forwarded to this dead letter exchange, which in turn forwards it to another queue depending on how we set the binding for this dead letter exchange
- then, from this special queue bound to the dead letter exchange, we can notify the consumers of the error
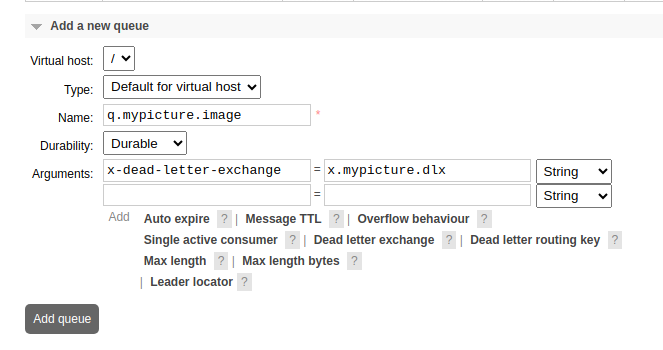
- configuring the dead letter exchange for a queue - just click on “Dead letter exchange ?” and enter the exchange name beside “x-dead-letter-exchange”
![dead letter exchange]()
- note - we can change the routing key of the queue when moving a message to the dead letter exchange
- note - we cannot throw any exception for this too work - we need to throw
AmqpRejectAndDontRequeueException
- time to live -
- if a message is present in a queue for longer than this timeout, it is declared “dead”
- the message from the actual queue would be moved into the dead letter exchange if configured after this timeout
- along with configuring dead letter exchange like we saw above, we can configure the queue with this ttl as well. it will then automatically move the messages to dead letter exchange in bot scenarios - timeouts and errors
- retry mechanism -
- some errors can be intermittent
- so, we might want to retry after x seconds for n times, before moving a message to dlq
- say we have three exchanges and three corresponding queues - work, wait and dead
- wait exchange is the dead letter exchange for work queue - when there is a failure in our consumer, the message is sent to wait exchange for “backoff” like functionality
- work exchange is the dead letter exchange for wait queue - when the message has been sat in wait queue for sometime, it is moved to work exchange for retrying
- finally, if our consumer notices that it has already tried reprocessing the message 3 times or so, it would move the message into the dead exchange which then goes into the dead queue
- we can get metadata around retires etc from rabbitmq headers
- retry mechanism in spring -
- on the above approach, there is a lot of manual code and configuration from our end
- using spring, we do not need all this logic - spring can automatically handle the retry and backoff for us, and it will move the failed messages to the dead letter exchange
- we only to ensure our queue has the right dead letter exchange configured on it
- apart from that, we can configure the retry logic (exponential backoff) like so -
spring.rabbitmq.listener.simple.retry.enabled=true spring.rabbitmq.listener.simple.retry.initial-interval=3s spring.rabbitmq.listener.simple.retry.max-interval=10s spring.rabbitmq.listener.simple.retry.max-attempts=5 spring.rabbitmq.listener.simple.retry.multiplier=2 - retry at 3s, then 6s (refer multiplier), and remaining 2 retries at 10s gaps
Kafka Connect
Introduction
- it helps perform “streaming integration” between numerous sources and targets like relation databases, messaging systems, no sql stores, object stores, cloud warehouses, etc
- we could have written kafka producer and consumer codes ourselves. issue - handling failures, retries, scaling elastically, data formats, etc all would have to be done by us
- miscellaneous advantages -
- kafka also acts as a “buffer” for the data, thus applying “back pressure” as needed
- once data is in kafka, we can stream it into multiple downstream targets. this is possible because kafka stores this data per entity in a different kafka topic
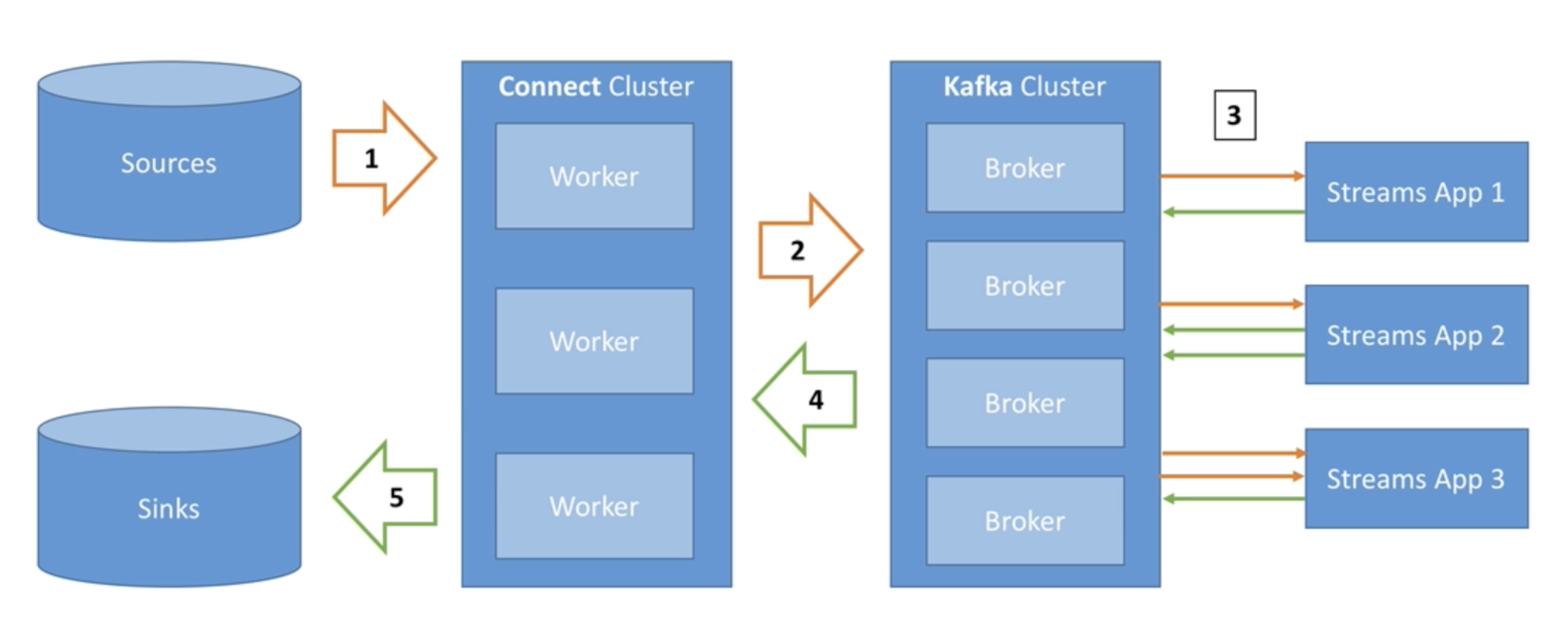
- some architectures -
- an application can just put elements into the kafka topic, while kafka connect can transfer this data from kafka to the sink. application -> kafka -> kafka connect -> database
- we can have several old applications putting data into their database at rest. kafka can use cdc and put this data into kafka in near realtime. sometimes, kafka can also act as the permanent system of record. so, new applications can directly read from kafka to service requests. applications -> database -> kafka connect -> kafka -> application
- we can look at the available connectors here
Where Kafka Connect Sits
- important - kafka connect sits between the source and broker / broker and target
- it runs in its own processes separate from the kafka brokers
- kafka connect only supports smts (discussed later), so optionally, for complex transformations like aggregations or joins to other topics, use ksqldb / kafka streams
Components
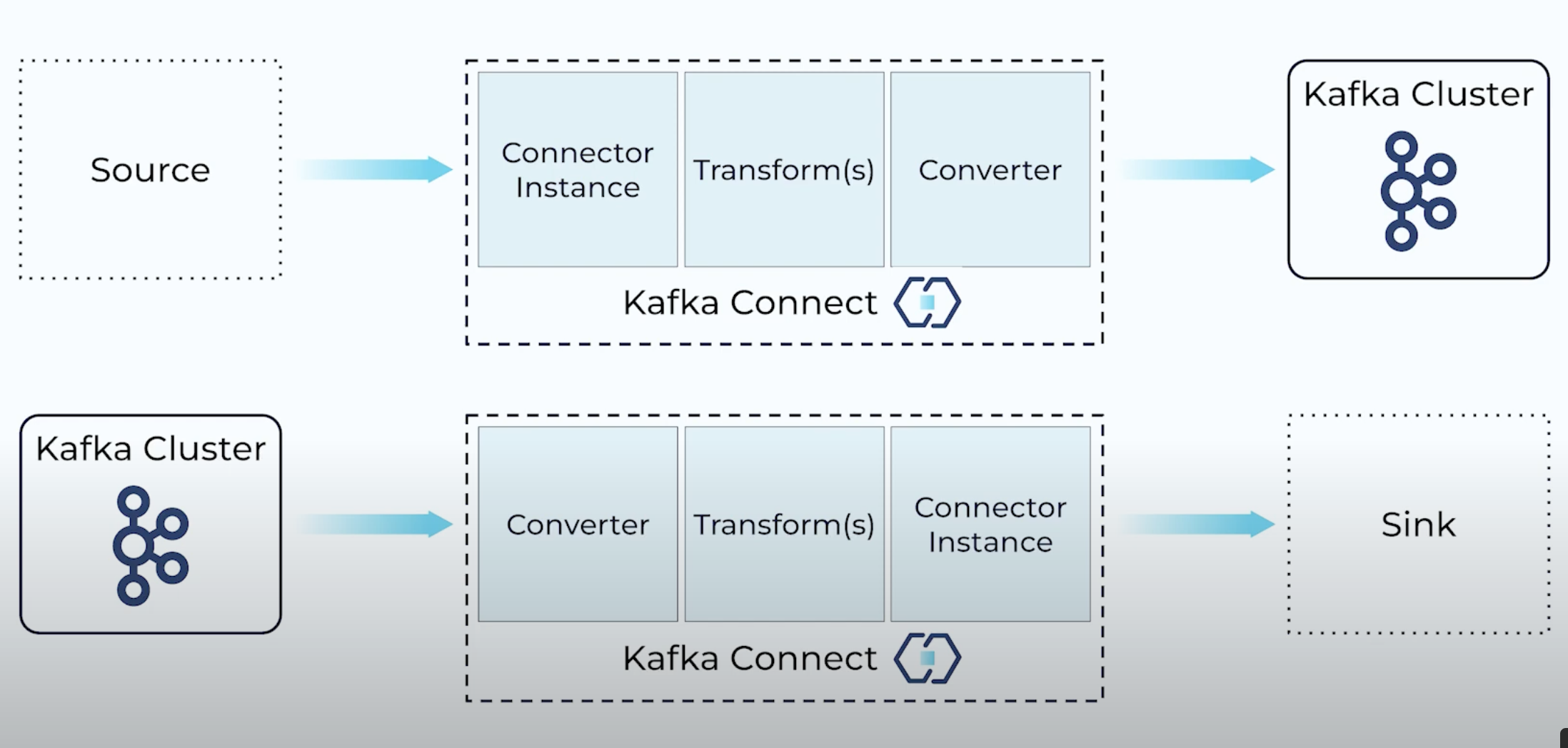
- kafka connect components - connector, transformers and converters
- “connector” - use “connector plugins” - reusable components that define how to capture data from source into kafka / how to move data from kafka to destination. these are the bridge between the external systems and kafka
- we can create connectors by making rest calls to the kafka connect api, or we can also manage connectors through ksqldb
- “converters” - also called serdeser - used for serialization when putting into kafka / deserialization when pulling out of kafka
- it supports “formats” like json, string, protobuf, etc
- if we use formats like avro, protobuf or json schemas, converters store these schemas in the “schema registries”
- optionally, after using such a format, we can enforce the schema to maintain data hygiene
- “transformers” - they are optional
- they are single message transformers or smts, and are used for things like dropping fields including pii, changing types, etc. we can have multiple such smts
- for more complex transformations, we should use ksqldb / kafka streams
- note - “connector” is “connector instance” in the diagram below
Workers and Tasks
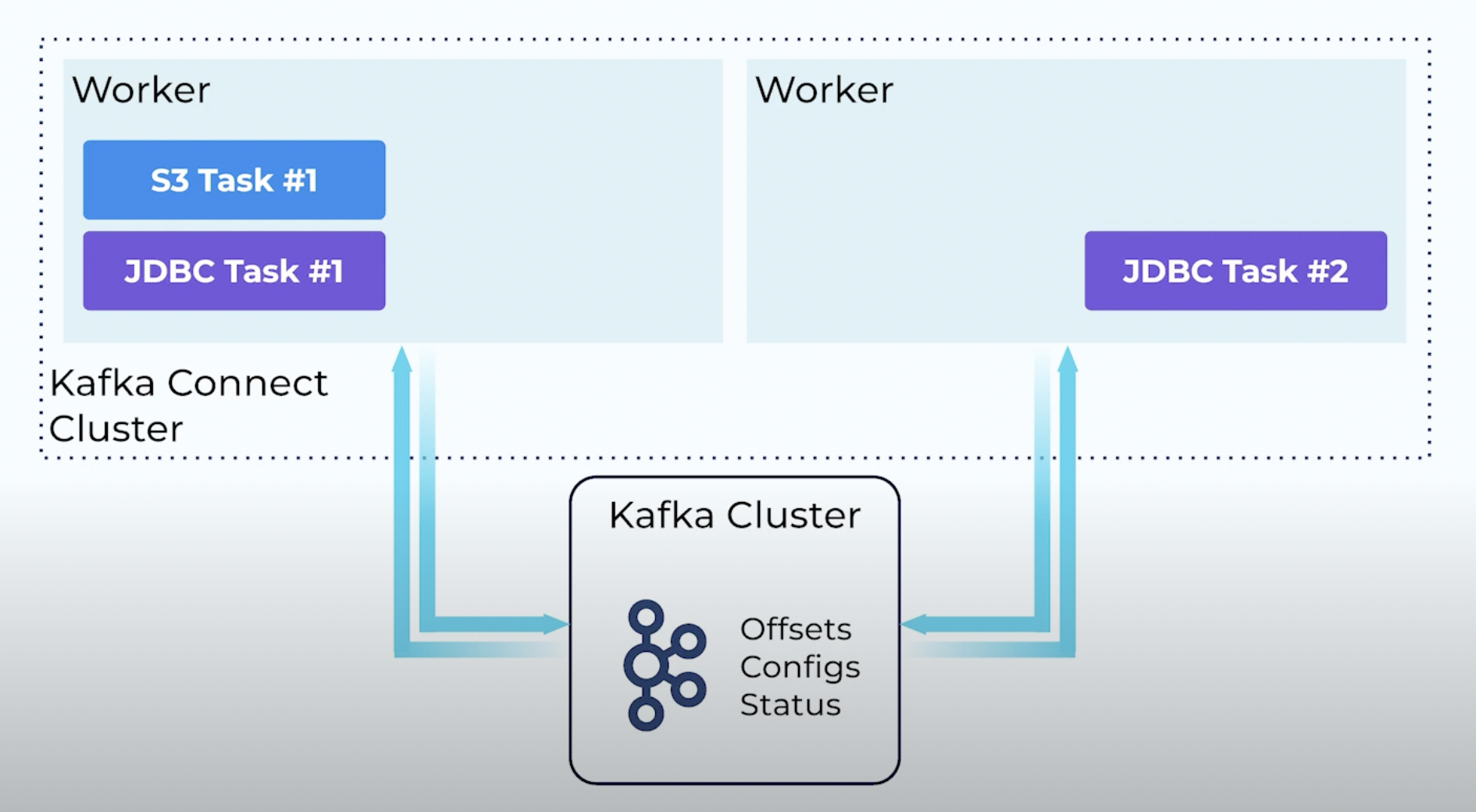
- kafka connect runs as multiple “workers”, and each of them is essentially a jvm process
- this jvm process is where the different “tasks” run
- a “task” is the component that performs the actual transfer of data to / from kafka
- so, a worker can run different “tasks” of different “connectors”
- but a task is scoped to a single “connector”
- tasks run on a single thread
- e.g. to support concurrency, e.g. the jdbc connector can create a task per table in the database, when writing to a sink, tasks can read from different partitions of the kafka topic at a time to parallelize the workload, etc
Deployment Modes
- kafka connect worker can run in “standalone” or “distributed” mode
- for standalone mode, only a single “worker” is used
- we use a configuration file, and it is bundled with the worker easily
- use case - “locality” - we can simply run kafka connect in standalone mode alongside the other main application process on a machine. it can then take care of transferring for e.g. files written by the main application to wherever we need
- when using distributed mode, we run multiple “workers” “per kafka connect cluster”
- we interact with the rest api of kafka connect for changing its configuration in distributed mode
- this config then gets stored inside “compacted” kafka topics
- this means additional workers that we spin up would simply have to read from these same kafka topics
![]()
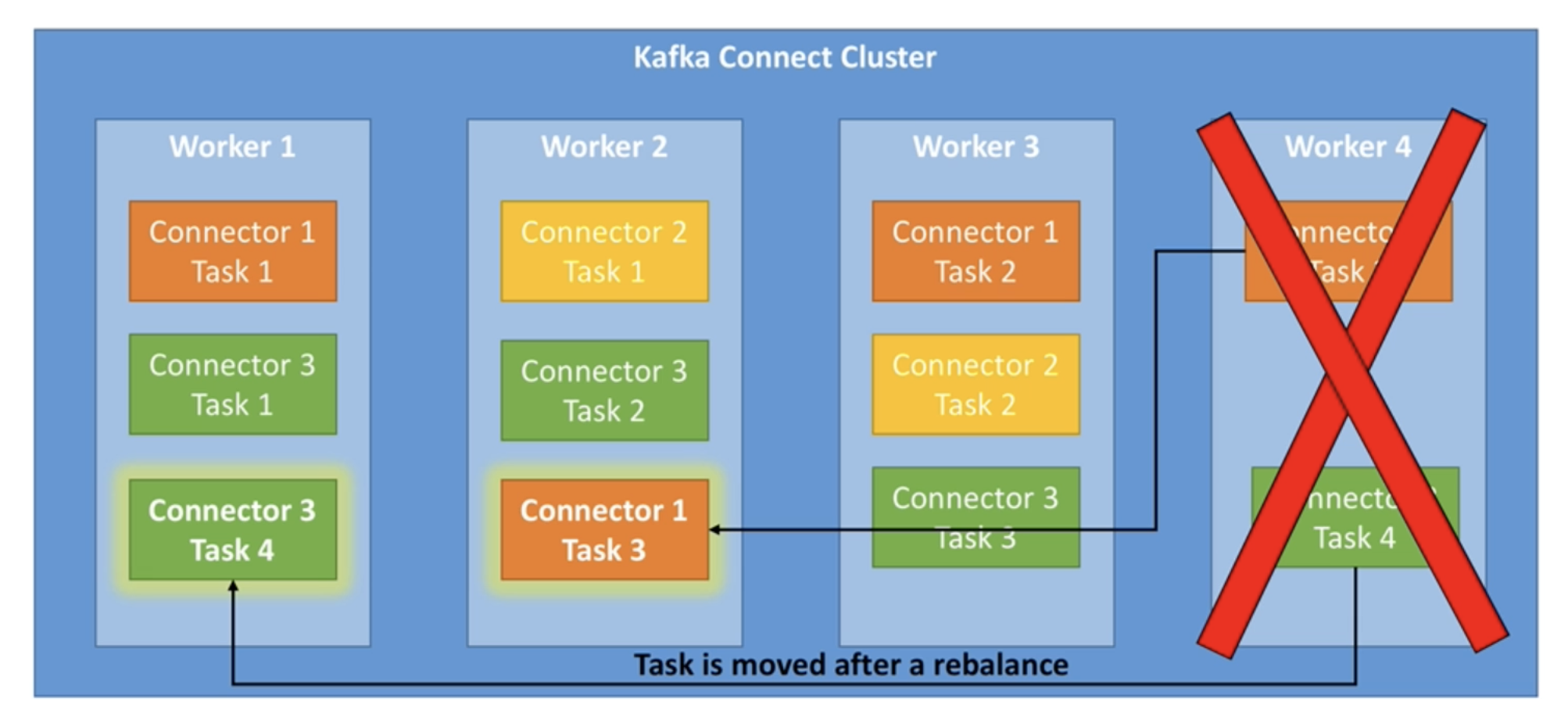
- in case of failures, workers can be easily added / removed, and rebalance i.e. redistribution of tasks happens automatically. e.g. refer the image below about what happens in case of failure of a worker -
![]()
- confluent cloud provides “managed connectors” i.e. we just provide the source / sink details, and confluent cloud takes care of the infra for us automatically
- “self managed kafka connect cluster” - we have to manage the deployment of kafka connect
Running on Local via Landoop
- for quick prototyping, we can run kafka connect via landoop / lensesio. it comes with kafka setup, some preinstalled connectors, etc -
services: kafka_connect: image: lensesio/fast-data-dev environment: - ADV_HOST=127.0.0.1 ports: - 9092:9092 - 8081:8081 - 8082:8082 - 8083:8083 - 2181:2181 - 3030:3030 - working with the ui -
- access landoop ui at http://localhost:3030/
- access kafka topics ui at http://localhost:3030/kafka-topics-ui/
- access kafka connect ui at http://localhost:3030/kafka-connect-ui/
- access logs at http://localhost:3030/logs/, e.g. look at connect-distributed.log
- now, for e.g. i wanted to add the twitter source connector to this which was not available by default
- i downloaded the connector from here under self hosted
then, i added the unzipped it and added the a volume section in the compose file like so -
volumes: - ./jcustenborder-kafka-connect-twitter-0.3.34:/connectors/jcustenborder-kafka-connect-twitter-0.3.34- now, the landoop kafka connect ui now starts showing this connector as an option as well
Source Connector Hands On
- create a new container using the image
- we use network mode as host, so now it can talk to the exposed ports above easily
- we also map the current directory to the host_volume directory on the container, to easily access files
docker container run \ --rm -it \ --net=host \ -v "$(pwd)":/host_volume \ lensesio/fast-data-dev bash - create a topic from inside this shell -
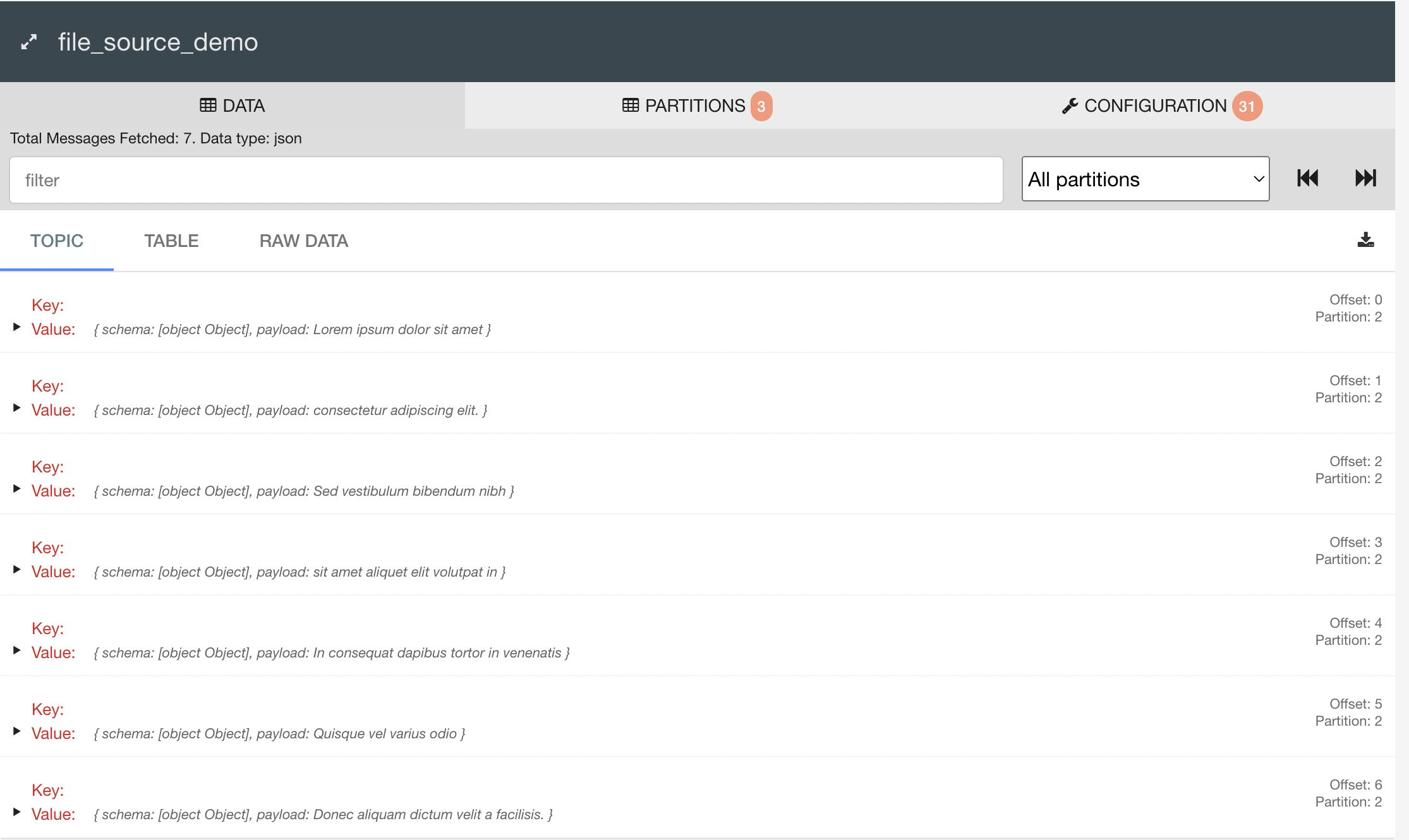
kafka-topics --create \ --topic file_source_demo \ --bootstrap-server localhost:9092 \ --partitions 3 \ --replication-factor 1 - now, we create a source connector. go to the kafka connect ui, click on new, and then under source, click on file
- we are asked to enter the properties. enter it like so -
name=FileStreamSourceConnector connector.class=org.apache.kafka.connect.file.FileStreamSourceConnector file=file_source.txt tasks.max=1 topic=file_source_demo key.converter=org.apache.kafka.connect.json.JsonConverter value.converter=org.apache.kafka.connect.json.JsonConverter - now, we enter the actual landoop container -
docker container exec -it personal-kafka_connect-1 /bin/bash - we create the file file_source.txt (
touch file_source.txt) and enter some lines in it (cat>>file_source.txt) - open the kafka topic ui in a new tab, and see a new record in the topic for each line in the file
![]()
- sink connector would work pretty much the same way with some additional considerations -
- how to add data - whether we should simply insert it or upsert it
- the primary key to use if for e.g. upserting records
- whether tables in the sink should be automatically created (new table) and evolved (schema changes)
SMT Hands On
- here, i am using the datagen source connector, which can easily produce mock data - i am specifying it to produce orders mock data via the quickstart field, into the orders topic
- i am specifying two smts - to cast values of fields and to format timestamp fields
name=DatagenConnector
connector.class=io.confluent.kafka.connect.datagen.DatagenConnector
tasks.max=1
kafka.topic=orders
quickstart=orders
transforms=castValues,tsConverter
transforms.castValues.type=org.apache.kafka.connect.transforms.Cast$Value
transforms.castValues.spec=orderid:string,orderunits:int32
transforms.tsConverter.type=org.apache.kafka.connect.transforms.TimestampConverter$Value
transforms.tsConverter.target.type=string
transforms.tsConverter.field=ordertime
transforms.tsConverter.format=yyyy-MM-dd
Rest API
- refer the documentation here
- view the available connectors -
curl -s localhost:8083/connector-plugins | jq - view the running connector -
curl -s localhost:8083/connectors | jq - get the tasks for a connector -
curl -s localhost:8083/connectors/logs-broker/tasks | jq
Running Using Compose
- the base image used by confluent -
confluentinc/cp-kafka-connect - we can add the extra connect plugins / jars on top of this base image, and create a new custom image
- the format is
owner/component:version, so for e.g. if i want to add the snowflake sink connector, i would probably dosnowflakeinc/snowflake-kafka-connector:2.4.1 - example dockerfile for a custom kafka connect image
FROM confluentinc/cp-kafka-connect RUN confluent-hub install --no-prompt confluentinc/kafka-connect-datagen:latest RUN confluent-hub install --no-prompt confluentinc/kafka-connect-elasticsearch:latest CMD [ "/etc/confluent/docker/run" ] - now, when spinning up “workers” using this image, we need to configure environment variables, e.g. -
- all worker nodes with the same “group id” join the same kafka connect cluster
- the kafka topic where all of the configuration gets stored
- the kafka broker and schema registry urls
Resiliency
- monitoring kafka connect instances - two main ways
- if we are inside confluent cloud, “confluent metrics api” can be used to export metrics to for e.g. new relic
- otherwise, jmx and rest metrics are exposed by kafka connect, which can then be consumed
- kafka connect supports several error handling patterns like “fail fast”, “dead letter queue”, “silently ignore”, etc
- e.g. when using a dead letter queue, the failed messages would be routed to a separate kafka topic
- we can then inspect its headers to inspect the cause for the error etc
- example scenario -
- assume source kafka connector is changed to serialize using avro instead of json
- however, our sink kafka connector is trying to deserialize them using json
- the failed messages serialized using avro would be sent to the dead letter queue, since the “converter” cannot deserialize them
- now, we can add a separate sink connector configuration to ingest from the dead letter queue using the avro deserializer and write to the sink
- some tips to debug -
- number of messages in dead letter queue and inspect the headers of these messages
- make the connector status rest api call to the kafka connect cluster - it will show the overall status of the connector and its individual tasks
curl -s "http://localhost:8083/connectors/jdbc-sink/status" | jq '.tasks[0].trace' | sed 's/\\n/\n/g; s/\\t/\t/g' - we can change the logging level of some connectors dynamically i.e. without restarting the workers