Object Oriented Programming
Basics
- a java program can have any number of classes. the classes can have any name and the java program can have any name
- however, only one public class is allowed in a java program
- the name of both the public class and the java program should be the same
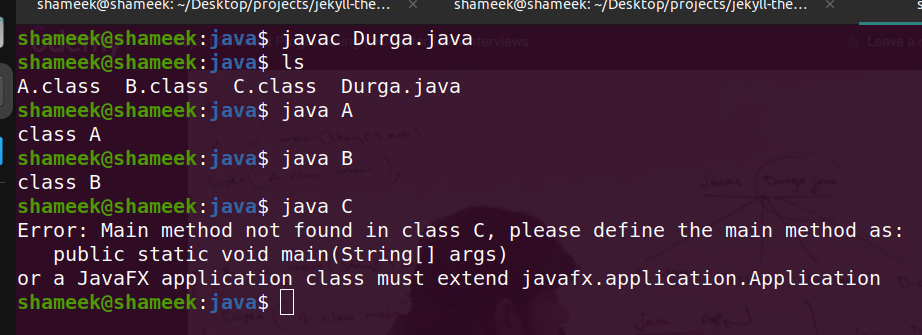
- when we compile a class using
javac Durga.java, the number of class files generated = number of classes present in that programclass A { public static void main(String args[]) { System.out.println("class A"); } } class B { public static void main(String args[]) { System.out.println("class B"); } } class C { } - output of above program -
![java main output]()
- three pillars of object oriented programming
- encapsulation - helps with security and abstraction
- examples - data hiding (access modifiers), packages
- inheritance - helps with reusability and abstraction
- polymorphism - helps with flexibility
- compile time examples - overloading, method hiding, variable hiding / shadowing
- runtime examples - overriding
- encapsulation - helps with security and abstraction
Import Statements / Package
- two ways for using classes from libraries -
- fully qualified name of the class
- import statement at the top - preferred
- two kinds of import statements -
- explicit import -
import java.util.ArrayList;- preferred - implicit import -
import java.util.*;- note - implicit import does not include sub packages
- explicit import -
- by default -
- all classes under
java.langpackage are available and need not be imported - all classes under the same package as the package of the current class need not be imported
- all classes under
- package - group of related java programs
- different packages can have the same java program, e.g.
java.util.Dateandjava.sql.Date - universally accepted naming convention for package naming in java - reverse of domain name
- if we write the following program -
package com.learning.java; class Test { public static void main(String args[]) { System.out.println("hello world"); } } - and try compiling using
javac Test.java, it compiles. but when i tried runningjava Test.java, it failedError: Could not find or load main class Test Caused by: java.lang.NoClassDefFoundError: Test (wrong name: com/learning/java/Test) - so we should actually compile using -
javac -d . Test.java - this generates the entire directory structure of com/learning/java in the current working directory and places the Test.class there
- we can now run it using
java com.learning.java.Test - packages help with implementing encapsulation - the entire complexity / functionality is viewed as one unit residing inside a package
Class and Method Access Modifiers
- classes have two different access modifiers -
publicand<<default>>- default classes are only accessible from only within the package
- public classes can be accessed from anywhere outside the package as well
- for inner class, apart from
abstract,final,publicand<<default>>, we can also havestatic,privateandprotectedmodifiers - members have four different access modifiers -
- public - access method from anywhere, inside or outside package
- default - can be accessed from inside package only, not outside the package
- private - can only be accessed from within the same class, not outside the class
- protected - can be accessed from anywhere inside package, and from subclasses if outside package as well
- small note - if accessing protected members from inside subclass but from outside package, only subclass reference can be used, not superclass (i.e. even polymorphism is not allowed)
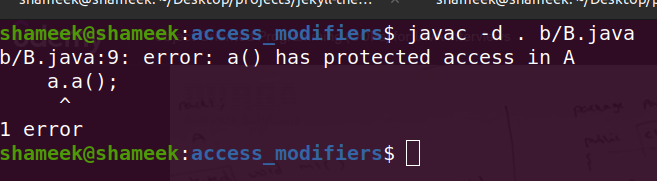
- protected example -
- a/A.java -
package a; public class A { protected void a() { System.out.println("from a"); } } - b/B.java -
package b; import a.A; class B extends A { public static void main(String[] args) { A a = new A(); a.a(); } } - output -
![protected caveat]()
- solution - change to -
B b = new B(); b.a();
- a/A.java -
therefore, summary in tabular form -
visibility public protected default private same class ✅ ✅ ✅ ✅ subclass same package ✅ ✅ ✅ non subclass same package ✅ ✅ ✅ subclass different package ✅ ✅ (subclass reference only) non subclass different package ✅ - note - think about member visibility only when class is visible first (recall default vs public)
- access modifiers also help achieve encapsulation - interact with data members via exposed methods, not directly
Abstract Classes And Interfaces
abstractmodifier is applicable for both methods and classes- abstract method is used when we do not know about the implementation of the class upfront. e.g. Vehicle class can have an abstract method
getNumberOfWheels. syntax -public abstract Integer getNumberOfWheels(); - if a class contains even one abstract method, it would have to be declared as abstract as well
- if a class is
abstract, instantiation is not possible for the class - also, if for e.g. we would not like for it to be possible to instantiate a class, we can declare it as abstract even if it does not have abstract methods
- subclasses are responsible to provide the implementation of the abstract methods of super class
- we can have multiple levels of nesting for abstract classes as well - abstract class Vehicle -> abstract class Car -> class RangeRover
- interface methods are
publicandabstractwithout us specifying anything - so, when overriding in subclass, “method should be public”
- when implementing an interface -
- either override all the methods of the interface
- or make the class itself abstract
- code example -
interface I { void m1(); void m2(); } abstract class A implements I { public void m1() { } } - abstract variables are not supported - so only one kind of member i.e. method is allowed for abstract, not variable
- so why use abstract classes and interfaces -
- mandating a structure for an implementation - “mandates” subclasses to provide implementation, else there will be compile time error
- acting as a specification / contract - e.g. we write servlet api compliant code, but that same code can run on different vendors like jetty, tomcat, weblogic, resin, oracle http server, etc which are all implementations of the same servlet api. same applies for jdbc and the different sql compliant drivers as well.
- abstraction - client will not know / need not care about the internal implementation
- note - all variables inside an interface are public static final, so they need to be initialized then and there. no instance variables can be created for an interface
Inheritance
- inheritance helps use is a relationship
- we use
extendsto implement this - members of the superclass are inherited by the subclass
- so, subclass can use members of the superclass
- the other way around does not hold i.e. superclass reference cannot use members of subclass
- all classes are implicitly subclasses of
Object - main advantage of inheritance - superclass will contain common functionality, thus helping us avoid duplication of logic in subclasses
- types of inheritance -
- single inheritance - one superclass and one subclass. supported in java
- multilevel inheritance - one superclass has one subclass, and that subclass again acts as a superclass for yet another subclass. this too is supported in java
- multiple inheritance - multiple superclasses, one subclass. not supported in java for classes, but supported via interfaces
class C1 extends C2, C3 {} // compilation error interface I1 extends I2, I3 {} // works class C1 implements I1, I2 {} // works - hierarchical inheritance - one superclass, multiple subclasses
- hybrid inheritance - combination of multiple types of inheritance
- inheritance example -
![inheritance]()
- confusion cleared - we just said every class extends object. if a class C1 extends another class C2, it is extending both C2 and Object. then isn’t this multiple inheritance? why did we say java does not allow multiple inheritance?
- when we do not extend any class, we extend Object implicitly
- when we extend a different class, we do not extend Object directly. so, the root class in the chain which does not have any explicit superclass extends Object implicitly. so it is basically multi level inheritance and not multiple inheritance which helps extend this subclass extend Object indirectly
- note -
finalclass cannot have a subclass

Polymorphism - Overloading
- method signature - method name + argument types
- in java, return type is not a part of method signature
- when resolving method calls, method signature is what gets used
- so, it is a compile time error if we try to add two methods with same signature, even if they have different return types
- overloading - when a class has multiple method with same names but different argument types
- advantage - same method is being used for multiple implementations
- static polymorphism / compile time polymorphism / early binding - in case of overloading, the decision around which variation of method to use is made at compile time
- example -
class Overloader { public void printer(int x) { System.out.println("printing an integer: " + x); } public void printer(String x) { System.out.println("printing a string: " + x); } } public class Overloading { public static void main(String[] args) { Overloader overloader = new Overloader(); overloader.printer(1); // printing an integer: 1 overloader.printer("hello"); // printing a string: hello } } - automatic promotion + overloading in java - if when overloading, an exact match is not found for a primitive type, java promotes to the next available primitive type using the following rules -
- byte -> short -> int -> long -> float -> double
- char -> int -> …
- so, if refer the example above - there is no overloaded method for char. so, we jump to the next type as follows -
overloader.printer('a'); // printing an integer: 97 - if no promotion is possible, we get a compile time error -
overloader.printer(10.5); // Overloading.java:19: error: no suitable method found for printer(double) - if there is a clash during overloading for superclass vs subclass, subclass gets priority
- e.g.
nullcan be used both forObjectandString. so, if a method is overloaded for both of them and we pass itnull, it will call theStringimplementation - if there is clash during overloading for two classes which are independent, compiler throws an ambiguous exception
- e.g.
nullcan be used both forStringandStringBuffer. so, if a method is overloaded for both of them and we pass itnull, it will throw an exceptionoverloader.printer(null); // Overloading.java:24: error: reference to printer is ambiguous - since method overloading is compile time, the decision is influenced by the reference, not by the instance
- e.g. if i do
Object x = new String("s"), and a method is overloaded for bothStringandObject, the object version would be called, since the decision is made by the type of reference - if i have two variations -m1(Object obj)andm1(String str), them1(Object obj)variation would be called
Polymorphism - Overriding
- superclass reference can hold subclass instance
- the other way around does not hold i.e. subclass reference can not hold superclass instance
- overriding - subclass redefines method of superclass
- variations -
- superclass reference pointing to superclass instance - superclass method would be called
- subclass reference pointing to subclass instance - subclass method would be called
- superclass reference pointing to subclass instance - subclass method would be called
- the third variation is what interests us - compiler only checks if superclass has that method defined
- the method is called actually called on the instance during execution
- dynamic polymorphism / runtime polymorphism / late binding - in case of overriding, the decision around which variation of method to use is made at runtime
- co variant - when overriding, we can return subclass type of what superclass returns
class Parent { public Object m1() { return null; } } class Child extends Parent { public String m1() { return "hello world"; } } class CoVariant { public static void main(String[] args) { Parent p = new Child(); System.out.println("covariant response = " + p.m1()); // covariant response = hello world } } - if superclass method is final, we cannot override the method and we get a compile time error
- if superclass method is non final, we can override the method, and can also make it final in the subclass
- if method is private, there is no concept of overriding, since it is treated like an internal method. so, even if we redefine the method with the same name in the subclass, the compiler would not complain
- access modifiers + overriding - when overriding, we cannot reduce the scope, but we can increase the scope
class Parent { public String m1() { return "from parent"; } } class Child extends Parent { protected String m1() { return "from child"; } } - output -
attempting to assign weaker access privileges; was public - so, conclusion for access modifiers and overriding - for
privatemethods, overriding concept is not applicable, for others -- superclass -
public, subclass can be -public - superclass -
protected, subclass can be -protected,public - superclass -
default, subclass can be -default,protected,public
- superclass -
- exception - below is of course only applicable for checked exceptions and not unchecked exceptions. below will make sense automatically as well if we think about
Parent p = new Child(); p.m1();- if subclass does not throw an exception, superclass can or cannot throw an exception
- if subclass throws an exception, superclass should throw a superclass of exception as well
- superclass
public static void m1(), subclass -public void m1()- compile time error - subclass
public void m1(), superclass -public static void m1()- compile time error - subclass
public static void m1(), superclass -public static void m1()- works, but it is not overriding. it is method hiding. this resolution is compile time, happens by reference, and the superclass version is calledclass Parent { public static String m1() { return "hello from parent"; } } class Child extends Parent { public static String m1() { return "hello from child"; } } class MethodHiding { public static void main(String[] args) { Parent p = new Child(); System.out.println("parent reference, child object responds with = " + p.m1()); } } - output -
parent reference, child object responds with = hello from parent - conclusion - method hiding is also example of compile time polymorphism / static polymorphism / early binding just like overloading
- variable hiding / shadowing - there is no concept of overriding for variable members. so, if we redefine the variable in the child class as well, resolution happens like in method hiding
class Parent { String s = "parent"; } class Child extends Parent { String s = "child"; } class VariableShadowing { public static void main(String[] args) { Parent p = new Child(); System.out.println(p.s); // prints 'parent' } } - TODO: add double dispatch?
Object Type Casting
- syntax -
A b = (C) d - three checks - 2 compile time, 1 runtime
- compile time check 1 - C and d should be somehow related. either should be superclass of other
- passes compilation -
Object o = new String("hello world"); StringBuffer sb = (StringBuffer) o; - fails compilation -
incompatible types: String cannot be converted to StringBufferString str = new String("hello world"); StringBuffer sb = (StringBuffer) str;
- passes compilation -
- compile time check 2 - obvious - C should be subclass of A or same as A
- passes compilation -
Object o = new String("hello world"); StringBuffer sb = (StringBuffer) o; - fails compilation -
incompatible types: StringBuffer cannot be converted to StringObject o = new String("hello world"); String s = (StringBuffer) o;
- passes compilation -
- runtime check 1 - actual instance d should be subclass of C or same as C. understand how this is different from compile time check 1 - there, we were checking if whatever reference is used for d, that should be somehow related to C. here however, we check if the actual runtime object that d holds is a subclass of C or same as C
- passes runtime -
Object o = new String("hello world"); String s = (String) o; - fails runtime -
ClassCastException: class java.lang.String cannot be cast to class java.lang.StringBufferObject o = new String("hello world"); StringBuffer sb = (StringBuffer) o;
- passes runtime -
Constructors
- constructor helps with initialization
newkeyword helps with instantiation- for constructor, method name should be same as the name of class
- only applicable modifiers for constructors are access modifiers
- use case - make the constructor
private. now, an object for the class can only be created from inside the class. this can help us for e.g. implement the singleton pattern - if we do not add any constructor for a class, the compiler adds the default no args constructor for us automatically
- note - this default no args constructor is added for abstract classes as well
- first line in our constructor should always be calls to
super()orthis(). otherwise, exceptions like below are thrownerror: call to super must be first statement in constructorerror: call to this must be first statement in constructor
- if we do not add the super call ourselves, the compiler will automatically add
super()for us - note - this automatic adding of super happens for both constructors written by us and inside the default no args constructor
- convoluted example -
- our code -
class Test { Test(int i) { this(); } Test() { } } - what compiler generates
class Test { Test(int i) { this(); } Test() { super(); } }
- our code -
- when we have code like below, we get a compilation error because when the compiler generates
super()automatically, it is not enough, since the superclass has only one constructor - the one we manually wrote. it requires an argument, which the compiler is not capable of defaultingclass Parent { Parent(int i) {} } class Child extends Parent { } - error -
Test.java:5: error: constructor Parent in class Parent cannot be applied to given types; class Child extends Parent { ^ required: int found: no arguments reason: actual and formal argument lists differ in length 1 error - so, conclusion - we can only use either
super()orthis()and that too only in the first line of the constructor super()orthis()can only be called inside a constructor and not inside any other methodthisandsuperkeywords can also be used to reference instance variables- note -
thisandsuperare always related to an instance, so they cannot be used insidestaticmethods - my doubt - how to handle variable hiding / shadowing for static variables if super is not allowed? solution - maybe use class prefix instead of super?
- constructor + overloading is a common pattern. we then can use
this()inside them to call each other with default values for missing arguments - a constructor can throw exceptions
- however, if superclass constructor throws an exception, the subclass constructor should throw the same exception or superclass exception of that exception. this is different from overriding, because here, the problem is the call to super because of which subclass has to throw an exception. it is not a superclass reference for a subclass instance. note that we cannot wrap with try catch, since super or this should be the first call
Strings
- vvimp - string is immutable, string buffer (or builder) objects are mutable
class Introduction { public static void main(String[] args) { String s = new String("Durga"); s.concat(" Software"); System.out.println(s); // Durga StringBuffer sb = new StringBuffer("Durga"); sb.append(" Software"); System.out.println(sb); // Durga Software } } ==is for reference comparison. by default,equalsinObject/ custom classes work like==- sometimes, classes can override this method, e.g.
Stringclass below overrides it for content comparison, whileStringBufferdoes notclass Equality { public static void main(String[] args) { String s1 = new String("durga"); String s2 = new String("durga"); System.out.println(s1 == s2); // false System.out.println(s1.equals(s2)); // true StringBuffer sb1 = new StringBuffer("durga"); StringBuffer sb2 = new StringBuffer("durga"); System.out.println(sb1 == sb2); // false System.out.println(sb1.equals(sb2)); // false } } - heap is used for storing objects. string objects can be created when we use
new String(),str.concat("suffix"), etc - scp (string constant pool) is used for storing string literals. java stores them in the hopes of reusing them later
- note - scp a section in the heap itself, maybe it is present in a different location when compared to where java objects are stored
- while objects in heap are eligible for gc (garbage collection), objects in scp are not, because java internally maintains references to the string literals stored in scp
- deeper understanding - scp is used for storing string literals. if i do
str.concat("suffix"), suffix would be stored in scp, not concatenated result of str and suffix. the concatenated result will however be stored in heap - so, it almost feels like that albeit in heap, scp is more of a compile time feature, while string objects are a runtime feature
- 2 in heap - (s1, String(“durga”)), (s2, String(“durga”)) and 1 in scp - “durga”. s3 and s4 point to scp itself, while s1 and s2 point to both heap and scp. note how despite having the same string 4 times, it was stored only once in scp
String s1 = new String("durga"); String s2 = new String("durga"); String s3 = "durga"; String s4 = "durga"; - so, my understanding - whenever we have something in double quotes specified manually, all of that goes into the scp, while all other string objects created for e.g. manually using
new String...etc go into the heap - 3 in heap, out of which 1st and 2nd are eligible for gc - (,String(“durga”)), (,String(“durga software”)), (s, String(“durga software solutions”)) and 3 in scp - “durga”, “ software”, “ solutions” -
String s = new String("durga"); s.concat(" software"); s = s.concat(" solutions") - in below examples, we compare equality using
==and notequals, maybe because equals should anyway do content comparison, but here we see which references point to the same object - equality of string literals - (equals compares reference and if not same, contents, while == just compares reference, and that evaluates to true since sl1 and sl2 are both pointing to the same object inside scp)
String sl1 = "durga"; String sl2 = "durga"; System.out.println(sl1 == sl2); // true - concatenation for string literals can happen at compile time as well, which is why slc1 and slc2 point to the same object stored in the scp. this is probably happening due to optimizations that are performed on instructions
String slc1 = "durga software"; String slc2 = "durga " + "software"; System.out.println(slc1 == slc2); // true - here, str2 is created at runtime, so str2 points to string object in heap while str3 points to string literal in scp. str2 does not point to a corresponding object in scp in this case
String str1 = "durga"; String str2 = str1 + " software"; String str3 = "durga software"; System.out.println(str2 == str3); // false - here, both strf2 and strf3 are created at compile time hence scp itself, because final variables would be replaced at compile time. understand how this behavior changed when compared to the example above, just by adding the
finalkeywordfinal String strf1 = "durga"; String strf2 = strf1 + " software"; String strf3 = "durga software"; System.out.println(strf2 == strf3); // true - the main advantage of scp - if a string is used multiple times, its instance need not be managed / tracked separately multiple times
- basically, jvm maintains a reference to strings in scp, so that there is no garbage collection happening there
- also, strings in scp cannot be mutated - when we make changes, new objects are stored in heap / new strings are stored in scp
- string buffers do not work like strings - string buffers do not use concepts like scp etc - so it is mutable - there is no referencing to same object in scp like concepts in string buffer
- in strings,
concatand+both do the same thing - other important methods in strings -
equalsIgnoreCase(),charAt(),length(),isEmpty(),substring(),replace()(replace a certain character),indexOf(),lastIndexOf(),toLowerCase(),toUpperCase(),trim() - string buffer - string is not meant for string content that can change frequently
- strings are immutable - for every change, a new object is created
- this is why we need string buffer. all changes we make happen on the same object
- since string buffer is mutable, it has two concepts -
capacityandlength.capacitydetermines how many characters the string buffer can hold, whilelengthgives the current number of characters the string buffer has - when we run out of space, memory is doubled, a new object is created and all the existing characters are copied
- other important methods in string buffer -
capacity()(get the current capacity),setCharAt(),append()(works with most primitive etc types),insert()(insert a string at a specific position),delete()(delete substring from specified positions),reverse()(reverse contents of string buffer),ensureCapacity()(increase capacity to specified capacity upfront) - note - all methods inside string buffer are synchronized - run
javap java.lang.StringBufferin terminal to view the profile of string bufferpublic synchronized int length(); public synchronized int capacity(); public synchronized void setCharAt(int, char); // and so on... - so, at a time, only one thread can operate on a
StringBuffer, thus affecting performance of applications - so, we can also use
StringBuilder - the apis of string builder are almost the same as string buffer - so, it is like a “non synchronized version of string buffer” - run
javap java.lang.StringBuilderin terminal -public void setCharAt(int, char); public int capacity(); public int length(); // and so on... - so higher performance at the cost of race conditions which we might have to take care of ourselves
- side note - strings are automatically thread safe since they are immutable
- method chaining - because most methods in
String,StringBuffer,StringBuilderreturn the same object type, we can use method chaining technique
Exceptions
- Throwable
- Exception
- RuntimeException
- ArithmeticException
- NullPointerException
- etc
- IOException - used when doing file related operations etc
- InterruptedException - used in multithreading related code etc
- etc
- RuntimeException
- Error - out of memory error, stack overflow error, etc
- Exception
- unchecked exceptions
- runtime exceptions and its subtree
- error and its subtree
- everything else is checked exception
- try with resources - cleaner code, no need to call
closeexplicitly, if they use the interfaceAutoCloseabletry (BufferedReader br = new BufferedReader(new FileReader("file.txt"))) { // ... } - note - what we declare / assign inside the try statement is final, and cannot be reassigned
ClosableextendsAutoClosable.ClosablethrowsIOException, whileAutoClosablethrowsExceptionwhich is more generic- when we are handling exceptions, it might happen that we lose track of the original exception, and throw another exception which is not that relevant. e.g.
- reading from a resource fails due to missing file
- closing the resource fails due to null pointer because the resource was never initialized properly
- the eventual exception we get is the null pointer, but the missing file exception would have helped us more in identifying the root cause
- so, we can also use
ex.addSuppressed(Throwable t)orThrowable[] t = ex.getSuppressed(). this way, we can also find the original cause behind the exception - note - try with resources will automatically make use of suppressions for us bts
- another note - when using try with resources, the null pointer exception will be added as a suppression to the file not found exception, because understand that the main exception that happened in the try block was file not found exception, and the null pointer exception happened inside the finally block
class CustomResource implements AutoCloseable { public void read() { throw new RuntimeException("could not read file"); } @Override public void close() { throw new RuntimeException("a null pointer exception happened"); } } public class SuppressionExample { public static void main(String[] args) { try { System.out.println("without try with resources"); withoutTryWithResources(); } catch (Exception e) { System.out.println(e.getMessage()); for (Throwable t : e.getSuppressed()) { System.out.println("suppress: " + t.getMessage()); } } System.out.println(); try { System.out.println("with try with resources"); withTryWithResources(); } catch (Exception e) { System.out.println(e.getMessage()); for (Throwable t : e.getSuppressed()) { System.out.println("suppress: " + t.getMessage()); } } } private static void withoutTryWithResources() { CustomResource customResource = null; try { customResource = new CustomResource(); customResource.read(); } finally { customResource.close(); } } private static void withTryWithResources() { try (CustomResource customResource = new CustomResource()) { customResource.read(); } } } - output -
without try with resources a null pointer exception happened with try with resources could not read file suppress: a null pointer exception happened - we can also catch multiple exceptions using a single catch block
try { } catch (NullPointerException | ArrayOutOfBoundsException e) { e.printStackTrace(); triggerAlert(e); }
Generics
- what is generics -
- helps extend java’s type system - types now start acting like parameters that we as clients can provide
- to allow a type or method to operate on objects of various types to thus allow reusability. e.g. without generics, we would use overloading, which causes a lot of duplication of logic -
class OverloadingProblem { public static Double add(Double a, Double b) { return a + b; } public static Integer add(Integer a, Integer b) { return a + b; } public static void main(String[] args) { System.out.println(add(1, 5)); System.out.println(add(1.2, 5.3)); } } - while providing compile time safety - e.g. without using generics, we would use type casting, which has two compile time checks but one runtime check, and catching errors at compile time > catching them at runtime -
class TypeCastingProblem { private static Object item = null; public static void setItem(Object item) { TypeCastingProblem.item = item; } public static Object getItem() { return item; } public static void main(String[] args) { setItem(1.4); Integer item = (Integer) getItem(); } }output -
![generics typecasting]()
- we use the diamond operator for generics
class Pair<K, V> { private K key; private V value; public Pair(K key, V value) { this.key = key; this.value = value; } @Override public String toString() { return "{ " + key + ": " + value + " }"; } } class GenericExample { public static void main(String args[]) { Pair<String, Integer> score = new Pair<>("maths", 85); System.out.println(score); } } - generic method - my understanding - this is useful when the class itself is not generic / maybe method and class generics do not mean the same thing, so we can for e.g. use
Tfor class andVfor methodclass GenericMethod { public static <T> void printer(T arg) { System.out.println("value is: " + arg); } public static void main(String args[]) { printer(1); printer("hello"); } } - while the return type above is void, we could have for e.g. returned
Tetc as well - bounded generic types - bound the types that are allowed to be used, to get access to the additional functionality that is present in the types used in these bounds, e.g. only allow
Numberand its subclasses to be used for a generic class containing mathematical utilities - we use the
extendskeyword to achieve bounded generic types, and the target type should be a subclass of the interface / class mentioned in this clausepublic static <T extends Comparable<T>> T calculateMin(T a, T b) { return (a.compareTo(b) < 0) ? a : b; } - e.g.
copyis implemented as follows - my understanding - this is to help make use of dynamic polymorphism + bounded types. note - just because we can dosuperclass_reference = subclass_reference, does not mean we can doList<superclass_reference> = List<subclass_reference>public static <T> void copy(List<? super T> dest, List<? extends T> src) - we can also specify multiple bounds using
& - type inference - determine the types automatically. some examples -
- java can automatically guess “the most specific type” that both
StringandArrayListcan work with -Serializableclass TypeInference { public static <T> T getFirst(T a, T b) { return a; } public static void main(String[] args) { Serializable result = getFirst("hello world", new ArrayList<Integer>()); } } - we use
List<String> list = new ArrayList<>();and notnew ArrayList<String>() - we use
list.add("name")and notlist.<String>add("name")
- java can automatically guess “the most specific type” that both
- note - just because
NumberandIntegerare related via inheritance, it does not meanList<Number>andList<Integer>are somehow related as well - this is the motivation behind wildcards
import java.util.List; class Wildcards { private static void print(List<Object> list) { list.forEach(System.out::println); } public static void main(String[] args) { List<Integer> list = List.of(1, 2, 3); print(list); } } // error: incompatible types: List<Integer> cannot be converted to List<Object> // solution - notice the use of ? // private static void print(List<?> list) { ... - upper bounded wildcards - when we use
?andextends, e.g. allow all lists where the type of element is a subclass of the class specified in the generic method signature - drawback - e.g. while we can print all elements of the list easily, we cannot add an element to the list - e.g. the list is actually of integer, and we might be trying to add a double to the list. since java cannot identify this problem, it gives a compile time error
- e.g. this works perfectly
private static void printList(List<? extends Number> numbers) { numbers.forEach(System.out::println); } public static void main(String[] args) { printList(List.of(1, 2, 3)); printList(List.of(1.1, 2.2, 3.3)); } - however, if we add the below to the printList method -
private static void printList(List<? extends Number> numbers) { numbers.forEach(System.out::println); numbers.add(7); } - we get the error below -
BoundedWildCardsExtends.java:7: error: incompatible types: int cannot be converted to CAP#1 numbers.add(7); ^ where CAP#1 is a fresh type-variable: CAP#1 extends Number from capture of ? extends Number - lower bounded wildcards - when we use
?andsuper, e.g. allow all lists where the type of element is a superclass of the class specified in the generic method signature - so now, since java knows that the list passed to has elements of supertype of specified type, we can now add elements to the list of that type (dynamic polymorphism)
- drawback - we cannot read from the list - we have to treat the element as type
Objectpublic static void addToList(List<? super Double> list) { list.add(1.4); } public static void main(String[] args) { List<Object> list = new ArrayList<>(); list.add(1); list.add("shameek"); addToList(list); System.out.println(list); } - use case of wildcards + bounded types - copy elements from one list to another -
public <T> void copy(List<? extends T> source, List<? super T> destination) { source.forEach(destination::add); } - so, we should -
- use “lower bounded wildcards” when we want to perform some kind of mutation
- use “upper bounded wildcards” when we want to read values
- use “type parameters” when we want to do both reading and writing
- one difference between “type parameters” and “wildcards” is that type parameters allow for multiple bounds unlike wildcards, e.g. following is valid -
<T extends XYZ & PQR> - rule of thumb? - use wildcards when possible, when not possible (e.g. we want to influence return type based on arguments), then use type parameters
- type erasure - java replaces all generic types we define with either Object, or the bound if a bound is specified
- as a part ofo this, java might introducing type casting etc as well
- e.g. the code below -
List<Integer> list = new ArrayList<>(); list.add(1); Integer ele = list.get(0); class Store<T extends Serializable> { T item; } - is converted to this code due to type erasure -
List list = new ArrayList(); list.add(1); Integer ele = (Integer) list.get(0); class Store { Serializable item; }

Collections
List
ArrayListallows for control over ordering of elements- all items are identified by an index
- items are located right next to each other in ram, thus making random access via index o(1)
- searching for items based on value is however o(n)
- adding items at the end is o(1)
- adding items at random positions is o(n), since it requires shifting of items by one position
- same logic is applicable for removal of items - o(1) for removing items from the end and o(n) for removing items from arbitrary positions
- size of array lists in java can change dynamically - once the amount of memory allocated gets over, a list with memory equal to double the size of the current list is provisioned, and all the items from the current list are copied over to the new list
- however, this ability to resize dynamically comes at a price - it takes o(n) time for this resize + copying over of items to the new location to happen
- however, when instantiating, we can provide the initial capacity, so that this resizing does not have to happen often
- disadvantage of array lists - when removing / adding items at random positions, a lot of shifting is needed to maintain the contiguous nature
- this problem is not there when using
LinkedList - since in linked lists, there is only a pointer to the next element that needs to be maintained
- disadvantage - linked lists don’t allow random access with given index at o(1) time
- note - linked list in java is optimized -
- implemented as doubly linked list which allows it traversal in both directions
- maintains pointers to both head and tail - e.g. we can do use both
addFirstandaddLastat o(1) time
- linked list vs array list performance for adding elements at the beginning -
import java.util.List; import java.util.ArrayList; import java.util.LinkedList; class ListPerformance { public static void main(String args[]) { perform("linked list", new LinkedList<>()); perform("array list", new ArrayList<>()); } private static void perform(String type, List<Integer> list) { long start = System.currentTimeMillis(); for (int i = 0; i < 500000; i++) { list.add(0, i); } long end = System.currentTimeMillis(); System.out.println("time taken by " + type + ": " + (end - start) + "ms"); } } - output -
time taken by linked list: 75ms time taken by array list: 43375ms - note - while we compared linked list to array lists above, as discussed later, if removing or adding to one of the ends, the most performant option we have is array deque, not stacks, not linked lists
- vector - synchronized implementation of array list i.e. all operations like add etc will do acquiring and releasing of lock
- generally, doing this using our own locks might be better, since we get more flexibility, e.g. batch multiple operations under one acquiring + releasing of lock
- stack - lifo structure (last in first out)
- important operations include
push,popandpeek - note - stacks use vectors underneath, so they are inherently synchronized
Stack<String> stack = new Stack<>(); stack.push("jane"); stack.push("jackson"); System.out.println(stack); // [jane, jackson] System.out.println(stack.pop()); // jackson - to avoid using synchronized version, we can use array dequeue instead
Queues
- queues - fifo structure (first in first out)
- important operations include
add(enqueue),remove(dequeue) andpeek(retrieve but not remove last element) - queues are abstract like stack as well - it is implemented using linked lists
Queue<String> queue = new LinkedList<>(); queue.add("jane"); queue.add("jackson"); System.out.println(queue); // [jane, jackson] System.out.println(queue.remove()); // jane - priority queue - objects being stored inside a priority queue should extend the
Comparableinterface - this helps retrieve items form the structure in the order of their priority
- dequeue - double ended queue - o(1) for operating from either side of the collection. it is implemented by array dequeue and just like normal queues, we can implement it using linked lists instead as well
- note - java calls it deque and not dequeue
Deque<String> dequeOne = new LinkedList<>(); Deque<String> dequeTwo = new ArrayDeque<>(); - my doubt about performance - based on the fact that array dequeue might be using an array underneath, doing the typical “capacity resizing” that we discussed, would we have an even more performant solution if we were to use linked list? be it for implementing stacks or queues, logically performance of linked lists > array dequeues (dynamic capacity resizing issue) > stacks (synchronization issue)
- based on this answer, apparently not, because the main overhead that comes with linked lists is the extra creation of that node, garbage collection of that node, etc
- so, it is probably safe to conclude that in java, when we are looking for stack or queue implementation, we should use array dequeues almost always (over the stack since it is synchronized, and linked lists since it has memory overhead?)
- also, do not use array lists blindly - if we just have to remove and add elements to either ends, and do not need random access, array dequeues might be better than array lists (inserting at beginning of array list is o(n) and inserting at beginning of array deque is o(1))
Maps
- key value pairs
- also called associative arrays
- with maps, we ensure times of o(1) for adding, removing and lookup
- maps are unordered / do not support sorting
- the idea is that since keys in a map are unique, we transform the keys into an index between 0 to length - 1 of array using a hash function. then, accessing elements via the given key becomes o(1) - we just need to translate the key into an index using the hash function, and random access of elements in an array is an o(1) operation
- the hash function should be able to handle the type of key - e.g. if the key is an integer, using modulo operator with the length of array is enough, if the key is a string then ascii value of characters can be used and so on
- collision in hash tables - the hash function we used result in the same value for multiple keys
- overwrite - replace current value with new incoming value
- chaining - each bucket in the hash table can store a linked list. worst case scenario - all keys evaluate to the same value, so the entire map is just a single big linked list stored in one bucket, thus resulting in an o(n) complexity instead of o(1)
- open addressing -
- linear probing - try finding the next available empty slot - k + 1, k + 2, k + 3, … disadvantage - clusters are formed i.e. elements with same hash are clustered together
- quadratic probing - try finding the next available empty sot using a quadratic polynomial - k + 1, k + 4, k + 9, k + 16, …
- rehashing - perform another hashing on the key till an empty slot is found - h(h(h….(x)))
- so actually, worst case in hash tables for all operations - insertions, deletions and lookups are o(n)
- load factor - n / m, where n = number of items in the hash table and m = size of the array. if it is close to 1, the probability of collision will increase
- so, we can also do dynamic resizing of hash tables. disadvantage - this resizing is an o(n) operation
- in java, for
HashMap, when the load factor becomes around 0.75, the dynamic resizing happens - however, hash maps cannot be used in multithreaded scenarios, since they are not synchronized
- some important methods available in maps -
keySet(),entrySet(),values() - auto generated hash code example - look at how a prime number is used to generate a function with less collision chances
class Person { private Integer age; private String name; @Override public int hashCode() { final int prime = 31; int result = 1; result = prime * result + ((age == null) ? 0 : age.hashCode()); result = prime * result + ((name == null) ? 0 : name.hashCode()); return result; } } - note - the
equalsneeds to be overridden as well. it might happen that due to chaining discussed earlier, multiple items end up in the same bucket of hash table. at that point, java might need to be able to differentiate between two different elements of the same hash - so basically, java uses both chaining and dynamic resizing based on load factor by the looks of it
LinkedHashMapsvsHashMaps- linked hash maps use a doubly linked lists underneath to track the “order of insertion”, so the keys are basically ordered according to insertion timeMap<String, Integer> hashMap = new HashMap<>(); hashMap.put("aaa", 1); hashMap.put("bbb", 2); hashMap.put("ccc", 3); System.out.println(hashMap); // {aaa=1, ccc=3, bbb=2} Map<String, Integer> linkedHashMap = new LinkedHashMap<>(); linkedHashMap.put("aaa", 1); linkedHashMap.put("bbb", 2); linkedHashMap.put("ccc", 3); System.out.println(linkedHashMap); // {aaa=1, bbb=2, ccc=3}- balanced bst (binary search trees) - red black trees and avl trees
- tree rotations are used to maintain this structure
- tree maps use red black trees unlike in hash maps, where an array like structure is used
- so, the keys are stored in sorted order in tree maps. notice how it is automatically fr us below -
Map<String, Integer> treeMap = new TreeMap<>(); treeMap.put("ccc", 3); treeMap.put("bbb", 2); treeMap.put("aaa", 1); System.out.println(treeMap); // {aaa=1, bbb=2, ccc=3} - because it uses trees, operations have a guaranteed complexity of o(log n) in tree maps, whereas operations have mostly o(1) but sometimes o(n) complexity in case of hash maps
- my understanding - since a bst is being used, concept of collision, load factor, etc do not exist in tree maps unlike in hash maps
- so, for huge workloads, while we might have to consider tuning the load factor in case of hash set, we do not have to think about it in case of a tree set
- note - in newer versions, hash maps does not use linked lists (chaining) for each bucket, it uses red black trees for each bucket. this further optimizes the hash maps now
- because of the very nature - using a red black tree per bucket, using an array to store the multiple keys, etc - memory required by hash maps > tree maps
- but remember, reducing time > reducing memory with cloud etc
Sets
- they allow no duplicates
- hash sets and hash maps work in the same way - a one dimensional array is used to store the elements by performing a hash on the element
- some important functions -
add,remove,retainAll(callingset2.retainAll(set1)will retain all the elements in the set2 present in set1, and remove other elements from set2) - so, operations are mostly are o(1) but can be o(log n) in worst case / o(n) when dynamic resizing is needed
- again, linked hash sets are same as hash maps, the insertion order would be maintained, which is maintained with the help of an additional doubly linked list
- finally, tree set are same as tree maps - maintain elements in a sorted order using a red black tree underneath, thus making operations o(log n) in general
- tree sets come with their own additional methods - e.g.
subset(a, b)will give us a new set with all values of the set present between a and b,firstfor getting the first element, etc
Sorting
- sort - notice “reverse order” below -
List<Integer> list = new ArrayList<>(); list.add(3); list.add(2); list.add(1); list.add(4); list.add(5); System.out.println(list); // [3, 2, 1, 4, 5] Collections.sort(list); System.out.println(list); // [1, 2, 3, 4, 5] Collections.sort(list, Collections.reverseOrder()); System.out.println(list); // [5, 4, 3, 2, 1] - we can implement
Comparableon our custom classes to be able to sort them directly -class Person implements Comparable<Person> { String name; Integer age; Person(String name, Integer age) { this.name = name; this.age = age; } public int compareTo(Person person) { Integer nameDiff = name.compareTo(person.name); Integer ageDiff = age.compareTo(person.age); return ageDiff != 0 ? ageDiff : nameDiff; } public String toString() { return "Person(name=" + name + ", age=" + age + ")"; } } class CustomSortComparable { public static void main(String[] args) { List<Person> people = new ArrayList<>(); people.add(new Person("ayan", 25)); people.add(new Person("ruth", 5)); people.add(new Person("jack", 25)); people.add(new Person("jane", 25)); people.add(new Person("mike", 20)); System.out.println(people); // [Person(name=ayan, age=25), Person(name=ruth, age=5), Person(name=jack, age=25), Person(name=jane, age=25), Person(name=mike, age=20)] Collections.sort(people); System.out.println(people); // [Person(name=ruth, age=5), Person(name=mike, age=20), Person(name=ayan, age=25), Person(name=jack, age=25), Person(name=jane, age=25)] } } Comparatoruse cases -- we want to sort using multiple techniques. compareTo can only have one implementation, therefore lacks flexibility
- we want to sort a class not in our control i.e. we cannot change the class to make it implement
Comparable - also helps achieve separation of concerns
class PersonAgeComparator implements Comparator<Person> { @Override public int compare(Person person1, Person person2) { return person2.age.compareTo(person1.age); } } Collections.sort(people, new PersonAgeComparator()); System.out.println(people); // [Person(name=ayan, age=25), Person(name=jack, age=25), Person(name=jane, age=25), Person(name=mike, age=20), Person(name=ruth, age=5)] Collections.sort(people, new PersonAgeComparator().reversed()); System.out.println(people); // [Person(name=ruth, age=5), Person(name=mike, age=20), Person(name=ayan, age=25), Person(name=jack, age=25), Person(name=jane, age=25)]- using lambdas - for a more functional style, we can use the following syntax as well 🤯 -
Collections.sort( people, Comparator.comparing(Person::getAge).reversed().thenComparing(Person::getName) ); System.out.println(people); // [Person(name=ayan, age=25), Person(name=jack, age=25), Person(name=jane, age=25), Person(name=mike, age=20), Person(name=ruth, age=5)]
Miscellaneous
- some methods, refer docs for more -
List<Integer> list = new ArrayList<>(); list.add(5); list.add(1); list.add(2); list.add(4); list.add(3); System.out.println("original list = " + list); // original list = [5, 1, 2, 4, 3] Collections.shuffle(list); System.out.println("shuffled list = " + list); // shuffled list = [3, 1, 5, 4, 2] Collections.reverse(list); System.out.println("reversed list = " + list); // reversed list = [2, 4, 5, 1, 3] System.out.println("min = " + Collections.min(list) + ", max = " + Collections.max(list)); // min = 1, max = 5 - since collections are pass by reference, make collections unmodifiable so that clients cannot mutate our collections
List<Integer> unmodifiableList = Collections.unmodifiableList(list); unmodifiableList.add(-1); // Exception in thread "main" java.lang.UnsupportedOperationException // at java.base/java.util.Collections$UnmodifiableCollection.add(Collections.java:1091) // at MiscellaneousMethods.main(MiscellaneousMethods.java:20) - if we want to obtain a synchronized version of the normal collections we can use
List<Integer> synchronizedList = Collections.synchronizedList(normalList) - drawback - coarse grained locking is used, all methods use
synchronizedkeyword now - so, better solution is to use concurrent collections that java provides, e.g.
ConcurrentHashMap
About Java
- object oriented programming language
- biggest advantage - portability. this model is called wora - write once, run anywhere
- three main components of java - jvm, jre and jdk
- jvm - java virtual machine
- we write platform independent java code
- this java code then gets converted to bytecode (the .class files that we see)
- jvm however, is specific to platforms
- jit - just in time compiler - it is a part of the jvm
- it receives bytecode as input and outputs the platform specific machine code
- jre - java runtime environment
- jre contains the jvm and class libraries -
java.Math...,java.Lang..., etc - so, jvm comes as part of jre, and we need jre since it has all the important classes
- jdk - java development kit. it contains the following components -
- jre
- it contains the java compiler (javac) that converts java files to bytecode
- the capability helps us debug our java programmes, etc
- jse - java standard edition
- jee - java enterprise edition - contains the jse + apis around transactions, servlets, etc. renamed to jakarta ee
- jme - java mobile edition / java micro edition - for mobile applications
Maven
- maven is a build tool for java
- other alternatives are gradle, ant, etc
- build - process of building source code into artifacts that can be run
- maven has various plugins -
- jar plugin to create jars
- compiler plugin to help compile code
- surefire plugin to execute tests
- a plugin has various goals. goals represent a unit of work
- to examine a plugin, we can use the following commands -
mvn help:describe -Dplugin=org.apache.maven.plugins:maven-compiler-plugin` - maven coordinates -
- group id - company / department name. domain name in reverse order is the convention
- artifact id - project name
- version -
- packaging - there are two types of packaging - jar (mostly used nowadays and the default) and war (web application archive)
- classifier - e.g. we want to build for different versions of java but use the same pom. so, we can use classifiers like
jdk8andjdk11. these then get appended to the version, so people can import the right dependency
- out of these, the gav (group id, artifact id and version) help us uniquely identify the project
- to use these libraries in our projects, we use repositories
- there two repositories - local repository and remote repository
- basically, maven downloads from remote repositories and puts it into our local repository
- then, our projects running locally can use dependencies downloaded in this local repository
- default location for local repository is ~/.m2/repository
- default url for remote repository is https://repo1.maven.org/maven2/ (called maven central)
- we can configure remote repositories via settings.xml - so that we can use our own remote repository - use case - companies maintain their own remote repository, which is a mirror of maven central
Plugin Management
- lifecycle has phases
- a phase has multiple goals attached to it
- if a phase does not have any goals attached to it, it would not be executed
- e.g. the clean lifecycle has three phases - pre-clean, clean and post-clean
- only the clean phase of the clean lifecycle is attached to a goal
- it is attached to the clean goal of maven-clean-plugin plugin 🤯
- when we say
mvn clean, we are actually instructing maven to run the clean phase - when we run a phase, all the phases before it in the lifecycle are executed - in this case pre-clean would be executed first (if it has some goals attached to it, it does not by default) and the clean phase itself
- we just discussed that we typically invoke
mvn <<phase>>, which runs all the goals of all the phases up to before the specified phase’s lifecycle. however, we can also invoke a particular goal using the following syntax variations -mvn plugin_group_id:plugin_artifact_id:plugin_version:goalmvn plugin_group_id:plugin_artifact_id:goalmvn plugin_prefix:goalmvn plugin_prefix:goal@execution_id- while executions help us tie goals to phases, we can also invoke these executions directly
mvn org.apache.maven.plugins:maven-clean-plugin:2.5:clean mvn org.apache.maven.plugins:maven-clean-plugin:clean mvn clean:clean - there are two kinds of plugins -
- reporting plugins - run during site generation
- build plugin - run to help build the project
- below - we try to tie the run goal of maven-antrun-plugin to pre-clean and post-clean phases -
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-antrun-plugin</artifactId> <version>3.0.0</version> <executions> <execution> <id>1</id> <phase>pre-clean</phase> <goals> <goal>run</goal> </goals> <configuration> <target> <echo level="info">Learning Maven: pre-clean</echo> </target> </configuration> </execution> <execution> <id>2</id> <phase>post-clean</phase> <goals> <goal>run</goal> </goals> <configuration> <target> <echo level="info">Learning Maven: post-clean</echo> </target> </configuration> </execution> </executions> <configuration> <target> <echo level="info">Learning Maven: standalone invoking</echo> </target> </configuration> </plugin> - so, now when we run post-clean phase, all three phases - pre-clean, clean and post-clean would be run
- configuring a plugin
- a plugin can have multiple execution blocks. each execution block specifies -
- what goal to run
- what phase to tie this goal to
- configuration for the goal
- a configuration element can be specified in the root as well. earlier point was us basically specifying multiple execution blocks, which helped us tie goals to phases. this point here is about specifying configuration in the root block of the plugin. this can be useful when we invoke the plugin:goal directly
- dependencies - if a plugin has dependencies, we can for e.g. specify the version of that dependency using this block
- inherited - by default, the plugin configuration is inherited by the children. we can disable this behavior by setting inherited to false
- a plugin can have multiple execution blocks. each execution block specifies -
- id should be unique across all executions for a plugin (not across plugins)
- apart from clean, the two other lifecycles are default and site
the goals that are triggered for the default lifecycle are dependent on the packaging type (recall packaging type can be one of jar or pom, it is a part of maven coordinates). for jar, this is the table -
phase plugin:goal process-resources resources:resources compile compiler:compile process-test-resources resources:testResources test-compile compiler:testCompile test surefire:test package jar:jar install install:install deploy deploy:deploy - when we specify dependencies in dependency management of parent, child projects can get these dependencies if they want to, but don’t get the dependency unless added explicitly. plugin management works in the same way - inherit all the configuration related to the plugin specified in the plugin management section of the parent, but do not get it by default unless the plugin is added explicitly
- extra - executing scripts using exec maven plugin! -
<plugin> <artifactId>exec-maven-plugin</artifactId> <version>3.1.1</version> <groupId>org.codehaus.mojo</groupId> <executions> <execution> <id>Renaming build artifacts</id> <phase>package</phase> <goals> <goal>exec</goal> </goals> <configuration> <executable>bash</executable> <commandlineArgs>handleResultJars.sh</commandlineArgs> </configuration> </execution> </executions> </plugin>
Inheritance and Aggregation
<modelVersion>helps determine the xsd (scm schema definition) version to use i.e. what elements are allowed in the pom file, how they should be configured, etc- multiple levels of inheritance is supported in pom
- all pom (directly or indirectly) inherit from the super pom
- this inheritance helps us extract out common functionality around plugins, plugin configuration, dependencies, etc to a parent pom from which all other projects can inherit
- we can print the effective pom like so -
mvn help:effective-pom - my understanding - the parent might be managed separately -
- parent would be downloaded from the remote repository into the local repository, post which it can be used
- for development purpose - build the parent, which will install it in the local repository, and then build the child
- the parent might be managed in the same project, in which we can provide the
relativePath. understand that this way, we do not have to build the parent project separately like above - - also, packaging type in parent can be specified to be
pominstead of relying on the default value i.e.jar - till now, we discussed inheritance. we can also use aggregation in maven
- use case - when we run a phase e.g.
mvn clean,mvn install, etc., it gets run for all the child projects as well - not only that - in aggregate projects, if the child projects depend on each other, maven can determine the right order to build them in for us automatically
- we can also use the same pom for both aggregation and inheritance
- notes about versions -
- version property of parent gets inherited by the children as well
- for specifying the version of parent in the child, we use
${revision} - for specifying interdependencies between children, we use
${project.version}
- based on everything above, a simple multi module setup -
- parent -
<project> <modelVersion>4.0.0</modelVersion> <groupId>org.apache.maven.ci</groupId> <artifactId>ci-parent</artifactId> <version>${revision}</version> <properties> <revision>1.0.0-SNAPSHOT</revision> </properties> <modules> <module>child1</module> <module>child2</module> </modules> </project> - child -
<project> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.apache.maven.ci</groupId> <artifactId>ci-parent</artifactId> <version>${revision}</version> <relativePath>../pom.xml</relativePath> </parent> <groupId>org.apache.maven.ci</groupId> <artifactId>ci-child</artifactId> <dependencies> <dependency> <groupId>org.apache.maven.ci</groupId> <artifactId>child2</artifactId> <version>${project.version}</version> </dependency> </dependencies> </project>
- parent -
Dependency Management
- we can specify a range of versions using
[3.8, 4.0)([for inclusive,(for exclusive) - version format -
<<major-version>>.<<minor-version>>.<<patch>>-<<qualifier>> - the qualifier
SNAPSHOTis used for unstable projects, which can change frequently - this way, if we depend on a project with snapshot in its version, we get access to the latest code always
- my understanding - if for e.g. we do not use snapshot -
- if the local repository already has an existing copy, maven would not bother refetching it from the remote repository to refresh the local copy
- probably sometimes the remote repository also would not allow pushing artifacts again against the same version
- bts, this SNAPSHOT is converted to timestamp automatically for us - so,
x.y.z-SNAPSHOTbasically becomesx.y.z-timestamp, and thus this way, maven always tries pulling the latest version for us - maven is able to handle transitive dependencies for us - if our project depends on jar a which in turn depends on jar b, maven is able to download jar a and then jar b automatically for us when building the project
- classpath - location of classes and packages that our project is dependent on
- the different dependency scopes -
- compile - include dependency in all classpaths. the default if
scopeis not specified explicitly - test - only required for compiling and executing tests, not required when executing therefore need not be included when packaging artifacts
- runtime - include dependency when project executes or tests are being run, but do not include them when compiling. e.g. jdbc driver like mysql connector. use case - we as developers will not mistakenly depend on these libraries
- provided - dependencies provided by the environment. e.g. we are developing a web application, we would need to depend on the servlet api to compile, but we would not want to include this in the war file, since it would be provided to us by the servlet container
- system - like provided, but the path when compiling is specified manually
<dependency> <groupId>io.datajek</groupId> <artifactId>some-dependency</artifactId> <version>1.0</version> <scope>system</scope> <systemPath>${project.basedir}/libs/dep-1.0.jar</systemPath> </dependency> - import - when a dependency is of type pom and has the scope of import, it should be replaced by its dependencies in its
dependencyManagementsection
- compile - include dependency in all classpaths. the default if
- dependency mediation - choosing what version of dependency to use
- default behavior -
- e.g. our project depends on A and B. A depends on D which again depends on E (version x). B directly depends on E (version y). our project would use E (version y), because if we imagine dependencies like a tree, E (version y) is the closest to root
- e.g. our project depends on B and A (B comes first in pom.xml). B depends on E (version x), while A depends on E (version y). our project would use E (version x), because B comes first
- so one technique based on above - if we would like to use version x of E invariably - place version x of dependency E as early as possible and directly inside the pom. this way, we end up using the verison x of E always
- when adding a dependency, if we use the
exclusiontag along with it, the dependencies specified in the exclusion tag are excluded from the dependency tree -<dependency> <groupId>io.datajek</groupId> <artifactId>project9-projectb</artifactId> <version>1</version> <exclusions> <exclusion> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> </exclusion> </exclusions> </dependency> - this means that we should either expect gson to come as a transitive dependency from another project, or include gson manually inside our pom as another dependency, etc
- lets say our project name is xyz, and we mark a dependency in our pom as optional
- it excludes this dependency from being added as a transitive dependency in any project that has xyz itself as a dependency
- dependency management section - this way, all the projects in for e.g. a team can specify the versions of dependencies that work well with each other in one place, and all of it gets inherited by all other child projects
- example -
- if a parent has the following section -
<dependencyManagement> <dependencies> <dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.8.6</version> </dependency> </dependencies> </dependencyManagement> - the child can skip the version of gson when adding it as a dependency
<dependencies> <dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> </dependency> </dependencies>
- if a parent has the following section -
- another use case of dependency management section 🤯 - helps with transitive dependencies as well - e.g. if our project has a dependency A, which depends on C (version x), and has a dependency B, which again depends on C (version y). if we add the dependency C (version z) in the dependency management section, version z of dependency is the one that maven uses!
- note - we could also have included dependency C (version z) directly in the dependency section to force maven to use version z (default behavior - closest to the root wins). however, if another project added this project as a dependency, even if it was not using dependency C (version z) directly, it would still have it being added to its classpath. this problem would not have happened in the first place if we had added dependency C (version z) in the dependency management section as described earlier
Build Portability
- build portability - having consistent ways to build cross environments, machines, teams, etc
- variables - variables defined in parent are inherited by children
- however, children can override these variables
- project can be accessed using
project, e.g.${project.version},${project.build.sourceDirectory}, etc. the root element of our pom isproject, so that is where these variables come from. another very useful one i found -${project.parent.basedir}if for e.g. a child project wants to access something from the parent directory - whatever we define in the properties section can be accessed using the name of the property directly, e.g.
${MyString} - java system properties (what we access using
java.lang.System.getProperties()) can be accessed usingjava, e.g.${java.home} - environment variables can be accessed using
env, e.g.${env.PATH} - variables in settings.xml can be accessed using
settings, e.g.${settings.offline} - profiles - alternative configuration for overriding default values
- we can specify profiles either in the project specific pom.xml, or in settings.xml, which itself can be machine / project specific
<project> <modelVersion>4.0.0</modelVersion> <groupId>io.datajek</groupId> <artifactId>project14</artifactId> <version>1</version> <name>Project14</name> <profiles> <profile> <id>test</id> <build> <plugins> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <executions> <execution> <id>my-special-exec</id> <configuration> <executable>/Project14/testScript.sh</executable> </configuration> </execution> </executions> </plugin> </plugins> </build> </profile> <profile> <id>prod</id> <build> <plugins> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <executions> <execution> <id>my-special-exec</id> <configuration> <executable>/Project14/prodScript.sh</executable> </configuration> </execution> </executions> </plugin> </plugins> </build> </profile> </profiles> <build> <pluginManagement> <plugins> <plugin> <groupId>org.codehaus.mojo</groupId> <artifactId>exec-maven-plugin</artifactId> <version>3.0.0</version> <executions> <execution> <id>my-special-exec</id> <phase>clean</phase> <goals> <goal>exec</goal> </goals> </execution> </executions> </plugin> </plugins> </pluginManagement> </build> </project> - the most basic way in which we can specify which profile to use -
mvn clean -Ptest - another way ofo enabling a certain profile - inside the
profilesection we saw above, we can have an activation section like below -<activation> <property> <name>testProp</name> <value>DataJek</value> </property> </activation> - this means that the profile expects the system property testProp to be of value DataJek -
mvn clean -DtestProp=DataJek - archetypes - a project templating toolkit so that a new project can be created easily with all the for e.g. firm specific standards established in the project from the get go