Introduction
- 3 vs of big data - these are the reasons why big data was needed in the first place
- data volume - as the resolution of camera has increased, so has the size of the media it generates
- data velocity - speed at which data is generated. earlier, batch jobs i.e. at a period were more common. the shift is towards near realtime / realtime now
- data variety - data used to just be in the form of tables, where rdbms systems worked great. now, we have unstructured data in the form of media etc as well i.e. variety of data has increased
- structured data - row column format in a table. e.g. rdbms
- semi structured data - well defined structure, but not necessarily structured in a tabular format, e.g. json, xml
- unstructured data - e.g. text files, audio, etc
- some new vs - veracity (trustworthiness of data, e.g. user input might not be as trustworthy?), value (should be able to drive business value)
- monolithic vs distributed approach. distributed approach is used in big data because -
- more scalable i.e. increase capability with increasing workload easily. we use horizontal scaling instead of vertical scaling
- more highly available / fault tolerant i.e. failure is isolated to a single component, the overall system stays functional
- more cost effective - we can easily fine tune the size and number of machines based on workload
- shared nothing - each processing has its own storage. relatively faster
- shared disk - each processing unit works on the same underlying architecture. time taken for data movement is high, since unlike in shared nothing where the storage can be local / closely located to the processing, it has to be located far away
- partitioning - file is broken down (partitioned) and stored in smaller parts in different nodes. also called distributed
- replication - the parts are stored in different nodes so that a node failure does not stop our processing. also called redundancy. number of total copies is determined by “replication factor”
- 4 points - hadoop uses a distributed approach, follows shared nothing architecture, has partitioning, has replication
- and more importantly, hadoop while doing all of this, hadoop abstracted it away from us
- hadoop is and isn’t good at - 4 points -
- processing large files - it is not for small files
- processing sequentially - it is not good for random access since there is no indexing like in rdbms
- handling unstructured data - it not for acid like / 3nf etc properties like in rdbms
- processing frequently changing data
Evolution
- around 2003, google published a paper on gfs (google file system) and in 2004, on google map reduce
- in parallel around the same time, doug cutting was working on nutch
- yahoo hired doug and hadoop was created from nutch
- hadoop’s hdfs = google’s gfs and hadoop’s map reduce = google’s map reduce
- facebook launched hive, big query is google’s equivalent of this
- with hive (and pig), we write sql to query or add data to hdfs, thus making writing complex operations much easier. this translates to map reduce underneath
- hbase - nosql database system on top of hdfs to store unstructured data. big table is google’s equivalent of this. we store data in a denormalized format for better performance
- sqoop - data transfer (to and from) between database (mostly rdbms) and hdfs
- flume - streaming logs from distributed systems into hdfs
- spark - complete package
- cloudera, hortonworks, etc. bundle different tools like hadoop together and distribute them
Hadoop Components
- my understanding - hadoop = map reduce + hdfs + yarn in todays world
- yarn - yet another resource negotiator. it is a “cluster manager”. it is needed because recall how hadoop makes use of horizontal scaling, while abstracting away all the complexities underneath away from us. refer hadoop 2.x architecture below for how “resource manager”, “node manager” and “application master” work
- hdfs - stores large amounts of data in small chunks to allow processing them in parallel. refer hdfs architecture below for how “name node”, “data node” etc work
- map reduce framework - we write simple map reduce programs discussed in this post. this is automatically run in a distributed fashion with the help of yarn, on distributed data with the help of hdfs. note - writing map reduce directly is not common, so tools like hive etc came into picture
Theory
- hadoop operating modes
- standalone - doesn’t use hdfs and reads and writes directly to hard disk
- pseudo distributed - only one machine that can run both master and slave, uses hdfs
- distributed - minimum 4 nodes are needed, for production workloads
- map is run on all slave nodes, reduce is run to aggregate the results from all these slave nodes
- each machine is said to hold a split of the data
- the mapper function would be called once per split - so mappers of different splits would run in parallel
- for hadoop to work, each row of data should be processable independently and out of order
- the mapper outputs a key value pair
- while map is called for all rows, reduce is called once for each key, which is why the input of reduce contains an iterable
- one confusion i had cleared? - don’t think of this map and reduce like in arrays (or even spark?). we are using
context.write, so output of both map and reduce can contain as many elements as we want, just that map would be called once per data element, while reduce once per key along with all the values for that key. the data structure which allows multiple items for the same key is called multi bag - so, in between the map and reduce, there is a shuffle that happens bts to help group results of map by key
- since a reduce can only run on one slave node at a time, all values for a key need to be first brought into one slave node during shuffle
- understand that output type of key / value of map = input type of key / value of reduce
- all the keys that go to a reducer are sorted by default
- number of mappers = number of splits of data. we cannot configure the number of mappers
- number of reducers by default is 1. in this case, outputs of all mappers are collected, sorted by key and then sent grouped by key to send one by one on a key wise basis to the reducer
- internally, after map process, each key is assigned to a partition
- number of partitions = number of reducers
- so, basically after map, the assigning of a partition to a key helps determine which reducer a key should go to
- the partition that an item should go to is determined based on its key - something like (consistent_hash(key) % number of partitions). so, items with the same key cannot go to different reducers
- while doing this, we should avoid skews / hot partitions
- after the partition is determined via partitioning, the shuffle phase helps get the output of map to the right partition
- finally, the items that arrive at a partition are sorted and then grouped by key, so that the reducer can get (key, iterable of values)
- remember that while the same key cannot go to different partitions, multiple keys can go to the same partition. this is why we need the sort + group operations
- we can hook into partitioning, sorting and grouping phase - helps achieve secondary sorting, joining, etc. discussed later
Combiners
- to reduce the overhead of shuffle, we can add a combiner - this means before shuffling, first combine the outputs of map on a single node
- e.g. if for word count, instead of shuffling, we can first ensure we reduce at the slave node level. this way, a key would be present at most once in one slave node. this reduces the amount of data to shuffle
- we can use the same class for combiner and reducer if we want
- combine may or may not run. e.g. if hadoop feels the amount of data is too less, the combine operation might not run. so, following points are important -
- our combine operation should be optional i.e. we should be sure that even if our combine operation does not run, our results stay the same. e.g. we want to find out all the words that occur 200 or more times. we can only add the values for a key in a combiner. writing the word to the context based the condition that it occurs 200 or more times can only stay inside the reducer since at that point, the reducer has all the values. basically, it might happen that one worker’s combine sees count as 150 for a particular word and another worker’s combiner sees count as 60 for the same word
- input and output format of combine operation should be same so that whether it runs or not makes no difference (and of course these types should also be the same as output of map and input of reduce)
- so, the entire process looks like this? - map -> combine -> partition -> shuffle -> sort -> group -> reduce
HDFS Commands
- hdfs - hadoop distributed file system
- to list all folders and files in hdfs recursively -
hdfs dfs -ls -R /. this command works with folders as well i.e. at the end, specify a custom path instead of / - use
hdfs dfs -put first-speech.txtto put a file into hadoop. it is placed in /user/shameek (inside hdfs) by default, else specify the custom path at the end of the command - get a file from hdfs into local -
hdfs dfs -get first-speech.txt - read the output from hdfs directly instead of copying it to local first -
hdfs dfs -cat output/part-r-00000 - change permissions -
hdfs dfs -chmod 777 ExamScores.csv - cp copy a file from one location to another inside hdfs -
hdfs dfs -cp ExamScores.csv ExamScores2023.csv - moving file from one location to another inside hdfs -
hdfs dfs -mv ExamScores.csv ExamScores2021.csv - browse the file system using gui - go to http://localhost:9870/ -> utilities -> browse the file system
HDFS Architecture
- hdfs - hadoop distributed file system
- hdfs is used for terabytes and petabytes of data
- name node is a daemon running on master
- data nodes are daemons running on slave nodes
- name node maintains metadata e.g. which file is stored where. recall how file is stored in distributed mode, replicated mode, etc. these records are maintained in the form of metadata in the name node
- e.g. if we have a file of 300mb. we submit it to the name node, which would then break the file into splits or blocks of 128mb (default), so 128mb + 128mb + 44mb and stored in different slave nodes, so that they can be processed in parallel
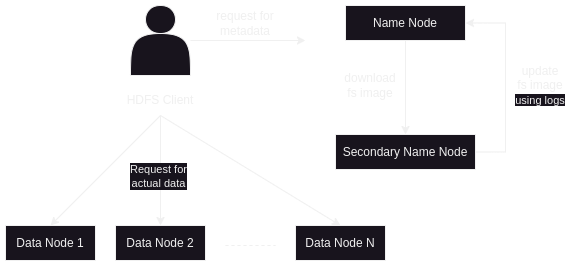
- secondary name node and name node - secondary name node has something called “edit logs”. to me, this feels like transaction logs in database i.e. all changes are continuously recorded in the edit logs of the secondary name node. the “fs image” is present on the name node, which is like the current snapshot of the system, e.g. the chunks of file described above is present in data node 1, data node 2 and data node 7. as changes happen continuously, e.g. we add / remove / modify files etc, the changes come up in the edit logs of the secondary name node. the secondary name node then periodically looks and then modifies the fs image of the name node to reflect the current state of the system
- hadoop 2.x onwards, a standby name node is present as well. so, hadoop 1.x has a single point of failure unlike hadoop 2.x
- hdfs client - gets the metadata from name node and accordingly requests data nodes for the data i.e. -
- hdfs client asks name node where the data is / tells name node it wants to store file x
- name node responds with how to store file / where the file is stored
- hdfs client then accordingly interacts with data nodes
![hdfs architecture]()
- my understanding - why the above breaking might be needed - e.g. if name node directly responded to the hdfs client by gathering data from data nodes, entire point of distributing data is lost
- because of this distributed nature of data, there is a checksum present on the name node metadata, and the hdfs client itself calculates the checksum from the data it gathers from the data nodes. these two checksums are compared to verify integrity of data
- data nodes also send heartbeats to the name node periodically
Resource Management Architecture
Hadoop 1.x
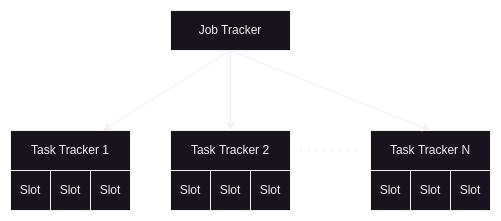
- job tracker - daemon located in master, this is where we submit the map reduce jobs via hdfs client
- the job tracker then breaks the job into multiple tasks and submits to task tracker
- task trackers run on the slave nodes. there can be multiple instances of task trackers running on a single slave node
- rack awareness - name node is rack aware i.e. for e.g. client is directed to the closest data node where the data might be present out of all the data nodes having the replicated data. (recall kafka had something similar)
- just like name node vs data node in hdfs, here, the job tracker is a daemon running on master node while the task tracker is a daemon running on slave nodes
- multiple slots can be present on a slave node - understand how a server can be multi core and therefore, perform multiple tasks at a time
- so, these slots are basically jvms which run slices of work
Issues
- hadoop 2.x and 3.x are similar, just performance improvements
- hadoop 1.x vs hadoop 2.x - in hadoop 1.x, cluster resource management and data processing both is done by map reduce framework. in hadoop 2.x, cluster resource management has been delegated to yarn (yet another resource negotiator), while map reduce framework is only responsible for data processing. the underlying storage continues to be hdfs in both versions
- so, map reduce in hadoop 1.x = map reduce (data processing) + yarn (resource management) in hadoop 2.x
Hadoop 2.x
- so now, map reduce is just used for data processing, while cluster resource management is done by yarn
- so, map reduce, spark, etc sit on top of yarn, while hive, pig, etc sit on top of map reduce
- it does things like -
- resource management
- assigning tasks to nodes that have sufficient resources
- rescheduling failed tasks to new nodes
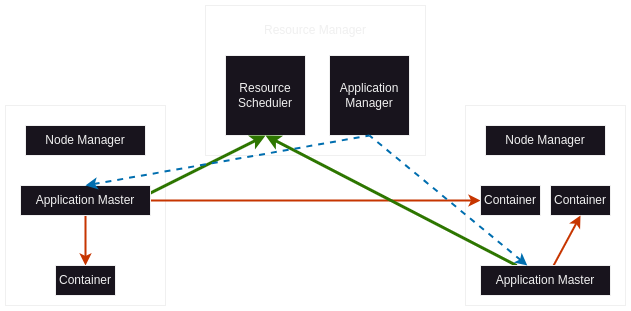
- yarn has two components - resource manager and node manager
- resource manager runs on master
- resource manager has two components - resource scheduler and application manager
- resource scheduler does not deal with any logic around retrying etc, it just cares about assigning of resources (like ram, etc) based on availability
- application manager is responsible for spinning up application masters
- now, when we submit a job, the resource manager with the help of its two components, spins up an application master
- understand that application master is like another container running on a worker node, it is not like a daemon running on master node perennially. so, the application master is scoped to the lifecycle of the application
- now, the application master coordinates with resource scheduler of resource manager to spawn containers that can execute our map / reduce tasks
- containers execute our actual tasks
- a node can have multiple containers, just like in hadoop1.x, multiple slots could be present on a slave node
- the node manager sends heartbeats for health monitoring of node (recall how in hdfs, data nodes do the same thing)
- note - master node is also called as the controller node
- are all the components listed below - resource manager, node manager, resource scheduler, application master, application manager, container, basically components of yarn and map reduce?
- location constraint - to avoid a lot of data transfer over the network, execute the tasks on the node which is the closest to the data
- so two different things? - location constraint - schedule work on node having data and rack awareness - if for e.g. there is replication, direct node to closest replica
- now, we know that there can be multiple containers being concurrently executed on this node until all its resources are not used up. if more jobs are spawned, the jobs would have to wait in a queue
- how these containers / tasks get scheduled on the node is determined by the scheduling policy -
- fifo scheduler - first in first out scheduler. e.g. assume a job takes 5 minutes, and uses up all the resources of this node. a new job that is submitted almost immediately after this job, and takes say 10 seconds, will still have to wait for the entire duration of 5 minutes till the first job is complete, since there are no resources available for this second job to execute
- capacity scheduler - divide all the resources into multiple parts, e.g. give 30% of the resources to promotional and remaining 70% to searching. this way, both these parts will individually act as fifo schedulers, but a short promotional workload will not be stalled by long running searching and indexing jobs. this is the default and usually preferred one. by default, only one queue is present - default, with 100% of the capacity
- fair scheduler - accept all jobs, and as more jobs come in / go out, allocate each of them equal amount of resources
Hadoop Streaming
- a utility that helps write map reduce programs in non java languages like python, r, etc
- e.g. of using hadoop streaming on my local -
hadoop jar ~/hadoop-3.3.6/share/hadoop/tools/lib/hadoop-streaming-3.3.6.jar -files wordcount_mapper.py,wordcount_reducer.py -mapper wordcount_mapper.py -reducer wordcount_reducer.py -input wordcount_input -output output. here wordcount_mapper and wordcount_reducer are just simple python programs. we read from the input file wordcount_input, mapper outputs to stdout which is then used as input for wordcount_reducer and finally the reducer’s output is stored inside output/part-00000 - wordcount_mapper.py -
#!/usr/bin/python3 import sys for line in sys.stdin: # for all lines words = line.split() # grab all words for word in words: # for all words print ('{0}\t{1}'.format(word, 1)) # output (word, 1) - wordcount_reducer.py
#!/usr/bin/python3 import sys prev_word = None prev_count = 0 word = None for line in sys.stdin: # for all (word, 1) line = line.strip() word, count = line.split('\t') count = int(count) if word == prev_word: prev_count += count # add to previous word count else: # if current word is not the same as last word if prev_word: print('{0}\t{1}'.format(prev_word, prev_count)) # print previous word prev_word = word # update previous word prev_count = count if prev_word == word: print('{0}\t{1}'.format(prev_word, prev_count))
mrjob
- developed by yelp
- makes it much easier to write and work with map reduce in python - things like chaining jobs etc. become much easier
- we just write one file using clean coding principles unlike using two files like specified in hadoop streaming
- allows writing tests locally (i.e. without support around hdfs etc)
- even aws emr etc work with mrjob
WordCount Example
- initial pom.xml
- run
mvn clean package - command to submit job -
~/hadoop-3.3.6/bin/hadoop jar ./target/hadoop-1.0-SNAPSHOT.jar org.example.One input output - visit status of job at http://localhost:8088/cluster/apps
- note - for most classes, i find there are two packages we can import from - mapred and mapreduce. we should try using mapreduce where possible
- a basic example for word count -
public class One { public static class MapClass extends Mapper<LongWritable, Text, Text, LongWritable> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { String body = value.toString().toLowerCase().replaceAll("[^a-z\\s]", ""); String[] words = body.split(" "); for (String word : words) { if (word.length() >= 7) { context.write(new Text(word), new LongWritable(1)); } } } } public static class Reduce extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { long sum = 0L; for (LongWritable longWritable : values) { sum += longWritable.get(); } context.write(key, new LongWritable(sum)); } } public static void main(String[] args) throws Exception { Path in = new Path(args[0]); Path out = new Path(args[1]); Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); try { FileSystem hdfs = FileSystem.get(configuration); hdfs.delete(out, true); } catch (Exception ignored) { } job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); job.setMapperClass(MapClass.class); job.setCombinerClass(Reduce.class); job.setReducerClass(Reduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.setInputPaths(job, in); FileOutputFormat.setOutputPath(job, out); job.setJarByClass(One.class); job.submit(); } } - the mapper and reducer classes that we extend are generics, where the types are for the key and value of input and output respectively
- we also recursively delete the output folder because if we rerun jobs without doing this, there is a failure around folder already exists
- the output format has files like part-r-00000, where r indicates that the output is due to a reduce operation and the last number is the partition id
- recall how by default, number of reducers is 1. to change the number of reducers, simply write
job.setNumReduceTasks(2) - e.g. in this case, i see two files in the output folder - part-r-00000 and part-r-00001
- built in functions - e.g. map reduce ships with a
LongSumReducerwhich we could have used here - sum for each key, where the value is long - my confusion cleared -
setOutputKeyClassandsetOutputValueClassare used for reducer outputs, whilesetMapOutputKeyClassandsetMapOutputValueClassare used for map outputs. i think there are some times when we do not need to include the map ones, but i think i might as well just include all of them every time tbh
Constructing Map Reduce Logic
Numeric Summary Metrics
e.g. imagine we have a list of rows, where each row has a subject name and score obtained by any student. we want to calculate the average score for each subject
subject marks chemistry 75 mathematics 81 chemistry 79 - constructing map reduce logic - since we want to group based on subject, output key of map should be subject. the numerical statistic that we want to perform, e.g. average in this case, can be done inside the reducer
- so, remember - map’s job is to output the right key, and reduce’s job is to output the right value based on all the values available for a key
- our map would try to make a key for the subject name, and output the marks as the value
- our reduce would just run (sum of all values / size of list of values)
- if we use the combiner as the same function that was used for reducer - e.g. if one node had 55 and 65 for chemistry, and another node had 75 for chemistry, the right average would be 65, but in our case, the combiner would output be 60 on node 1 and 75 for node 2, thus making the reducer output to be 67.5
- recall how output of map = input of combiner = output of combiner = input of reducer. so, we can instead output a tuple as the value from the map as (marks, 1). combiner can then output (sum of marks, size). this way, the reducer now receives a list of tuples, and it has to add the first value of tuples for the total and divide it by the sum of second values of the tuple for the final average
- if we want to use custom data types - for keys, we must implement the
WritableComparibleinterface, while the data types used for values must implement theWritableinterface - we need to write implementation of things like serialization and deserialization. hadoop input and output classes have helpers for this, e.g.
readUTF/writeUTFfor strings,readDouble/writeDoublefor doubles, etc- remember to keep the order of serialization and deserialization to be the same
- remember to keep a no args constructor (used by hadoop internally)
- so, we would need an extra class to store the total marks and number of students with that marks, if we want to use combiners
public static class MapClass extends Mapper<LongWritable, Text, Text, AverageWritable> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, AverageWritable>.Context context) throws IOException, InterruptedException { String[] record = value.toString().split(","); context.write(new Text(record[0]), new AverageWritable(Long.parseLong(record[1]), 1L)); } } public static class Combine extends Reducer<Text, AverageWritable, Text, AverageWritable> { @Override protected void reduce(Text key, Iterable<AverageWritable> values, Reducer<Text, AverageWritable, Text, AverageWritable>.Context context) throws IOException, InterruptedException { long count = 0; long score = 0; for (AverageWritable value: values) { score += value.getTotal(); count += value.getNoOfRecords(); } context.write(key, new AverageWritable(score, count)); } } public static class Reduce extends Reducer<Text, AverageWritable, Text, DoubleWritable> { @Override protected void reduce(Text key, Iterable<AverageWritable> values, Reducer<Text, AverageWritable, Text, DoubleWritable>.Context context) throws IOException, InterruptedException { long count = 0; long totalScore = 0; for (AverageWritable value: values) { totalScore += value.getTotal(); count += value.getNoOfRecords(); } context.write(key, new DoubleWritable((totalScore * 1.0) / count)); } } - the custom data type AverageWritable looks like below -
@NoArgsConstructor @AllArgsConstructor @Data public class AverageWritable implements Writable { private long total; private long noOfRecords; @Override public void write(DataOutput out) throws IOException { out.writeLong(total); out.writeLong(noOfRecords); } @Override public void readFields(DataInput in) throws IOException { total = in.readLong(); noOfRecords = in.readLong(); } }
Filtering
- e.g. if we want to filter the data based on a condition, we can perform the filtering in the map function, and the reduce can just be an identity function
- e.g. if we make the output key of the map function as null, all the items would be received by the reducer in one go and it can write out all the items at once
- notice the use of singleton for
NullWritableto reduce memory usedpublic class MapClass extends Mapper<LongWritable, Text, NullWritable, Text> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, Text>.Context context) throws IOException, InterruptedException { String row[] = value.toString().split(","); if (row[2].equalsIgnoreCase("Books")) { context.write(NullWritable.get(), value); } } } - we do not call
setReducerClassso that the identity reducer can kick in. identity reducer = a reducer that will just callcontext.write(key, value)for all the values that it receives -job.setMapperClass(MapClass.class);
Distinct Values
- if we want the distinct values, e.g. something that works like the
distinctclause in sql - we have a file with a word in every new line, and we would like to find a list of all the distinct words
- we can again use null writable instead of outputting dummy values like 1 for performance
- map class -
public class MapClass extends Mapper<LongWritable, Text, Text, NullWritable> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { context.write(value, NullWritable.get()); } } - understand how the reducer here is not exactly identity - it would output one value for a key, not multiple like in the above example of filtering. reducer / combiner -
public class Reduce extends Reducer<Text, NullWritable, Text, NullWritable> { @Override protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } } - note - the output was in sorted order - recall why this happens due to the sorting after the shuffle process
Top N Records
e.g. each row has user id and their number of followers, and we want to show the top n users
user_id followers 1 30 2 30000 3 20 5 50 6 6000 - my understanding - solution 1 - output key as null for all rows, so one reducer gets all the rows. there is a bottleneck here, since we cannot have more than one reducer for top n records
- all mappers work on subsets of data
- e.g. we can get all mappers to find the top n of the data they are responsible for
- note - it can happen that the mappers output less than n if the data that they have is small
- for a mapper to output top n records, it can do so only after all records in the partition it is responsible for have been processed, because mappers are called once per record for all records in the split it is responsible for -
cleanup - note - we have written the user for ascending order - priority queue will have the user with the lowest number of followers at the top. so, we just try to ensure priority queue size doesn’t go over three, and that incoming element just needs to be larger than that whats at the top of the priority queue (i.e. smallest in the priority queue)
- we use User as output of map, so we could have just implemented writable, but we implement writable comparable so that we can use its compare to function, used by priority queue -
@Data @AllArgsConstructor @NoArgsConstructor public class User implements WritableComparable<User> { private String userId; private Integer numberOfFollowers; @Override public void write(DataOutput out) throws IOException { out.writeUTF(userId); out.writeInt(numberOfFollowers); } @Override public void readFields(DataInput in) throws IOException { userId = in.readUTF(); numberOfFollowers = in.readInt(); } @Override public int compareTo(User o) { return numberOfFollowers - o.getNumberOfFollowers(); } } - map -
@Slf4j public class MapClass extends Mapper<LongWritable, Text, NullWritable, User> { private final PriorityQueue<User> pq = new PriorityQueue<>(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, NullWritable, User>.Context context) throws IOException, InterruptedException { String[] row = value.toString().split("\t"); User user = new User(row[0], Integer.parseInt(row[1])); if (pq.size() < 3 || pq.peek().getNumberOfFollowers() < user.getNumberOfFollowers()) pq.add(user); if (pq.size() > 3) pq.poll(); log.info("pq is [{}], user is [{}]", pq, user); } @Override protected void cleanup(Mapper<LongWritable, Text, NullWritable, User>.Context context) throws IOException, InterruptedException { while (!pq.isEmpty()) { log.info("writing user [{}]", pq.peek()); context.write(NullWritable.get(), pq.poll()); } } } - in mapper - above, we used cleanup of mapper. this technique is called in mapper. it is an alternative to, and sometimes more optimal than combiners
- in case of combiner, the mapper would write to files, then the combiner would read from and again write to the files
- in case of in mapper, we do everything in memory using for e.g. priority queue here. so while there is memory overhead, it is more optimal from performance pov
- lets say for all these n values, the mappers output the same key, say null
- now, all map outputs can come into the same list into a reducer this way
- so, the reducer basically receives the combination of top n outputs of all mappers
- note - for this to work, we had to use a single reducer
- here cleanup is not needed like in map, since reducer itself will get all the values
- note - a weird thing i have experienced here -
pq.add(value)changes everything in priority queue to whats added the last time to the priority queue - like a pass by reference vs value thing, but why? however, cloning the user i.e.pq.add(new User(value.getUserId(), value.getNumberOfFollowers()));fixed the issue@Slf4j public class Reduce extends Reducer<NullWritable, User, NullWritable, User> { @Override protected void reduce(NullWritable key, Iterable<User> values, Reducer<NullWritable, User, NullWritable, User>.Context context) throws IOException, InterruptedException { PriorityQueue<User> pq = new PriorityQueue<>(); for (User value : values) { if (pq.size() < 3 || pq.peek().getNumberOfFollowers() < value.getNumberOfFollowers()) { pq.add(new User(value.getUserId(), value.getNumberOfFollowers())); } if (pq.size() > 3) pq.poll(); log.info("pq is [{}], user is [{}]", pq, value); } while (!pq.isEmpty()) { log.info("writing user [{}]", pq.peek()); context.write(NullWritable.get(), pq.poll()); } } } - so, the obvious bottleneck is that we are limited to using just one reducer
- we know that one reducer receives all the keys that it is responsible for in sorted order
- however, this order breaks across reducers - e.g. reducer 1 receives (a,5), (d,6), (w,5), while reducer 2 receives (b,2), (c,5), (e,7). the output from the two reducers are sorted at an individual level, but this order breaks when combined
- with “total order partitioning” (not discussed here), the idea is that the reducer 1 receives (a,5), (b,2), (c,5), while reducer 2 receives (d,6), (e,7), (w,5), i.e. we are ensuring keys received across reducers are ordered as well
- intuition - maybe because in the normal process, sorting anyways happens at a partition level, after the shuffle process. but here, the idea is for data to be sorted across the partitions as well, and hence the “total”
- if we implement a custom partitioner, a naive way would be send letters a-j to partition 1, k-r to partition 2 and s-z to partition 3. while this does ensure even distribution in terms of the number of keys, this can mean uneven distribution since there can be hot keys. all of this is handled by the total order partitioner
Indexes
- search engines periodically visit websites and store the text in their own database - they create an index
- web pages are crawled repeatedly for all the data to build an index and keep it updated
- then, when a user initiates a search, these engines search through their own index instead of going to the websites
- inverted indexing - search engines generate an index based on the contents of the websites. e.g. mango is contained in files 1 and 3, war in files 1 and 5 and so on. the input was just files, while the output has the key as word, the value as the files containing this word. this structure is called an inverted index
- analogy behind inverted index - website themselves are an index - we type in a url and get back the content. the key is the url and the value the content. however, we generate an inverted index by using content as keys and the urls as values, so that for a search term, we know what urls may contain relevant information to it
- tf - term frequency - number of times a word appears in a document / total number of words in the document. e.g. if mango appears 5 times in a document with 1000 words, tf = 0.005
- while calculating the tf, all words are considered equally important, so to help scale the rare words up, we use idf i.e. rare words across documents are bumped up
- idf - inverse document frequency - log (total number of documents / number of documents having the word). e.g. if 1,000 files have the word we are searching for out of 1,000,000, idf = 3
- so, we would want the value of tf * idf to be high for our website to come up on the top
- so, all these calculations around building indexes from huge amounts of raw data (websites) very fast using distributed processing is what big data helps with
- a simple way of achieving this - we know that our output should contain the word as key and list of urls containing it as output. so, the map should output for all words on the page, that word as the key the url as value. now, the reducer receives all the urls for a word
File Formats
- file formats - used when we wrote the following bit of code -
job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); - the different possible options for input formats are -
TextInputFormat- file contains only values. key is line number, which is why we were usingLongWritablefor key of map till now everywhereKeyValueTextInputFormat- used when input file contains key as wellSequenceFileInputFormat- uses compression, useful when we chain map and reduce jobs i.e. input of the second job is the output from the first jobNLineInputFormat- recall how by default file is split into segments of 128mb each. this way, for e.g. if we have 6 slave nodes and only a 500mb file, we cannot use all our slave nodes properly. this is where this option is useful, whereby we can specify the number of lines that should go into per split, thus helping us utilize our cluster more effectively
- the different possible options for output formats are -
TextOutputFormat- each line has the key and value separated by a tabSequenceFileOutputFormat- uses compression, useful when we chain map and reduce jobs
- so for e.g. for the exams example discussed in the section before, the format of a line was for e.g. Chemistry,79. so, we can use the
KeyValueTextInputFormatclass for it as follows i.e. note how the map doesn’t have to extract the key by using split on the value like earlier. note - specify the separator as well, since tab is the default -public static class MapClass extends Mapper<Text, Text, Text, AverageWritable> { @Override protected void map(Text key, Text value, Mapper<Text, Text, Text, AverageWritable>.Context context) throws IOException, InterruptedException { context.write(key, new AverageWritable(Long.parseLong(value.toString()), 1L)); } } // ... configuration.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", ","); job.setInputFormatClass(KeyValueTextInputFormat.class);
Chaining Jobs
e.g. imagine we have data in the following format i.e. each row has marks obtained for a student - the school that student is from and the subject. for all subjects, we would like to obtain the school with the highest average, and the actual average
school subject marks Bigtown Academy Chemistry 44 Bigtown Academy French 69 Mediumtown College Biology 61 Largetown School French 67 - so, we can break the problem as follows into two separate map reduce jobs -
- first job’s map output - key = (school, subject), value = (marks, 1) (recall the value is this strange tuple because of the constraint when using combiners around types)
public static class MapClass extends Mapper<LongWritable, Text, ExamScoresV2KeyWritable, AverageWritable> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, ExamScoresV2KeyWritable, AverageWritable>.Context context) throws IOException, InterruptedException { String[] record = value.toString().split(","); ExamScoresV2KeyWritable newKey = new ExamScoresV2KeyWritable(record[0], record[1]); AverageWritable averageWritable = new AverageWritable(Long.parseLong(record[2]), 1L); context.write(newKey, averageWritable); } } - first job’s combiner output - key = (school, subject), value = (sum of marks, total students)
public static class Combine extends Reducer<ExamScoresV2KeyWritable, AverageWritable, ExamScoresV2KeyWritable, AverageWritable> { @Override protected void reduce(ExamScoresV2KeyWritable key, Iterable<AverageWritable> values, Reducer<ExamScoresV2KeyWritable, AverageWritable, ExamScoresV2KeyWritable, AverageWritable>.Context context) throws IOException, InterruptedException { long count = 0; long score = 0; for (AverageWritable value: values) { score += value.getTotal(); count += value.getNoOfRecords(); } context.write(key, new AverageWritable(score, count)); } } - first job’s reducer output - key = (school, subject), value = average of the school in the subject
public static class Reduce extends Reducer<ExamScoresV2KeyWritable, AverageWritable, ExamScoresV2KeyWritable, DoubleWritable> { @Override protected void reduce(ExamScoresV2KeyWritable key, Iterable<AverageWritable> values, Reducer<ExamScoresV2KeyWritable, AverageWritable, ExamScoresV2KeyWritable, DoubleWritable>.Context context) throws IOException, InterruptedException { long count = 0; long score = 0; for (AverageWritable value: values) { score += value.getTotal(); count += value.getNoOfRecords(); } context.write(key, new DoubleWritable(score * 1.0 / count)); } } - second job’s map output - key = subject, value = (school, its average for that subject). however, notice how it can read directly the key from the output of the earlier job, so we can also set the input format on the job directly as
job.setInputFormatClass(KeyValueTextInputFormat.class)public static class MapClass extends Mapper<Text, Text, Text, SchoolAverageWritable> { @Override protected void map(Text key, Text value, Mapper<Text, Text, Text, SchoolAverageWritable>.Context context) throws IOException, InterruptedException { String[] record = key.toString().split(","); context.write(new Text(record[1]), new SchoolAverageWritable(record[0], Double.parseDouble(value.toString()))); } } - second job’s combiner output - key = subject, value = (school with maximum average for the subject, the average)
public static class Reduce extends Reducer<Text, SchoolAverageWritable, Text, SchoolAverageWritable> { @Override protected void reduce(Text key, Iterable<SchoolAverageWritable> values, Reducer<Text, SchoolAverageWritable, Text, SchoolAverageWritable>.Context context) throws IOException, InterruptedException { SchoolAverageWritable max = new SchoolAverageWritable(null, -1); for (SchoolAverageWritable value: values) { max = max.getAverage() > value.getAverage() ? max : new SchoolAverageWritable(value.getSchool(), value.getAverage()); } context.write(key, max); } } - second job’s reducer output - same as above
- so, the entire thing has been broken down into two jobs, which can be run one after another
- while we can run manually, hadoop can help achieve this via code using “job control”
Configuration configurationOne = new Configuration(); Configuration configurationTwo = new Configuration(); ControlledJob controlledJobOne = new ControlledJob(configurationOne); ControlledJob controlledJobTwo = new ControlledJob(configurationTwo); // notice how input of second job = output of first job // these static calls of getJob do stuff like setting types on job, // setting inputs and outputs, setting mappers, calling jarByClass, etc // all of which we have seen earlier Job jobOne = FiveJobOne.getJob(configurationOne, new Path(args[0]), new Path(args[1])); Job jobTwo = FiveJobTwo.getJob(configurationTwo, new Path(args[1]), new Path(args[2])); controlledJobOne.setJob(jobOne); controlledJobTwo.setJob(jobTwo); // adding dependency controlledJobTwo.addDependingJob(controlledJobOne); JobControl jobControl = new JobControl("SchoolWithHighestAverage"); jobControl.addJob(controlledJobOne); jobControl.addJob(controlledJobTwo); // some thread stuff we have to do // when running controlled jobs Thread thread = new Thread(jobControl); thread.setDaemon(true); thread.start(); while (!jobControl.allFinished()) { Thread.sleep(500); } - now recall how if chaining jobs, we can make use of compression - we can notice this if we try to run
caton the intermediate outputs (i.e. what we specify usingarg[1]above)// inside job 1 - job.setOutputFormatClass(SequenceFileOutputFormat.class); // inside job 2 - job.setInputFormatClass(SequenceFileInputFormat.class); - the caveat of the above is output format of key / value of reduce of first job = input format of key / value of map of second job, which was not really needed otherwise if not using compression i.e. we could write double from reduce, and while reading read as string and parse this string into double
- my doubt - since max is needed, could we have used secondary sorting? is secondary sorting usually more optimal for finding maximum?
Pre and Post Processing
- pre and post processing - to perform some steps after and before the job
- these pre and post processing steps work just like map tasks
- so the effective structure of hadoop can be said to be as follows
- multiple maps in the form of pre processing
- the actual map
- an optional combiner
- the shuffle step done by hadoop internally which then helps run reduce
- the reduce on a per key basis
- multiple maps in the form of post processing
- so, the structure when using pre and post processing looks like follows i.e. this replaces the
job.setMapperetc calls - (the 4 types in between are for input key class, input value class, output key class and output value class). note - i think for adding combiner however, like stated below, i had to go back tojob.setCombinerClass// pre processing ChainMapper.addMapper(job, PreProcessing.class, Text.class, Text.class, Text.class, Text.class, confOne); // the actual map, but syntax is same ChainMapper.addMapper(job, MapClass.class, Text.class, Text.class, Text.class, AverageWritable.class, confTwo); // combiner job.setCombinerClass(Combine.class); // reducer (note how it is setReducer and not addReducer like addMapper, since only one reducer can be used) ChainReducer.setReducer(job, Reduce.class, Text.class, AverageWritable.class, Text.class, DoubleWritable.class, confTwo); // post processing ChainReducer.addMapper(job, PostProcessing.class, Text.class, DoubleWritable.class, Text.class, DoubleWritable.class, confTwo);
Optimization
- optimizing disk io in hadoop - in hadoop, the file is read from / written to disk at each step
- reduce size using pre processing - e.g. drop extraneous data
- use sequence file formats
- optimize the file itself before sending it to hadoop - e.g. xml would be much worse to process due to extra lines of tags compared to something like csv
- optimizing network io - this happens during shuffle
- add a combiner
- order input data using keys beforehand so that there is less network required during shuffling
- optimizing processing - this is more “code based”
- if we have to create something like
new LongWritable(1)in the map class for e.g. in word count, we can instead create it at the global class level and reference it in the map task. this way, we don’t create a new object every time, thus saving up on time for creation of these objects and more importantly garbage collection time - use string builders instead of string if strings change frequently
- there is some time spent in instantiating a jvm. a new jvm is created for each task in a job by default, e.g. imagine a chain of mappers initially when using pre processing. however, we can reuse jvm across these tasks. we should observe how garbage collection works after this optimization.
conf.set("mapreduce.job.jvm.tasks", "10"). 10 means reuse jvm for 10 tasks, 1 is the default i.e. 1 jvm per task and setting it to -1 means use one jvm for all tasks. note - this jvm reuse can only happen in a job, not across jobs - recall why and how n line input format can be useful
- null writable - when we are just interested in the key (e.g. find the most frequently occurring words), and not the value, instead of using a dummy value like
new Text(""), we can instead useNullWritable.get(), and notice how this is using singleton pattern, thus matching the first point of this section optimizing processing
- if we have to create something like
- logging - this can be useful for for e.g. pseudo distributed, in standalone i can see the logs directly in the console as well. to view the logs, go to http://localhost:8088/cluster -> tools -> local logs -> userLogs. this will have a link to all job logs. go to the last job we ran -> and now this will have logs for all containers. i was just using lombok’s
@Slf4jand could automatically see the logs properly without any extra configuration - hadoop also shows something called counters in ui, and this can be very useful for the health of job. we can add custom counters to it. we simply need to do is as follows (note - we have to use an enum i think)
enum RemovedRows { LOW_SCORES, INVALID_DATA } context.getCounter(RemovedRows.LOW_SCORES).increment(1); - relational databases - we usually deal with files in hadoop because relational databases cant cope with massive amounts of data. yet we can read from / write to (preferable because this data is usually much smaller than input) relational databases
- when reading from database, each map task (remember how in production we will have multiple slave nodes etc) will initiate a read from the database. this can overload the database with jdbc connections (db proxy is the solution here?)
Unit Testing
- mrunit - unit testing out map reduce code
- ps - this did not work for me, basically mrunit was relying on mapred versions and not mapreduce? however, written the code snippet below for reference
- adding the dependency - (note - i had to add the classifier for this to work) -
<dependency> <groupId>org.apache.mrunit</groupId> <artifactId>mrunit</artifactId> <version>1.1.0</version> <scope>test</scope> <classifier>hadoop2</classifier> </dependency> MapDriver,ReduceDriver,MapReduceDriver- it is as simple as us specifying the class we used e.g. for mapping we use MapClass, then specify the input and the expected output, and call runTest on these drivers to perform the assertionpublic class TwoTest { MapDriver<Text, Text, Text, AverageWritable> mapDriver; @Before public void setUp() throws Exception { mapDriver = MapDriver.newMapDriver(new Two.MapClass()); } @Test public void test() throws IOException { mapDriver.addInput(new Text("chemistry"), new Text("79")); mapDriver.addInput(new Text("chemistry"), new Text("91")); mapDriver.addInput(new Text("mathematics"), new Text("67")); mapDriver.addOutput(new Text("chemistry"), new AverageWritable(79, 1)); mapDriver.addOutput(new Text("chemistry"), new AverageWritable(91, 1)); mapDriver.addOutput(new Text("mathematics"), new AverageWritable(67, 1)); mapDriver.runTest(); } }
Secondary Sorting
- each node can have multiple partitions (which are recall 128 mb in size)
- now, for reduce to work, values for a key need to go to the same partition
- because of the way the shuffle process works, the values for a key in the reduce process come in random order
- now, imagine we want the values for a key to be in sorted order as well to for e.g. find the maximum
- one way can be we simply find the maximum by looping over all elements (
O(n)), since we already have all the values for that key - inefficient - so, we do something called secondary sorting
- now, we would like to ensure that the reducer gets the iterable of values in sorted order. so, here is how we can achieve it -
- construct a key where key = (actual_key, value) in the map process
- write a custom partitioner so that the partition is determined only using the actual_key part of the key (
Partitioner#getPartition) - ensure sort takes into account the key as is, so both (actual_key, value) are used (
WritableComparable#compareToi.e. present inside our custom key class) - ensure group takes into account only the actual_key part of the key (
WritableComparator#compare)
- so, example of an implementation of secondary sorting - imagine we have a csv, where each row has the subject name and the marks obtained by a particular student in it. we want highest score for each subject. so, we need to sort by both subject and marks, but use only subject for partitioning and grouping. so, the key would be a tuple of (subject, marks). we can also have a combiner that works just like the reducer, except that it needs to input and output the same tuple of (subject, maximum marks) (maximum needs to consider data across all nodes, but maximum from every node is sufficient for evaluating this)
- one point i thought about - we are not necessarily changing the time complexity by a lot here - partitioning, sorting, grouping etc would anyway have happened - we are just changing the keys that are used by customizing these operations a bit
- custom key - also determines how to sort, which uses first subject and then score (descending). so, items for a specific key (subject) are sorted by values (marks in descending)
@Data @AllArgsConstructor @NoArgsConstructor public class ExamSubjectAndScoreKey implements WritableComparable<ExamSubjectAndScoreKey> { private String subject; private Integer score; @Override public int compareTo(ExamSubjectAndScoreKey o) { int result = subject.compareTo(o.subject); return result == 0 ? o.score - score : result; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(subject); out.writeInt(score); } @Override public void readFields(DataInput in) throws IOException { subject = in.readUTF(); score = in.readInt(); } } - grouping comparator, group using subject only. note - we have to add the constructor with call to super, otherwise we get a npe
public class SubjectComparator extends WritableComparator { public SubjectComparator() { super(ExamSubjectAndScoreKey.class, true); } @Override public int compare(WritableComparable a, WritableComparable b) { ExamSubjectAndScoreKey keyA = (ExamSubjectAndScoreKey) a; ExamSubjectAndScoreKey keyB = (ExamSubjectAndScoreKey) b; return keyA.getSubject().compareTo(keyB.getSubject()); } } - partitioner, partition using subject only -
public class SubjectPartitioner extends Partitioner<ExamSubjectAndScoreKey, IntWritable> { @Override public int getPartition(ExamSubjectAndScoreKey key, IntWritable score, int numPartitions) { return key.getSubject().hashCode() % numPartitions; } } - configure both partitioner and grouping comparator using -
job.setPartitionerClass(SubjectPartitioner.class); job.setGroupingComparatorClass(SubjectComparator.class); - map, combine and reduce - note how reduce and combiner are the same apart from the output format. my doubt - i thought secondary sorting only helps with reducer values being sorted i.e. how can we use
values.iterator.next()for combiner?public static class MapClass extends Mapper<Text, Text, ExamSubjectAndScoreKey, IntWritable> { @Override protected void map(Text key, Text value, Mapper<Text, Text, ExamSubjectAndScoreKey, IntWritable>.Context context) throws IOException, InterruptedException { int score = Integer.parseInt(value.toString()); context.write(new ExamSubjectAndScoreKey(key.toString(), score), new IntWritable(score)); } } public static class Combine extends Reducer<ExamSubjectAndScoreKey, IntWritable, ExamSubjectAndScoreKey, IntWritable> { @Override protected void reduce(ExamSubjectAndScoreKey key, Iterable<IntWritable> values, Reducer<ExamSubjectAndScoreKey, IntWritable, ExamSubjectAndScoreKey, IntWritable>.Context context) throws IOException, InterruptedException { context.write(key, values.iterator().next()); } } public static class Reduce extends Reducer<ExamSubjectAndScoreKey, IntWritable, Text, IntWritable> { @Override protected void reduce(ExamSubjectAndScoreKey key, Iterable<IntWritable> values, Reducer<ExamSubjectAndScoreKey, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { context.write(new Text(key.getSubject()), values.iterator().next()); } }
Joining
- imagine doing this using what we know up till now
e.g. we have a csv where each row represents an order for a customer. so, it contains customer id, date and total
customer id total 18 233.28 17 27.35 18 202.23 another csv contains a row per customer, where each row has the customer id and country of origin
customer id country 1 France 2 Russia 3 Germany - now, we would like to find totals by countries - so, we would use joins
- job 1 - map first csv into (customer id, [total, null]), identity reducer
- job 2 - map second csv into (customer id, [0, country]), identity reducer
- job 3 - the two above outputs can be combined since they have the same format, e.g. recall how we can specify not just a file but folder as well when running hadoop jobs, and the folder here would contain the outputs from both jobs above. now, we use an identity mapper, and then perform a reduce to get (country, total) for every customer. basically, in the iterable, there would be multiple values where country is null, and just one value where the country is not null but the total is 0. understand that the reducer of this job is called once for every key i.e. customer. we don’t want to output one row per customer, but one row per country - so, we need yet another job’s reduce to help us do some grouping
- job 4 - identity mapper, reduce can now just sum the totals, as the key is now country
- using secondary sorting - we would tag data from country csv with 1 and data from sales csv with 2. map would read from both files. now, we would perform secondary sorting logic - this way, we would have a dataset where the first row has key = customer_id, 1 for the country data, and following rows have key = customer_id, 2 for the sales data. we can group keys with multiple values under same reducer due to secondary sorting logic, this would output country, sum_of sales. so, the output of this first job is basically for each customer, there is a row, where the key is country and the value is total amount of sales for this customer. so, we can follow this up with a second job that has an identity mapper and a reducer to calculate the total
- so, this trick around secondary sorting basically helped us eliminate jobs 1 to 3
- we can tag the two datasets in the configuration as follows
Path in1 = new Path(args[0]); Path in2 = new Path(args[1]); Path out = new Path(args[2]); Configuration configuration = new Configuration(); configuration.set("mapreduce.input.keyvaluelinerecordreader.key.value.separator", ","); configuration.set(in1.getName(), "1"); configuration.set(in2.getName(), "2"); - the mapper can be written as follows. note how it extracts the tag and creates the new key using it, so that it can be used during the secondary sorting phase -
public static class MapClass extends Mapper<Text, Text, CustomerAndTagKey, Text> { @Override protected void map(Text key, Text value, Mapper<Text, Text, CustomerAndTagKey, Text>.Context context) throws IOException, InterruptedException { FileSplit fileSplit = (FileSplit) context.getInputSplit(); Integer tag = Integer.parseInt(context.getConfiguration().get(fileSplit.getPath().getName())); Integer customerId = Integer.parseInt(key.toString()); context.write(new CustomerAndTagKey(customerId, tag), value); } } - each mapper is responsible for a split of the data, and that file split’s name is used to tag the different files to help determine what table they belong to
- the reducer can now be certain that the first row would represent the country -
public static class Reduce extends Reducer<CustomerAndTagKey, Text, Text, DoubleWritable> { @Override protected void reduce(CustomerAndTagKey key, Iterable<Text> values, Reducer<CustomerAndTagKey, Text, Text, DoubleWritable>.Context context) throws IOException, InterruptedException { Iterator<Text> values$ = values.iterator(); String country = values$.next().toString(); double total = 0; while (values$.hasNext()) { total += Double.parseDouble(values$.next().toString()); } context.write(new Text(country), new DoubleWritable(total)); } } CustomerTagKey#compareTo- use both customer id and the tag. ensure that in the iterable received for a customer, first record contains the country, and remaining contain the totals for that customer@Override public int compareTo(CustomerAndTagKey o) { return customerId.equals(o.customerId) ? tag - o.tag : customerId - o.customerId; }CustomerPartitioner#getPartition- only use the customer id for determining the partition@Override public int getPartition(CustomerAndTagKey customerAndTagKey, Text text, int numPartitions) { return customerAndTagKey.getCustomerId().hashCode() % numPartitions; }CustomerComparator#compare- only use the customer id to group@Override public int compare(WritableComparable a, WritableComparable b) { CustomerAndTagKey keyA = (CustomerAndTagKey) a; CustomerAndTagKey keyB = (CustomerAndTagKey) b; return keyA.getCustomerId().compareTo(keyB.getCustomerId()); }- now, we need to chain another job for actually totaling across customers, already discussed
- apparently what we discussed till now is called a reduce side join, there is another type called map side join, which can be more performant in some cases, but has limitations (same as spark’s broadcast join?) -
- reduce side join - tagging datasets, so reducer gets an iterable, which has a value for each row from both datasets which are a part of the join
- map side joins - one dataset is small enough to fit in a jvm, and the join is done in map side and not in reduce side
- e.g. of map side join - we have a handful of stop words to flag in some analysis for our use case, which can easily fit in a jvm