RESHADED Approach
- it is a strategy we can use to solve problems design problems
- “requirements” - gather the requirements and scope the problem
- “estimation” - estimate the resources (hardware and infrastructure) for the number of users
- “schema” - which tables we need and what fields are part of these tables
- “high level design” - identify the main components and building blocks
- “api design” - build interfaces (typically using api calls) that allow users to interact with our systems
- “detailed design” - define the workflow, the different technologies, evolve design where applicable
- “evaluation” - discuss effectiveness and then tradeoffs
- “distinctive feature” - each design problem has unique aspects, e.g. concurrency control in google docs, wherein different users want to edit the same document simultaneously
Youtube
Functional Requirements
- stream videos
- upload videos
- search videos
- view thumbnails
- like / dislike videos
- add comments to videos
Non Functional Requirements
- latency - streaming experience should be smooth
- scalability - as the number of users increases, the storage for content, the bandwidth for streaming to multiple users simultaneously, etc should also scale accordingly
- reliability - uploaded content should not be lost or damaged
- consistency - strong consistency might not be needed for all features, e.g. all users subscribed to a creator need not get notified about new uploads by them immediately
Estimation
- daily active users - 500 million
- average length - 5 minutes
- average size - 600 mb (original), 30 mb (after compression, encoding, etc)
- size of processed video is 6 mb per minute (30 / 5)
- assuming 500 hours of video is uploaded per minute, we get total storage = 500 * 60 * 6 = 180 gb per minute
- note - storage would include several other things - thumbnail, video metadata, etc, which we may ignore, as they are much smaller in size compared to the video content. also, we might transcode the video into different formats. e.g. assuming we stored videos in 5 different qualities and average size across all of them is 6mb itself, the total size of storage becomes 900 gb
- no. of servers = assuming daily active users as no. of requests per sec, we will need 500 mil / 64 k ~= 8k servers
- size of video raw video is (600 / (5 * 60)) = 2 mb per second or 16 mbps
- so, upload bandwidth = (500 * 60 * 60 / 60) * 16 = 480 gbps
- similarly, we can calculate the bandwidth for streaming as well, assuming view:upload ratio is 300:1
Schema
- user - id, username, email, password
- channel - id, user_id, name, description, category, subscriber_count
- video - id, channel_id, title, description, upload_date, view_count, like_count, dislike_count, video_uri
- comment - id, video_id, user_id, comment_text, comment_date, like_count, dislike_count
this is a starting point, we can add more details, e.g. different qualities of videos etc
High Level Design
- client requests reach the server
- the server stores the metadata in a database
- simultaneously, the video is sent to an encoder and transcoder
- “encoding” - compressing the video
- “transcoding” - converting the video into different formats, bitrates, etc to support different devices and network conditions
- finally, this encoder sends the processed video to a blob storage
- after this, the content can be pushed to a cdn system to support streaming with low latency
API Design
upload_video- post requestuser_id- id of the uploadervideo_file- file to uploadtitledescriptiontags- helps improve search resultsdefault_language- the language shown to the user by default (for title, description, etc)privacy- videos can be public or private
- the video is broken into smaller packets and uploaded to the server. in case of failure, the user can retry and resume from where they left off
stream_video- get requestvideo_id- id of the video to streamuser_id- id of the user requesting the videoscreen_resolution- users send their screen resolution, which helps the server determine the quality of video to stream. e.g no point sending a 4k video to a user with 720p screen resolutionbitrate- transmission capacity of the user to determine which quality of video to stream for a better user experience. e.g. if the user has a low bitrate, we can send them a lower quality video to avoid bufferingdevice_chipset- the hardware capabilities of the user device, as they decode videos. e.g. older devices cannot decode newer, optimized video formats
search_video- get request- search videos based on
search_string - additional parameters like
tags,upload_date, etc can be used to filter the search results
- search videos based on
view_thumbnails(user_id, video_id)like_video(user_id, video_id, like)add_comment(user_id, video_id, comment_text)
Detailed Design
- “load balancers” - divide traffic across multiple servers
- “web servers” - respond to user requests. considered as an interface to api servers
- “application server” - handles the core business logic
- “user and metadata storage” - since user data and video metadata are both different kinds of data, we can use different storage clusters for them. this helps decouple and scale them independently. we can use mysql or nosql in case of large concurrent reads and writes
- “upload storage” - temporary storage for user uploaded videos
- “encoders” - performs encoding and transcoding of videos in the upload storage
- encoders can also generate the thumbnails for videos
- they then again write to the video metadata storage to update with thumbnail etc data
- “cdn” - used for popular content
- we use a “distributed search” system for searching through videos easily - mention working of “inverted index”, etc - how he categories, description, etc of the video can be tokenized etc
- then, mention how for ranking the videos, view count, upload recency, etc would be taken into account
Distinctive Features
- “consistency” - we prefer availability over consistency (cap theorem)
- “caching” - we can use lru strategy
- “storage” - we can use mysql for users, as users need not scale as much, and we get benefits of consistency, indexes, etc. however for thumbnails, etc, we would need a lot of scale, so we need solutions like bigtable, cassandra, etc
- “duplicate videos” -
- duplication can happen due to several reasons, users might try to spam the system, copy content, etc
- these can cause copyright issues, consume significant storage and compute, etc
- so, we can use several solutions to detect duplicates
- solution 1 - “lsh” or “locality sensitive hashing” - in hashing techniques like sha256, even a pixel change will lead to a completely different hash value. in lsh, the high dimensional data is converted to a smaller fingerprint. this is then hashed. this helps catch similar videos, e.g. same video with different quality
- solution 2 - “bma” or “block matching algorithm” - the video is divided into smaller blocks. then, we try finding the block of video 1 in video 2 (maybe at a different position). this helps compare “motion” between the two videos - if the motion is the same, the two videos are likely to be the same
- solution 3 - “phase correlation” - uses “fft” or “fast fourier transform” to represent images as waves. this helps capture for e.g. if a video is shifted by a few seconds or pixels easily
- google uses “vitess” to help scale databases. it is an abstraction layer that hides the complexities of sharding, replication, complex database client logic, etc away from the developers
- “web server” - use an optimized, open source solution, self managed solution like lighttpd
- use the right tech stack in the right place - c++ (and not python) for encryption, etc
- “encode” - videos are broken into smaller “segments”
- now, different segments can be encoded differently. e.g. the segments which are less dynamic and have less colors are encoded with a higher compression
- we also encode videos to support different kinds of devices and network conditions
- we can also talk about how cdns work, how tail content works in cdn, etc here
- we can also pre determine content from popular uploaders and forward it to cdn directly (e.g. mr beast)
- “popular content” -
- different regions can have different popular content
- formula for determining popularity - \(Th_{reg} = (w_{comments} \cdot N_{comments}) + (w_{likes} \cdot N_{likes}) + \dots\)
- the threshold for different regions can be different
- a video is globally popular if sum of thresholds of different regions passes a global threshold
- also mention “sharded counters”, local vs global trends, sliding window for trending windows, etc here
Recommendations
- naive approach - we do an “offline” calculation for recommendations
- we assign a “rank” / “score” to each video for each user using an “ml model”
- user 1 video 1 - 89
- user 1 video 2 - 63
- ….
- user 2 video 1 - 56
- user 2 video 2 - 99
- ….
- then for each user, we sort using the score, and the highest scoring ones are used for a user’s timeline
- issue - we have billions of users and millions of videos, and we would want to run all the user-video combinations against this ml model
- so, we need a much more efficient solution
- so, we introduce a step called “candidate generation”, where we filter the millions of videos down to a few hundred, before ranking and forwarding them to the user
- we can have multiple candidate generators - all of them individually output some videos
- candidate generator 1 - find videos by creators the user is subscribed to
- candidate generator 2 - find recent videos that are very popular / trending videos
- candidate generator 3 - find videos matching users interests - videos user liked, viewed recently, etc
- then, we take the union of all of them, and perform the “ranking” / “scoring” operation against them
- for candidate generator 1 and 2 - we simply need to query almost some source i.e. the logic is not as complex
- for candidate generator 3, we use the following approach -
- we ingest all the video metadata into a “vector store” (open source example faiss, cloud example pinecone)
- how it works - textual data like categories etc are converted into a “vector” using “embeddings”
- when user requests for their timeline, we first generate a vector for the last video that the user watched
- then, we query the vector store to find vectors close to it in the vector space, and then return these results
Upload / Download Flow Deep Dive
- videos can become very large in size
- sending them through load balancer / api gateways is impossible
- so, the client first only sends the video metadata to the service
- the service first saves the video metadata
- it also generates a “signed url” for s3 / the blob storage and returns it to the client
- then, the client directly uploads the video to s3 using this signed url
- aws sdk includes features like “multipart uploads” (chunking) which helps upload such large videos easily
- after the client uploads it, we can use one of the two methods to update the metadata -
- the client notifies the service that the upload is complete
- we use s3 event notifications to notify the service that the upload is complete
- similarly for downloading, the service can just send the metadata and the signed url
- the client can then use for downloading the video directly from the blob storage
- the encoding and transcoding logic can work off of s3 event notifications as well -
- they receive the notifications when a new video is uploaded
- they encode / transcode videos using different encodings and formats
- they write these back to the blob storage
- this dispatches notifications which can be used to update the video metadata
- before starting the encoding and transcoding logic, the video is “chunked”. advantages -
- these chunks can be processed in parallel
- the client need not download the entire video at once
- note - remember that this chunking process is different from the multipart upload process. the former is for optimized encoding and streaming, while the latter is optimized for uploading large videos
- note - features like adaptive streaming, https, cdn, etc are part of streaming protocols like hls, dash, etc
- when sharding e.g. for dynamodb, we can use video id as the partition key and timestamp as the sort key
- “adaptive streaming” - as the user’s network conditions change, we send the right chunks of the video for an optimal experience without buffering. first, the users download a “manifest file” - it contains urls for the different resolutions for each of the different segments. then, based on the network conditions, the client can request the segment with the right resolution from the cdn
Quora
Estimation
- assume 300 million daily active users
- assume each asks 1 question per day
- assume each question / answer combination contains 100 kb of textual data
- assume 15% of questions contain images, and 5% of questions contain videos
- assume 250 kb for images and 5 mb for videos
- so, total storage =
- (300 mil * 100 kb) + (300 mil * 15% * 250 kb) + (300 mil * 5% * 5 mb)
- 30 tb + 11.25 tb + 75 tb
- 116.25 tb per day
- incoming bandwidth = 116.25 tb / (24 * 60 * 60) * 8 ~= 11 gbps
- outgoing bandwidth = assume a user views 20 questions a day. this way, we would need 20 * incoming bandwidth = 220 gbps for the outgoing bandwidth
High Level Design
- most things should be the same as youtube
- “data storage” - we can use a relational database like mysql for questions, answers, etc. for scaling mysql, we use the techniques discussed here - we split tables of a database into multiple shards, keep partitions of different tables in the same shard to avoid querying across shards in case of joins, etc. for storing the mapping of which shards hold which partitions of which tables, which ones are primary, etc, we can use “zookeeper”
- below is more of a “case study” which we can talk about as part of other systems as well
- quora page has multiple components like feed, ads, question, comments, user info, etc
- quora wanted to build these components in parallel
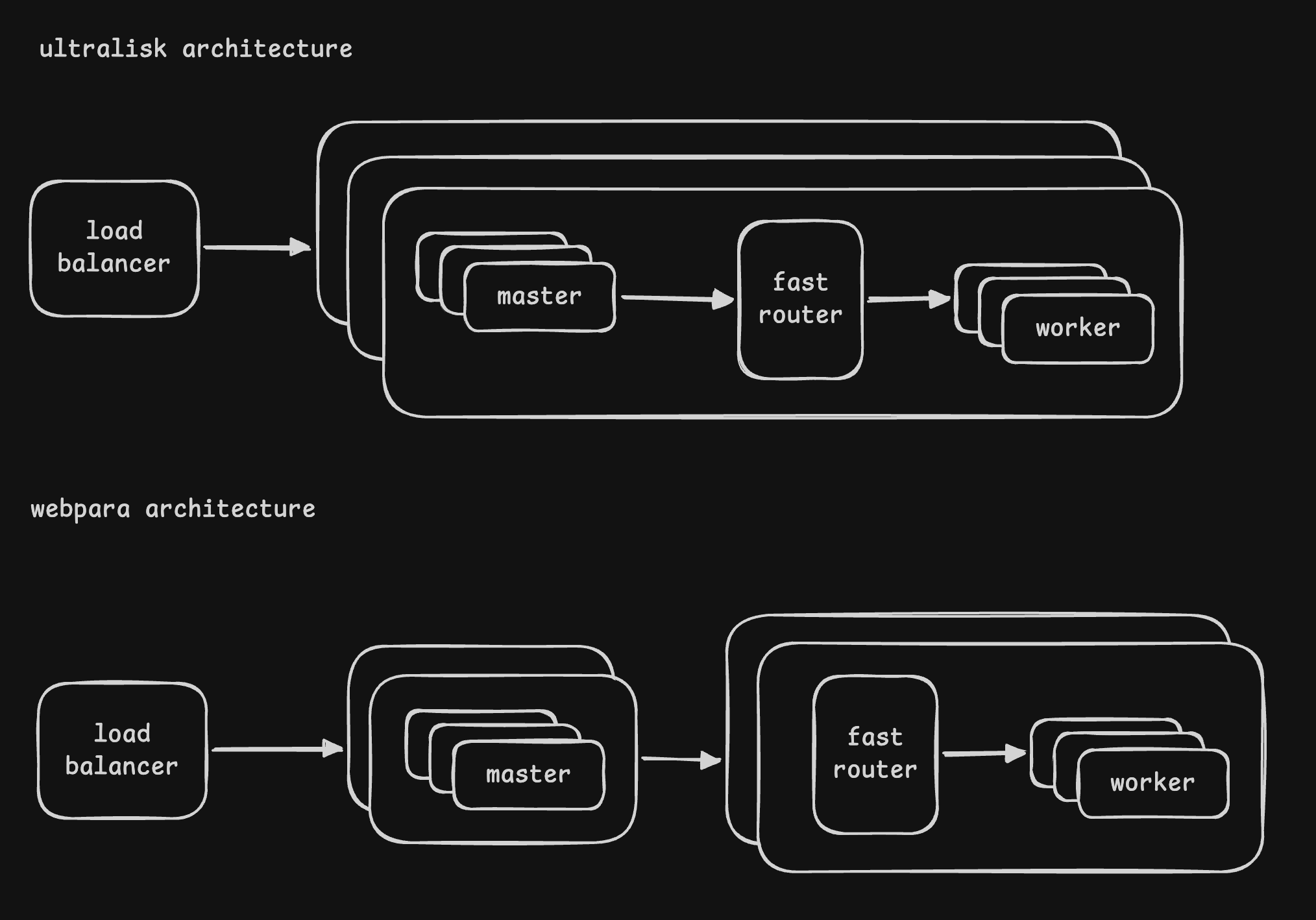
- “webpara architecture” -
- there were a set of machines called the “webpara machines”, which ran the “master processes”
- a separate set of “webworker machines” ran the “worker processes”
- master process would delegate to the worker processes and finally aggregate the results from them
- disadvantage - slowness due to network calls. it compounded with scale
- “ultralisk architecture” -
- “ultralisk machines” ran both masters and workers
- it used local socket / tcp for communication, and so features of tcp like congestion control could be leveraged during the communication between master / worker processes as well
- since all communication happened via localhost, there was a significant reduction in latency
Google Maps
Functional Requirements
- identify the current location of the user
- find the best possible path to reach the destination
- track location of user as it changes
- how long does it take on each path (eta, distance in kms, etc) - it needs to factor in traffic conditions, road conditions, weather, time of day, etc
Non Functional Requirements
- performance - calculation of eta given the source and destination should be fast
- scalability - since both users and enterprise applications use google maps, the system should scale well
High Level Design
- “location finder” - find the user’s current location and show it on the map
- “route finder” - find the paths from source to destination
- “navigator” - users can deviate from the suggested path. this service helps recalculate the path and send notifications to the user
- “gps / wifi / cellular data” - these technologies help find the user’s location
- “distributed search” - helps convert place names to latitude and longitude. an index is created on the place names. e.g. users can select their destination by typing in the typeahead search box. this technique of converting human readable names to exact latitude and longitude is called “geocoding”
- “graph processing service” - runs the shortest path algorithm on the graph
- “area search service” -
- if we know the latitude and longitude of the source and destination, we can use dijkstra
- however, running it on a graph with billions of nodes, at millions of requests per second is not efficient
- so, this service after identifying the source and destination, finds the areas close / between / around the source and destination, with the help of the distributed search service
- now it can run the shortest path algorithm using the graph processing service
- we will store the data of roads etc in a graph database
- “pub sub system” for asynchronous communication between different services
- we have a flow that reads data from various third party sources like traffic data, roads and connectivity, etc and then updates the graph database accordingly
Schema
- we would be receiving location updates very frequently, so we would need a key value store that can handle high throughput
- for storing location, we can use the following attributes -
- user id
- timestamp
- location - latitude and longitude
- the primary key would be (user id, timestamp). the partition key would be user id, and the clustering key would be timestamp
- this way, we can easily query for the latest location of the user
API
- an endpoint to update the current location of the user continuously
- an endpoint to search for the exact location of the destination on the map given its name
- an endpoint to find the optimal route from source to destination, given the mode of transport, etc
Workflow
- user initiates a request
- “location finder” finds the user’s current location using gps / wifi / cellular data
- user searches for the destination using a typeahead, and “geocoding” helps convert it to an exact location
- “route finder” finds the path from source to destination
- the route finder service requests the “area search service” to find the area between the source and destination
- then, the route finder service requests the “graph processing service” to run the shortest path algorithm on the graph database for this area
- the “navigator” keeps track of the user movement and keeps updating the route accordingly
Algorithmic Considerations
- “contraction hierarchies” - it helps perform two optimizations when performing dijkstra’s algorithm
- optimization 1 - if an edge connecting a to b adds no value, as we can be certain that people never use it, we simply remove it from the graph
- optimization 2 - if we know that a -> e has only one path i.e. a -> b -> c -> d -> e, we can simply add the edge a -> e to avoid computation
- we need to have different “levels” of our map / graphs
- example 1 - as we “zoom in”, we see more detailed images on google maps with smaller roads and more precise location details. as we zoom out, we only see images with the important highways and district level names
- example 2 - it helps us run our algorithms optimally. for going from a to b, if the two places are far apart, we can consider going from a to main roads, then travel along the main roads, and then finally main roads to b. the main road(s) can be part of a larger more zoomed out graph, on which a different dijkstra’s algorithm can be run, while the smaller back roads can be a part of a finer graph, which we only need to consider at the start or end of our journey
- these ideas of levels can be linked to using geo hash described in uber. e.g. 110 would mean 3 levels, 1110 would mean four levels and so on
Segments
- we partition the graph into “segments” (say 5km by 5km)
- because a segment is much smaller than the whole map, it can be loaded into memory and processed easily
- each segment can be defined using four sets of latitude and longitude
![]()
- we can treat the “roads” within a segment as edges, and “intersections” as nodes
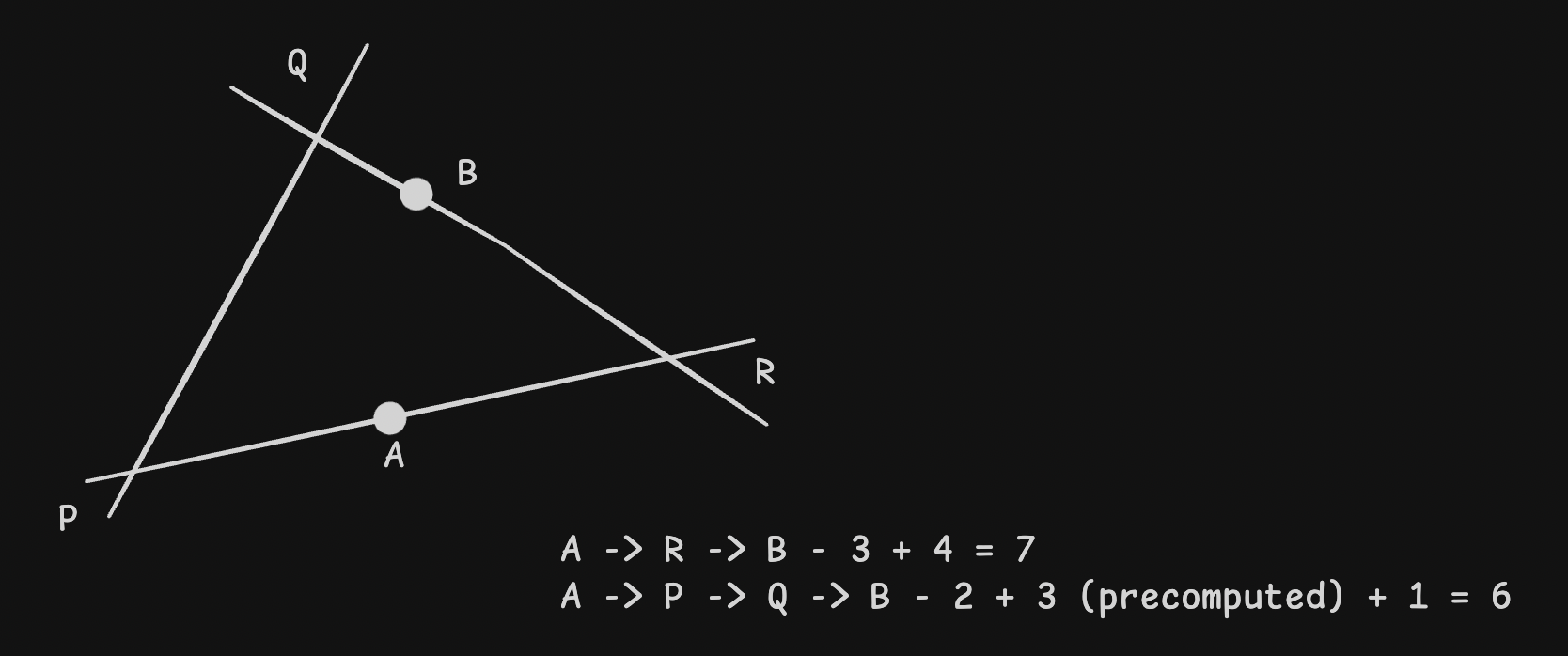
- we precompute the shortest paths within a segment and store them in the graph database
![]()
- typically, users would not start at a node, but somewhere on the edge. we can handle it on the fly as follows -
![]()
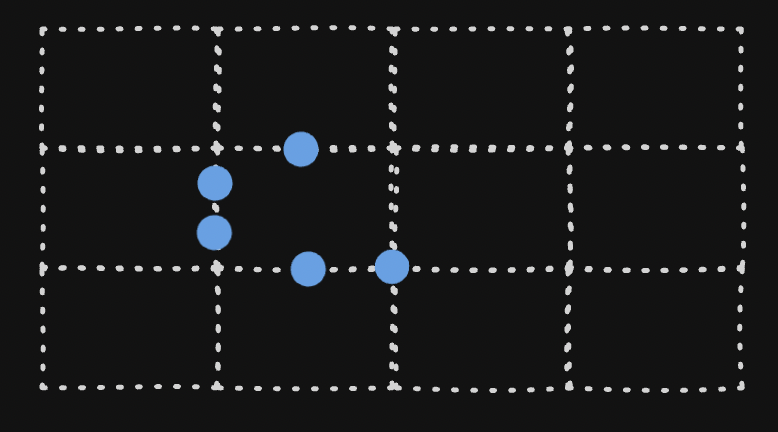
- the nodes at the edges of segments are called as “exit points”. they help connect adjacent segments. for instance, look at how the nodes marked in blue below help connect the segment to its adjacent ones
![]()
- now, using the area search service, we would find the segments to run the algorithm on
- then, our nodes are the “exit points”, while the edges are the “precomputed paths” between these exit points
- all the segment data cannot be stored in a single database, so we can use a distributed graph database, shard using the segment id, etc

Edge Weights
- for traffic data, we use multiple things -
- realtime data from users
- third party data from sensors like traffic cameras
- static data based on roads
- historical data based on patterns
- all these are used to update the “weights” of the edges on the graph database
- this is then be used by the graph processing service to calculate the shortest path by considering traffic etc
Analytics
- recall how we were storing the location data
- now, we can use a “cdc” pipeline on top and push the data to say “kafka”
- next, “spark streaming” can be used for realtime data processing and analytics
- this way, we can analyze how the traffic changes based on time of day, location, vehicle, etc
Realtime Location Tracking
- persistent connections between client and server using websockets for dual communication
- here, describe other solutions like long polling, server sent events, etc and pros and cons of each
- this way, if for instance there is an accident on the route, the server can immediately send a notification or update the route of the client in realtime
Yelp
Requirements
- users can read and write reviews
- users can search by different parameters -
- name of place (e.g. mc donalds) to list the close by branches of mc donalds
- type of place (e.g. cafe) to list the nearby cafes
- etc
- extension of search - search for all business within a radius of the user
- users can view the details of a business like reviews, location, etc
- performance / latency - search results should be returned within 500ms
- strong consistency < high availability - we need not see the new reviews immediately, we can see it eventually
- scalability - scale easily for the growing number of businesses and users
- with 100m dau and 5 search queries per user, we get 500m/100k = 5k qps
Schema and API Design
- entities - business, reviews, users (add attributes for each of them)
- next, we cover the different apis supported
- search -
GET /businesses?category={}&name={}&location={}&radius={} -> Partial<Business>[]. this is using rest semantics - using get with plural form of the entity. notice how the different attributes are passed as query parameters - the response would include only certain attributes of the business like a short description, thumbnail, name, average rating
- additionally, since the search endpoint can return a large number of results, we should add pagination support using page number and limit kind of parameters
- get business details -
GET /businesses/:id. point out how this time we use a path parameter unlike a query parameter we used for the search api - the reviews for a large business can be huge in number, so we can have a separate api for fetching the reviews with pagination support -
GET /businesses/:id/reviews?page={}&limit={} - create a review -
POST /businesses/:id/reviews. point out how unlike the other apis, this one might need authentication
High Level Design
- “sql databases” are used for storing user data, places, reviews, photo urls, etc
- mention storing of data to avoid cross shard queries, zookeeper to store mapping of partition to shard etc
- our queries would join the business data, reviews, etc, all of which should ideally be present on the same shard
- updating the average rating - when we add a review, we do it as part of a transaction
- begin
- create the row review
- calculate the average rating using sum(ratings) / count(ratings)
- update the business table with the new average rating
- commit
- what if we get multiple reviews simultaneously, how would it affect our average rating calculation? - describe techniques like obtaining a lock on the business row, or using optimistic concurrency control, etc
- for ensuring 1 review per user per business, we would place a unique constraint on the (user id, business id) pair in the reviews table
- next, for handling searches, we can have a cdc pipeline from our relational database to for e.g. elasticsearch
- the other solution is to use postgres for our sql database, since it already has support for features like postgis for geospatial indexing, full text searches, etc
- we can use cqrs pattern for separating reads from writes
Deep Dive into Geo Spatial Data
- this is also called a “proximity service / search” - find close by restaurants, gas stations, etc
- solution 1 (naive) - the places table would have the place id, and a column for the latitude and longitude
- assume we want to query the places nearby to a specific location. say the location is m, n. we look for all places within a radius r, using m-r,n-r to m+r,n+r
- this means we index the places table on the latitude and longitude columns
1 2 3 4
select * from business where lat between (my_lat - r) and (my_lat + r) and long between (my_long - r) and (my_long + r)
- issue 1 - regular indices are optimized for 1d data, not 2d - when we perform searches as described above on two indexed columns, the searches are very slow
- issue 2 - recall that relational databases can handle around 1k rps, which is not enough for the scale of yelp
- solution 2 - we also store the segment id alongside the place. we index on this column. this way, we would only have to search against specific segments
- solution 2 optimized - we store the data in a key value store, where the key is the segment id, while the value is the list of places present in that segment
- so, we can introduce a “segments producer” component that would for each place, find the “segment id” by querying google maps and then populate the key value store
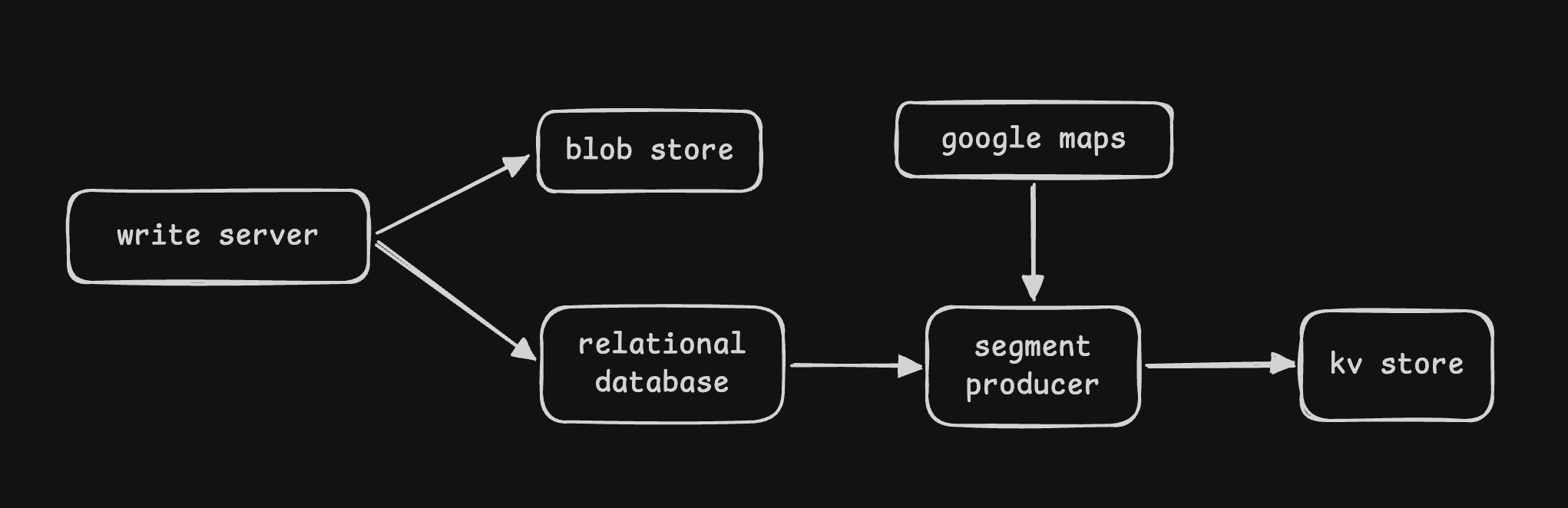
- solution 1 (naive) - a user might be searching for a radius spanning multiple segments
- so when querying, we first calculate the segments we need to query for
- then, we query the key value store for these segments to get a list of places inside these segments
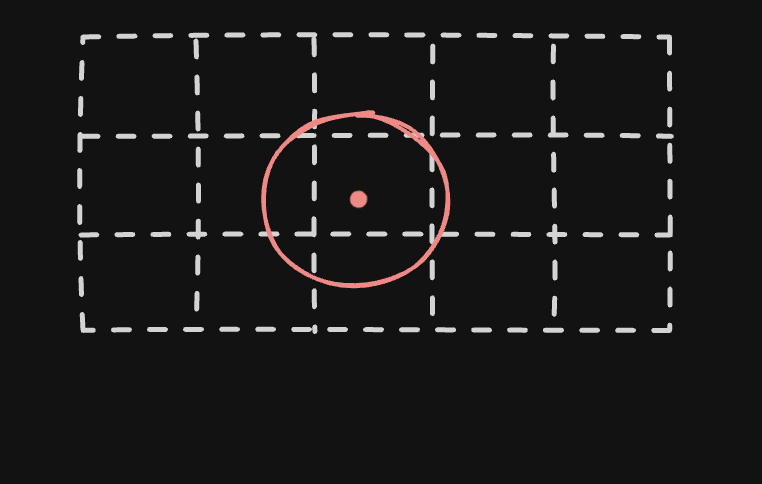
- issue - not all segments have the same no. of places. some segments might be dense, while others sparse
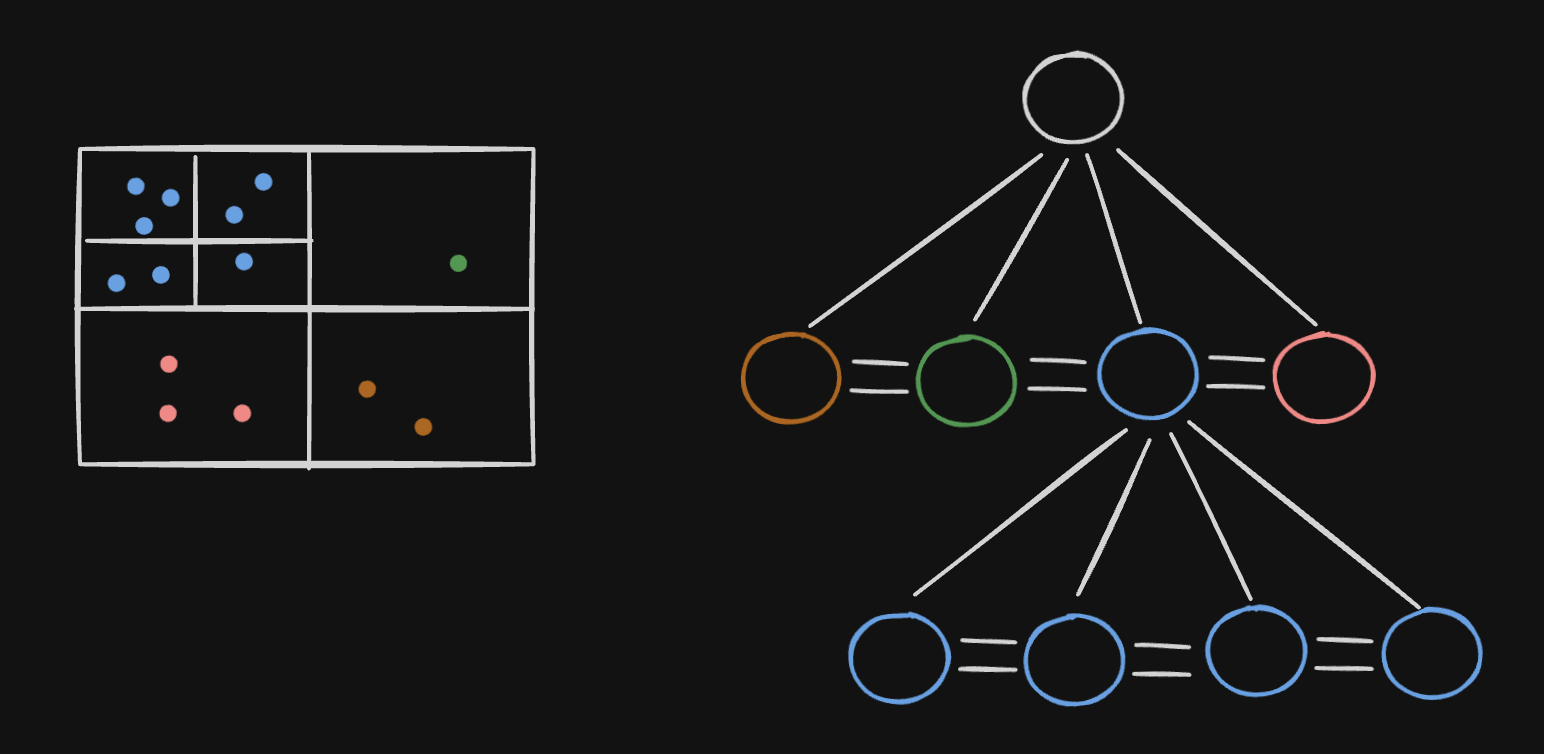
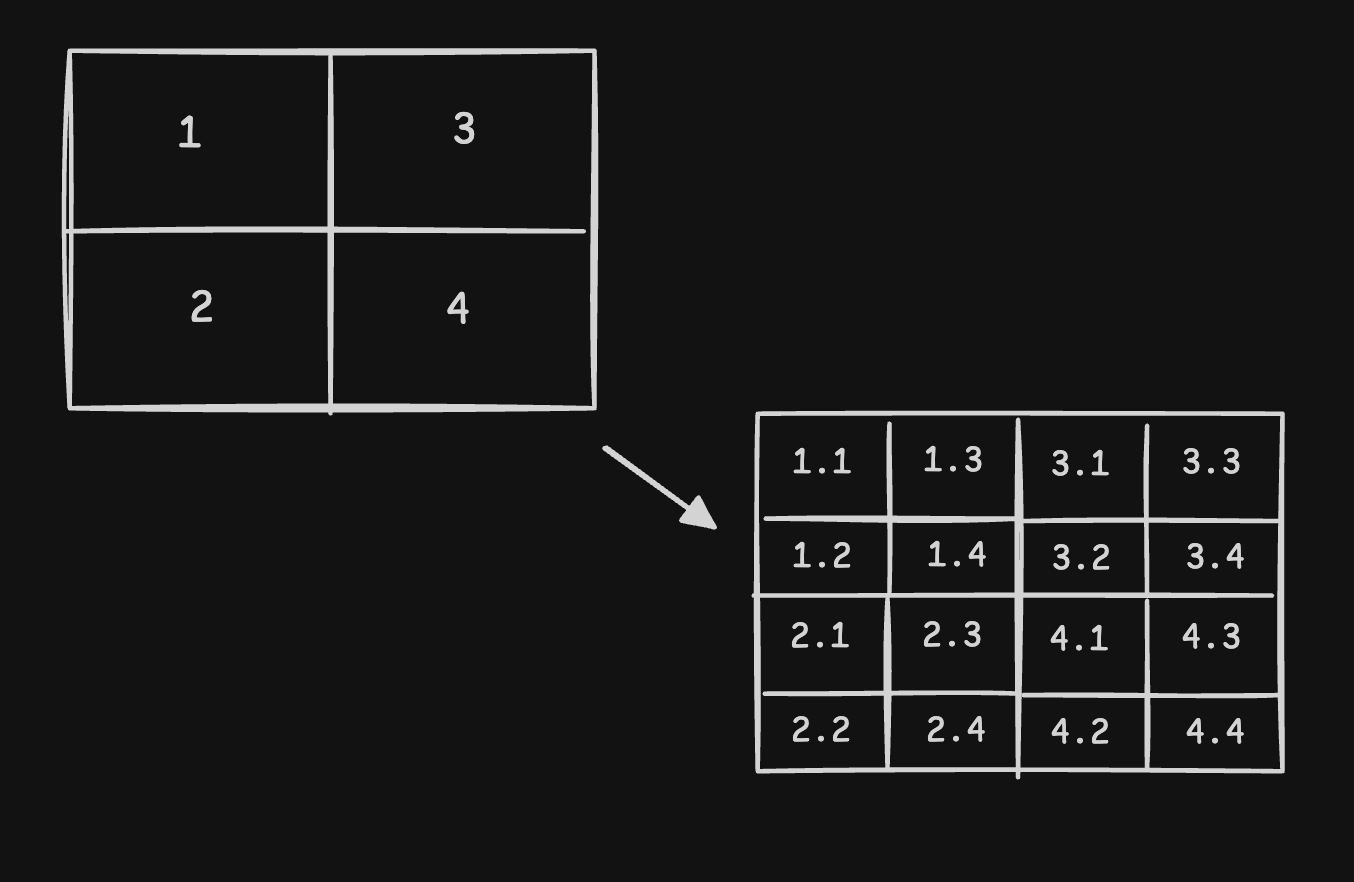
- so, solution 3 - we use “quad trees”
- quad trees have four children, and each leaf node represents some interesting spatial information (in our case, it is a segment)
- we split a segment into four smaller segments, if the number of places in that segment exceeds a certain threshold, say 500. so, each leaf node in our case would be a segment with a list of places
- we also connect the child nodes using doubly linked lists as it allows us to traverse through neighboring segments easily
- we start from the root node and keep traversing down the tree until we find the desired segment. then using the doubly linked list pointers, we traverse the neighboring segments
- this is also called a “geo spatial index” - geo spatial indices are of different types like quad trees, geo hash, etc
- this entire solution is supported by postgres via “postgis”
- we can add new places to our system using a cron
- understand that it would involve updating the relational database, the geo spatial index, etc
- we can partition data based on region id
- this way, places in the same region are present on the same server
- for availability and to scale reads, we can use a primary secondary approach
- the servers used for reading and writing are separated from one another
- “aggregator server” - aggregate results from the quad tree servers and return to the user
- it can handle concerns like “ranking” of results based on ratings, relevance, etc
Uber
Requirements
- users should be able to request rides by entering a pickup and drop location
- drivers should be able to accept these rides
- track driver location in realtime
- find available drivers nearby to the rider
- show eta (estimated time of arrival) when -
- driver is reaching the rider
- when rider is going towards the destination
- show estimated fare for the trip and actual fare after the trip
- manage payments
- allow for trip updates - assign driver, cancellation, successful pickup, successful drop, etc
- low latency - show eta and fares immediately, match riders and drivers as soon as possible, etc
- consistency -
- drivers and riders should see the same data
- one driver to one rider matching
- at this point, we can also talk about what is out of scope -
- different types of car
- ratings for drivers and riders
- schedule rides for later
- availability - for everything outside the ride matching / trips - things like location updates etc
- scalability - scale with increasing number of drivers and riders
Entities and APIs
- entities - driver, rider, trip, location
- now, we would discuss the different apis
- one way i think can be to have everything revolve around the core entity “ride”
- POST /ride - create a new ride request
- the request body contains the source and destination
- the response body includes the ride id, estimated time of arrival, estimated fare, etc
- this api basically creates and saves a new ride entity in the database. the status of the ride can be in “fare estimated” state at this point
- so, the ride object would have several fields like source, destination, rider id, driver id, status, eta, fare, etc
- POST /ride/{ride_id}/request - the rider requests for a ride. the request would be processed asynchronously, as some driver would have to accept it. so, a 200 status code is returned immediately
- POST /ride/{ride_id}/accept - a driver accepts the ride request
- to be able to perform the matching, we would need to know the location of the driver
- POST /driver/{driver_id}/location - so, the drivers continuously send their location updates using this
- PATCH /ride/{ride_id}/status - used by drivers to update the status of the ride -
- when the reach the pickup
- when they pick up the rider
- when they drop the rider
- when the payment is received
High Level Design
- we would have an aws managed api gateway that handles load balancing, request routing, authentication, ssl, tls termination, rate limiting, etc
- “ride service” - it is the entry point for all ride related requests - creating a new ride request, ride updates, etc
- “eta service” - calculate the total eta for the trip given the source and destination
- it considers realtime map and traffic data
- an ml model can be put on top, that considers parameters like time of day, weather, etc as well
- this ml model can then be trained on historical data and used for realtime inference
- “location service” - it receives driver location updates every 5 seconds
- this is used to update the location database
- “ride matching service” - it is responsible for matching riders and drivers
- it talks to the location service to find drivers within a certain radius of the rider
- it also for e.g. calls the “ride service” to filter out drivers who are not available
- then, it sends out a notification to all the relevant drivers using the “notification service”
- then, the drivers hit on the accept ride button, which calls the “ride service”
- for use cases like “trip information” that require consistency, use a relational database
- for use cases like “driver location” that frequently change and require high availability, use a nosql database like cassandra
- to handle slowness or disconnections in network, the app can store the requests locally, and send it when the network comes back up. this will also help resume from app crashes
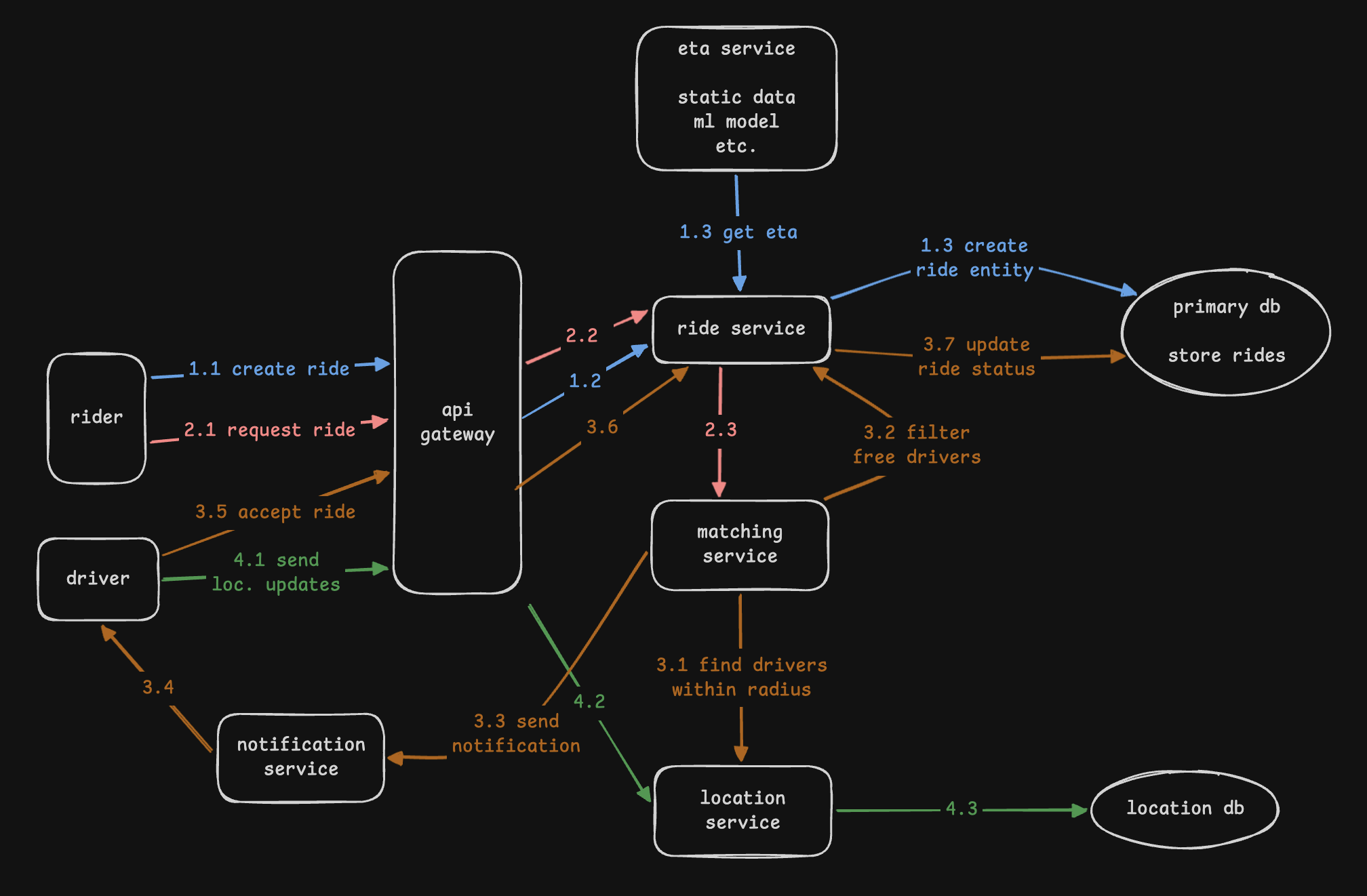
Deep Dive - Handling Geo Spatial Data
- we can have “quad tree map service” just like yelp
- however, we would have drivers instead of places
- issue - it was not designed with upgrades in mind
- now, every 5 seconds, drivers would send their location updates
- so, we might have to remove them from their previous node, add them to a new node and if it exceeds the threshold, possibly split it into four
- solution - we maintain the driver location in a key value store like redis
- the updates are batched and processed by the quad tree periodically (e.g. every minute)
- my understanding - maybe using a key value store allows us to retain the latest location of the driver only, and directly apply that instead of applying every change
- issue - even this approach is not enough for scale
- main disadvantage - quad tree is good where density is different in different regions, data is static, etc
- for a system like uber, “geo hashing” is a better algorithm
- we basically use redis for this - since it is in memory, it is significantly faster
- notice how unlike quad trees where the split was dynamic, the split here is static - e.g. we divide all 4 regions into 4 smaller regions
- it has optimizations which we can use - e.g. by looking at the initial characters of the hash (say 1 of 13), we can tell which broader region it is a part of (1), and accordingly accept or reject it without reading the whole hash
- understand how close points would have similar hashes as well. geo hashes are great for range queries
Deep Dive - Consistency when Matching
- issue 1 - a ride should not be matched to more than one driver at a time. multiple drivers should not be able to accept the same ride request at the same time
- for this, our logic can be like so -
1 2 3 4 5
while (no drivers found) { find next driver; send notification to driver; wait for 10s; } - issue 2 - imagine that people just got out of a movie, and there are 100 ride requests. the same driver might end up getting multiple concurrent requests for a ride from different people. we want to disallow him accepting more than one ride at a time
- recall we were calling the ride service to check for driver availability before sending out notifications to drivers. this works for drivers already in a ride
- however, it does not work for the case where we show the notification to the driver for a few seconds before removing the popup
- issue 3 - also, remember that we would have multiple instances of the ride matching service as well
- so, logic similar to ticket master etc can be applied here
- we would use a “distributed lock” like redis, which helps different instances of matching service coordinate
- additionally, we would add a timeout (say of 10s) so that the lock on the driver is automatically “released” if they do not accept the ride within 10s
- this helps the driver accept other ride requests / match that rider to other potential drivers

Functional Requirements
- post tweets containing text and media
- view timelines i.e. tweets from people they follow etc
- search for tweets using keywords
- like / dislike tweets
- reply to tweets
- follow / unfollow others
Non Functional Requirements
- available - twitter is sometimes used for time sensitive information like news etc
- latency - low latency to deliver feeds, read tweets, etc
- scalability - scale with growing users and number of tweets
- consistency - we can have eventual consistency, e.g. a user need not see a newly posted tweet immediately
High Level Design
- users post tweets via load balancers, which distribute traffic to application servers
- it uses a sequencer called snowflake to generate unique ids for tweets, users, etc
- we need to monitor traffic (e.g. new year) to automatically scale our workloads
- we need to use replication and sharding of databases to handle scale
- we need a failover strategy for resilience
- twitter uses “polyglot persistence” for its architecture
- cassandra for storing tweets - we do not need to support complex queries but at the same time, we need to support very high read and write throughput
- s3 like blob storage for media files
- mysql for ad management, with sharding and replication implementation. ad management involves bidding between advertisers etc, which requires strong consistency
- redis and sharded counters to write like counts etc
- kafka for asynchronous communication and realtime processing
- neo4j for storing relationships (graph). this helps with recommendations for who to follow etc
- lucene for searching tweets. it can have two kinds of searches -
- search for tweets in the last 7 days (stored in ram)
- search for all historical tweets, used for historical and analytical purpose (stored in disk)
- we can use cdc to automatically capture updates in tweets etc to update the lucene index
- we use caching at different layers including usage of cdn
- segcache - segcache is better than redis and memcached for twitter as it has small object sizes. redis and memcached store more metadata for each object, which is not as efficient for twitter’s use case
- observability - monitoring, logging, alerting, sampling to reduce overhead, etc
- “heavy hitter problem” - public figures with millions of followers generate massive traffic spikes. a single counter cannot maintain their likes and views. so, we can use “sharded counters”
- sharded counters also help determine “top k trends”, both local trends and global trends. it uses a sliding window to determine the latest trends for hashtags. it places the shared counters close to the user (like cdn) to reduce latency. disadvantage - eventual consistency i.e. the likes and views might not be updated immediately
Client Side Load Balancing
- disadvantage of centralized load balancer - twitter operates across several heterogeneous services
- in client side load balancing, the client embeds load balancing logic and selects the server directly
- services register themselves with a “service registry” so that clients can discover them
- this means lesser infrastructure, fewer hops and therefore reduced latency, etc
- the client load balancing needs to handle two things -
- request distribution (osi layer 7)
- session distribution (osi layer 5)
- session distribution determines which clients connect to which servers. if the client tried to connect to all servers, there would be a lot of connection overhead for the client
- request distribution determines out of the servers selected above, which one gets the request
Request Distribution
- for “request distribution”, “p2c” or “power of two choices” is used
- the client randomly picks two servers, and sends the request to the one with lesser load
- comparing two random nodes yields exponentially better results than picking a single random node
Session Distribution
- “session distribution” - there are different methods this can use
- “random aperture” - clients select a random subset of servers
- issue 1 - determining subset size is hard. for this, twitter uses a “feedback controller” to dynamically adjust the subset size
- issue 2 - this solution is not fair. it might happen that some servers get overloaded while some stay idle. this solution causes inefficient resource usage
- e.g. notice how server 0 is overloaded while server 2 is idle
![]()
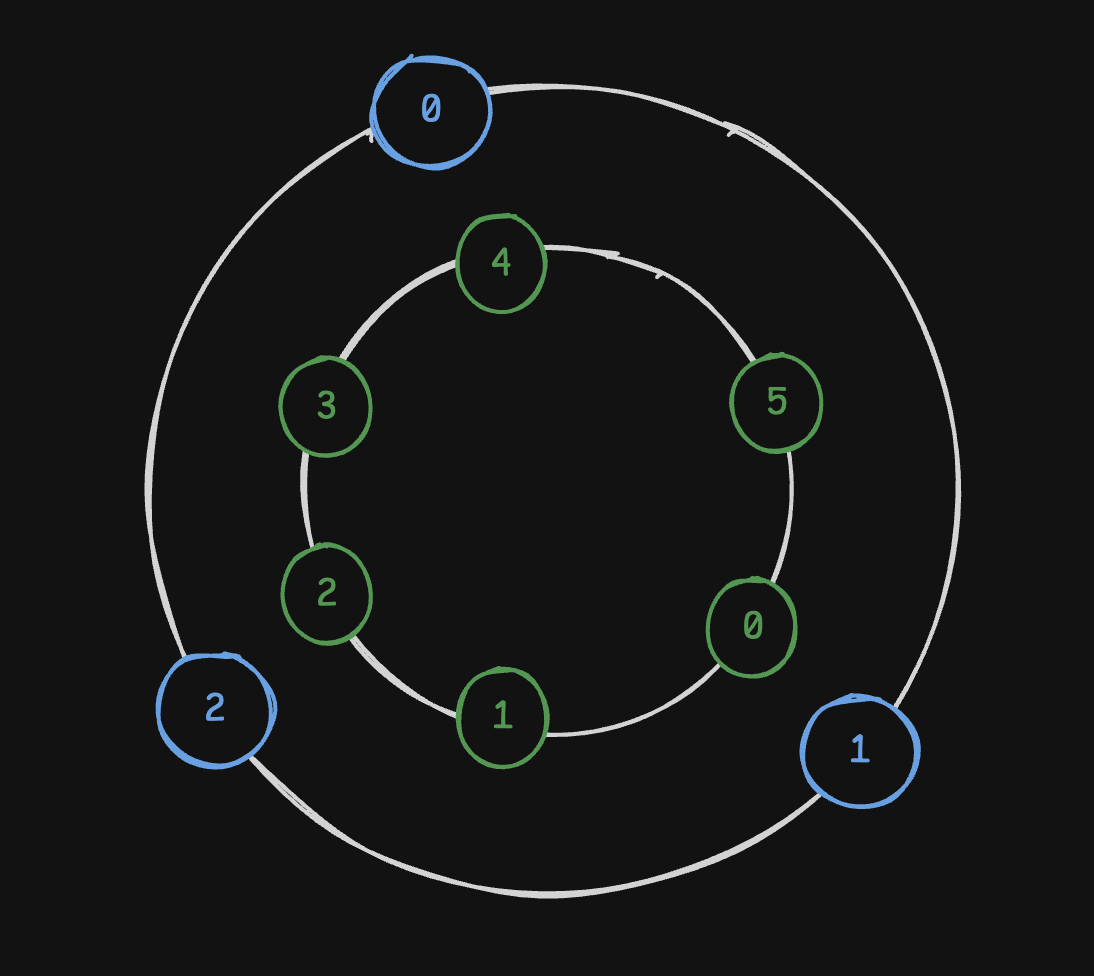
- “deterministic aperture” - similar to “consistent hashing”
- clients and servers are mapped to discrete coordinates
- each client selects the next for e.g. 3 servers on the ring
- this guarantees equal distribution of servers
- even as number of clients or servers change, the distribution is automatically adjusted
- e.g. client 0 goes to servers 4, 5 and 0, client 1 to servers 0, 1 and 2, and client 2 to servers 2, 3 and 4
![]()
- disadvantage - e.g. above, servers 0, 2 and 4 were selected by two clients each, while servers 1, 3 and 5 were selected by one client each. if we had two overlapping sets of clients, the difference would double - server 0 would have 4 clients, while server 1 only 2
- this basically shows us how we can end up having “hot partitions”
- so even here, distribution is not as fair, just like in random
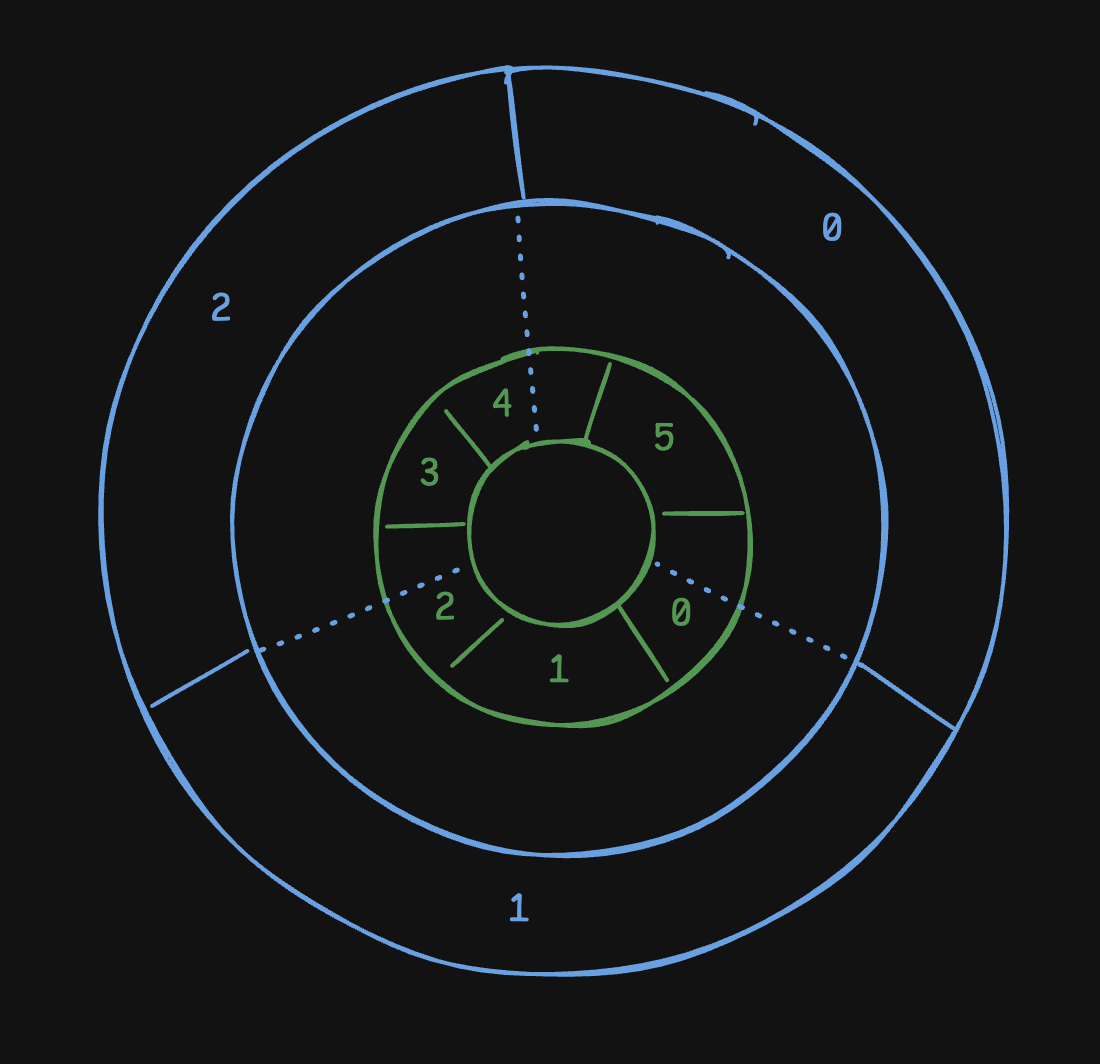
- solution 3 - we modify “deterministic aperture” to use “continuous” instead of “discrete” coordinates
- so, the client establishes connection with all servers with any overlaps (understand from the diagram)
- e.g. client 1 establishes connection with 0, 1 and 2
- however, it takes into account the fraction as well - weight of server 1 is 1, while server 0 and 2 is only 0.5
- this weight is taken into consideration when the client uses p2c to select the server for sending the request
![]()
Timeline Generation
- assume 500 million daily active users open the app 10 times a day
- so, we would have approximately 5,000,000,000 / (86400) ~ 50k requests per second
- assume we need to store 50kb of metadata for each user
- this means we would need 500,000,000 * 50 = 25tb
- breakdown of the storage required for posts -
- post have average 5kb of textual data
- 4/5th of the posts have images of average size 200kb
- 1/5th of the posts have videos of average size 2mb
- so, average post size = (4 / 5 * 200) + (1 / 5 * 2000) + 5 = 565kb
- assume we need to show 100 posts per user timeline
- so, total storage required for timelines is 500,000,000 * 100 * 565kb = 30pb
- “fan out on read” approach -
- users request for timeline
- we query the list of accounts they follow
- then, we fetch the tweets for these accounts
- finally, we return these tweets to the user
- disadvantage - very high latency
- “fan out on write” approach -
- users post tweets
- these then go to a message queue to help with buffering
- then, workers consume these messages
- first, they query the list followers of the user who posted the tweet
- then, they update the timelines of these followers with the new tweet by appending it at the end
- timelines of users are maintained in a cache
- advantage - low latency reads
- disadvantage - expensive writes
- “fan out on write” will not work for users like elon with millions of followers
- it will cause a problem called “thundering herd”, where we would suddenly have to process millions of writes
- so, we use a hybrid approach - fan out on read for celebrities, fan out on write for regular people
- now just like writes, elon’s tweet might get lots of reads once published from multiple users, thus causing a “hot partition” like problem on our key value store
- solution - use a cache layer for the tweet service, and use multiple read replicas in it to distribute reads
- for ranking, we can use a machine learning model that can factor in parameters like recency, no. of likes and comments, relevance to the user, etc
- for timelines, we would also need “pagination” support - page size, cursor, etc
- to be able to easily find the followers of a user, we can choose the partition key and then create secondary indices accordingly
- similarly, the posts table can also be indexed by the creator
TinyURL
Requirements
- a url shortening service creates a short link for a url
- advantage - easier to type and share, reads better in communications, etc
- “short url generation” - generate a short and unique alias for a url
- “redirection” - redirect users to the original url
- “expiration” of these short links
- deleting expired urls, even if not reused, helps keep storage costs low and queries faster
- allow for customization of the short links, expiry, etc
- unpredictable - generated urls should not be guessable (e.g. using sequential ids), else attackers can guess other links
- consistency - we can have eventual consistency - anybody need not be redirected for the short url immediately
- availability / fault tolerance - any downtime will cause redirection to fail, so system should be highly available and fault tolerant
- scalability - easily handle redirection as traffic patterns change
- latency - since it introduces an extra hop, it should be as low and seamless as possible - say 200ms
- why 200ms - anything less than that is not perceivable by humans, so it is almost near realtime
Estimations
- read to write ratio is 100:1
- 1 entry requires 1kb of data
- 200 new million url shortening requests per month
- default expiration - 5 years
- so, total storage = (200,000,000 * 12 * 5) * 1kb = 12pb
- write qps = 200,000,000 / (30 * 24 * 60 * 60) ~= 77 qps
- read qps = 100*77 = 7.7k qps
- shortening requests bandwidth (writes) = 77 qps * 1kb * 8 = 616 kbps
- shortening requests bandwidth (reads) = 7.7k qps * 1kb * 8 = 61.6 mbps
API Design
- shorten(api_key, original_url, custom_alias, expiry) -> short_url
- custom alias - optional key that the customer defines as the short url
- redirect(short_url) -> original_url
- the status code here can be 301 or 302 redirect
- 301 - temporary redirect i.e. our server would be reached for subsequent requests for the short url
- 302 - permanent redirect i.e. the client can cache and directly return the result for subsequent requests
- there are pros and cons for both
- e.g. for 302 redirect, we might not be able to show analytics for how many hits happened for the short url
- but then for 301 redirect, we would have to scale our servers more
- delete(api_key, short_url) -> success / failure
High Level Design
- we would use mongodb as our database
- mongodb vs cassandra -
- we need a read heavy store, not write heavy (see requirements). cassandra is for write heavy workloads
- cassandra follows a leaderless architecture unlike mongodb, which follows a master slave architecture. so availability of mongodb might be lower due to failover. similarly, scalability of mongodb might depend on how we shard our data etc unlike in cassandra
- mongodb support complex querying patterns, complex data types and indices (but this feature is not required for this design)
- other common building blocks include an api gateway, rate limiters, cache, etc
- because we are using multiple data centers, we can use a “global load balancer”
- how to maintain unique urls across data centers - we can prepend for e.g. the data center id to the urls, e.g. service.com/x/short123, where x represents the id of the data center
- what if the wrong data center receives the request for redirection -
- it would first fetch the correct url from the appropriate data center
- then, it would return this url
- additionally, it would cache it for future requests
- this helps reduce the latency for future requests
- how to avoid duplicate short url generation - the system first checks if the entry for the original url already exists. this helps avoid the computation of duplicate urls
- how to avoid two concurrent requests overwriting each other - we use mongodb, which has a single master. recall that we can do so because our system is read heavy and not write heavy. now, mongodb can implement locks and concurrency protocols to avoid issues
- when people request for custom aliases, we need to check if the alias is already taken
- we use a sequencer for generating numeric ids (i.e. base 10)
- for readability, we encode it using base 58 - a-z, A-Z, 0-9 except for 0, O, l and I to avoid confusion
- value to character mapping -
- 0-8 -> 1-9 (no 0)
- 9-32 -> A-Z (no I, O)
- 33-57 -> a-z (no l)
- the database maintains a “used” and “unused” sets of ids. understand that the database contains the base 10 version for the two sets, while the servers return the base 58 version to the users
- we take regular backups to s3 for disaster recovery
- we have read replicas for read traffic
- we can use a consistent hashing mechanism to horizontally scale our system
- for unpredictability, each server on the ring picks a random id from the pool of ids assigned to it, instead of picking sequentially
- remember that to avoid duplicates, even after generating the random short url, we would have to check if it already exists
- we use rate limiters to prevent abuse of our system
- url table - the primary key would be short url. this way, it ensures uniqueness, indexes on it for quick search, etc
- my thought - we can also have a secondary index on the original url to avoid duplicate short url generations
- remember - we can also maintain a cache to make lookups even faster
- instead of a typical cache, we can also use a cdn
- my thought - why was bloom filter not mentioned by anyone?
- since reads and writes are so different in nature, we can use the cqrs pattern as well to separate the read and write workloads
Conversion Example
- assume that 2468135791013 is the unique id
- converting base 10 to base 58
- 2468135791013 % 58 = 17
- 42554065362 % 58 = 6
- 733690782 % 58 = 4
- 12649841 % 58 = 41
- 218100 % 58 = 20
- 3760 % 58 = 48
- 64 % 58 = 6
- 1 % 58 = 1
- so, it comes out to be 1 6 48 20 41 4 6 17
- so, the value for this is 27qMi57J
- to convert it back to base 10, lets assume the same example
- first we convert the characters to values, and then we apply the formula -
- 1 * 58^7 +
- 6 * 58^6 +
- 48 * 58^5 +
- 20 * 58^4 +
- 41 * 58^3 +
- 4 * 58^2 +
- 6 * 58^1 +
- 17 * 58^0
- = 2468135791013
Limits
- we want our short urls to be at least 6 characters long
- 100000 - this becomes 58^5 = 656,356,768
- so, we would start generating ids from approximately 1 billion
- similarly, we are using 64 bit ids
- this means the longest url we can generate would be $\log_{58}(2^{64}) \approx 10.926$ or 11 characters long
- life time for our url generation -
- total available ids - 2^64 - 1 billion (starting range)
- total requests per month (requirements) - 200 million per month
- so, total years = (2^64 - 1 billion) / (200 million * 12) ~ 7.5k million years
Web Crawler
- a bot that fetches web pages, parses content, and extracts links for further crawling
- use cases -
- validate html structure and links
- create mirrors of popular websites
- check for copyright infringement
- non functional requirements -
- scalability / performance - distributed / multithreaded to fetch millions of documents
- fault tolerant - a failure in between should not start re-crawling from the start
- extensibility - support protocols beyond http, different kinds of content, etc
- “politeness” - websites ship these as part of “robots.txt”. described later
- estimation -
- 5 billion pages to crawl
- assume each page has content of 2mb
- so, storage = 10pb
- assume each page takes 100ms to crawl
- so, total time ~ 15.85 years
- so, this was if we had one server having 1 core
- now, assume we had multiple servers, all of which are multi core
- we can find no. of servers required based on the time we would want to finish the crawl in, e.g. 1 day
- flow on a high level -
- fetch html for urls
- extract urls and content from the html
- store content in a data store
- repeat the process for the extracted urls
- selecting the right seed urls is also a problem -
- we can manually select a few urls
- we can scan a range of ip addresses, and include them as seed urls if they have web servers running
- we need to select the urls with the right category, popularity, etc as per our use case
- the whole of www is a graph. we should select urls that allow us to discover more nodes in the graph
- we start with a “url frontier” - it contains the set of urls to crawl
- solution 1 - a worker dequeues the urls from the url frontier
- it then fetches the webpage, and extracts the content and urls from it
- workers talk to custom “dns resolver” that caches frequently used ips
- this helps speed up dns lookups as compared to using the generic dns resolver
- for instance, it can also be a simple redis cache on top of the third party dns resolver
- the urls are added back to the url frontier
- the content is stored in a “blob store”
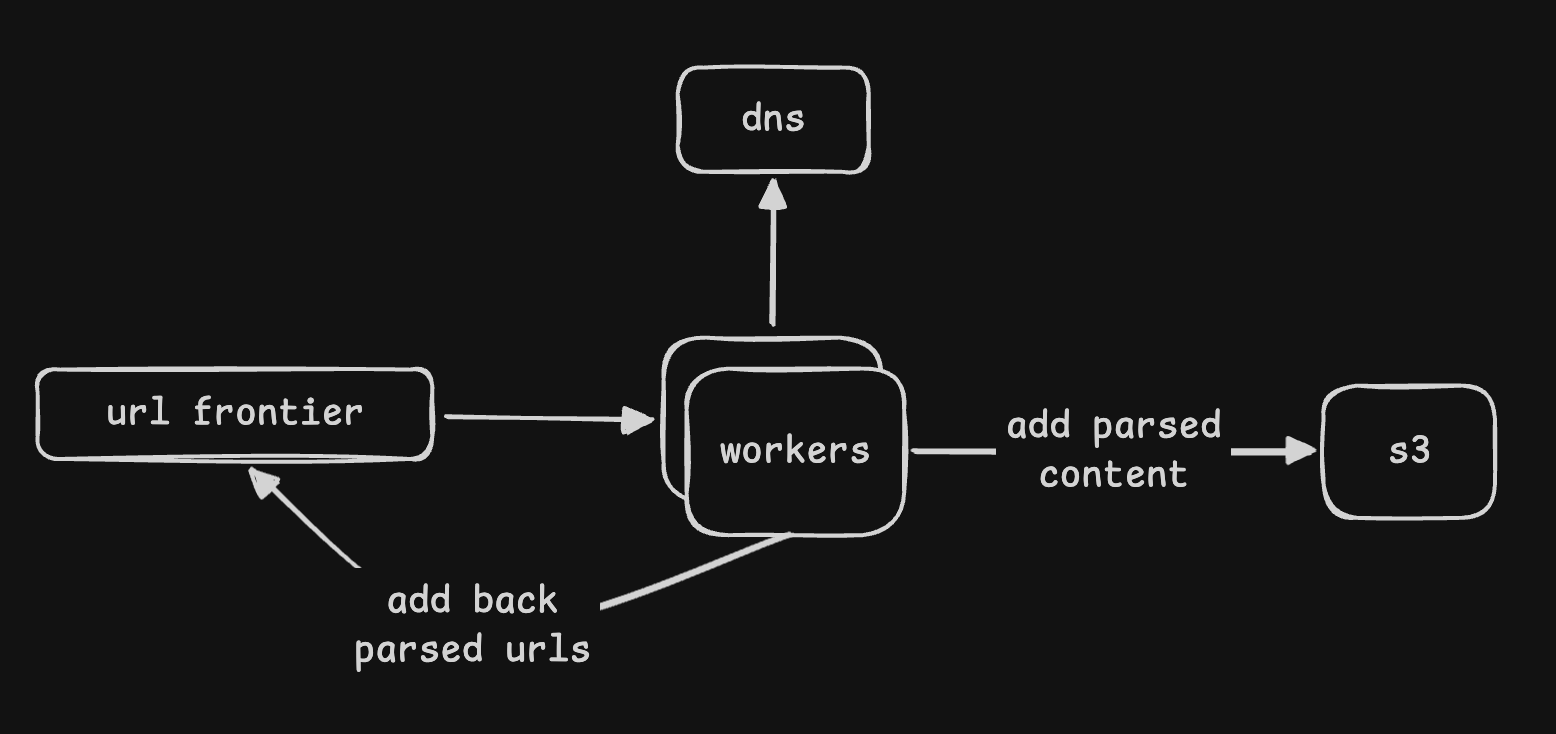
- issue - the worker is doing too many things. monolithic, hard to scale, etc
- what if we fail at the parsing stage - we would have to redo the fetching of the webpage
- solution 2 - we split the worker into different components
- “crawler” - fetches the webpage, and then saves the html content as is to s3
- it also saves the metadata to a database - url(link, s3_path)
- next, it queues this metadata entity to another queue called “extraction queue”
- then, we have “extractors” that consume from this queue
- the extractors parse the urls and add it back to the url frontier
- they also parse the content and add it to the blob store
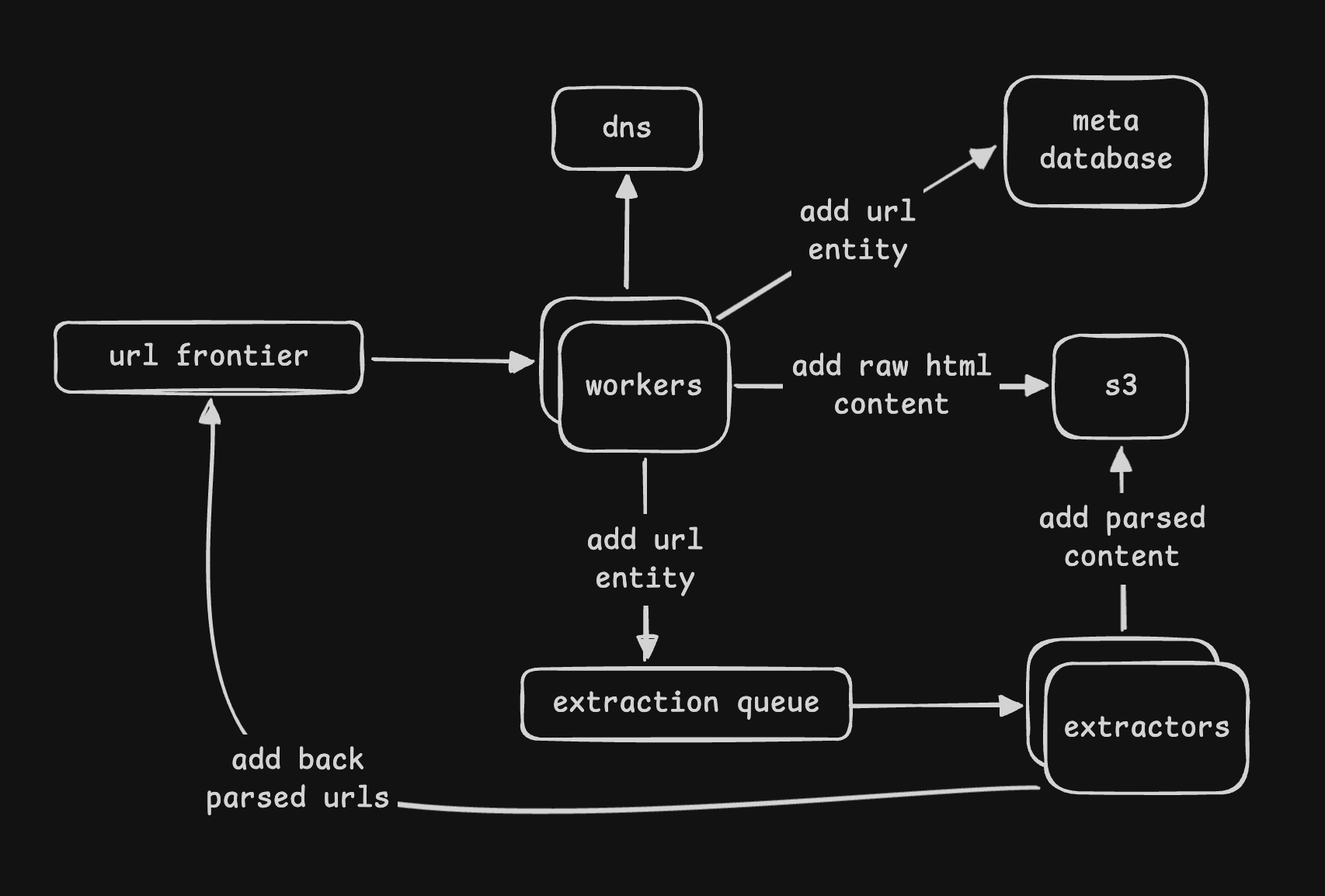
- fault tolerance - what if a website goes down? how does a worker handle this?
- solution 1 - some in memory retry with exponential backoff
- issue - what if the worker goes down during the backoff? we would loose the retry state
- solution 2 - kafka does not support retry out of the box, but message queues / sqs does
- it has “visibility timeout” - consumers do not see the message till this time
- if the consumer fails to process the message within this time, the message becomes visible again and can be consumed by another worker in the queue
- if the consumer successfully processes the message, it can delete the message from the queue
- additionally, it supports parameters like “max receive count” (how many times to retry), “dlq” (move to this queue after all retries are exhausted), etc
- so, talk about how the idea of at least once processing semantics etc work here. interviewers expect this
- my layman understanding of kafka vs message queue - kafka is for scale / data processing etc, but when we have requirements around retries, routing, etc, message queues have more features. message queues have a push model unlike kafka’s pull model. kafka retains messages and uses offsets etc, while message queues delete messages once processed
Politeness
- websites ship a file called “robots.txt”
- it contains different kinds of rules for bots
- we would add these rules to for e.g. the metadata alongside the urls we were storing
- rule 1 example - which pages are not supposed to be crawled (e.g. /private/*)
- when the crawler fetches such a url, it would skip it - e.g. acknowledge the broker without any processing
- rule 2 example - crawl delay (e.g. 10 seconds between requests)
- say the crawler will verify if (now - last_crawled_time) for the url is more than the crawl delay
- if not, it would set the visibility timeout of the message in the queue to for e.g. (crawl_delay - (now - last_crawled_time))
- entity - domain(domain, last_crawled_time, crawl_delay, disallowed_paths)
- note how this is specific for a domain, and maybe multiple urls under the same domain would share this
- we can mention how we can cache this content as well, as robots.txt does not change frequently
- crawlers should also include a “user agent” in the header, which identifies the crawler to the website. this is also used by websites to for e.g. contact the crawler in case of any issues
Deduplication
- issue 1 - avoid crawling duplicate urls
- these end up wasting significant compute resources on our end
- solution - the url entity in the meta database can have the link as a primary key
- the extractor would first query the meta database to check if the url already exists there
- only if it does not exist would it add it to the url frontier
- issue 2 - avoid parsing duplicate html content
- e.g. different websites (e.g. mirrors?) might have the same content but different urls
- again, it would waste significant compute resources on our end
- solution - when the crawler fetches a webpage, it calculates a hash of the content and store it in the db
- so, url now has the following fields - link, s3_path, content_hash
- if we were for e.g. using dynamodb, we could have a global secondary index on the content hash column to make lookups faster
- if a url entity with the same content hash already exists, we can skip parsing the content and just add the url to the url frontier
- issue 3 - some urls or domains might have too many sub pages, which we might want to avoid
- solution - we can have a “depth” parameter
- e.g. whenever the extractor extracts urls, it increases the depth by 1 when adding the new urls
- we can set a threshold for this depth, and if it is crossed, we can stop adding new urls to the url frontier
Miscellaneous
- we can use redis for a client side rate limiter. this helps avoid hitting the same website too many times in a short span of time
- to avoid hitting the same website with multiple workers, we can use a distributed lock on the domain name
- solution 2 - we can produce a hash of the domain, and assign each worker to a range of hashes
- this way, the same worker would be responsible for crawling sites of the same domain
- additionally, this allows us to for e.g. place each worker close to the websites they crawl
- it is like “bfs” as we are using a queue - dfs would have been exploring all the sub pages for a website
- “revisit policy” - we might want to visit certain dynamic pages like the news website more frequently than static pages like blogs
- similarly, we might assign “priority” to certain websites based on various heuristics like category, popularity, etc. so, a traditional queue might not work here, and we might have to use a “priority queue” instead
- for implementing priorities, we can have multiple queues - a high priority queue, a low priority queue and so on
- the queue, database, etc we introduced in this design are basically components of a “scheduler”
TODO - https://www.youtube.com/watch?v=0LTXCcVRQi0
Requirements
- support one to one conversations
- support group conversations
- enable sharing of images, videos, documents, etc
- storage - persist messages for users only until they are delivered
- send out push notifications when users come back online
- low latency - deliver messages as soon as possible
- consistency - messages should have same order for every one. so, consistency > availability
- security - end to end encryption of messages
- scalability - scale with increasing number of users and messages
Estimation
- 2 billion dau
- 5 messages per day per user
- say messages are retained in servers for 30 days - messages are lost if users do not connect within this window
- say each message is 2kb on an average
- so, storage required = 600 tb
- from here, calculate bandwidths etc
- whatsapp servers can handle 10 million connections per server
- so, for 2 billion dau, we would need 200 chat servers
Entities
- user
- chat
- message
- client
High Level Design
- architecture - user a <-> chat server <-> user b
- basically, both user a and user b establish connections with the chat server
- step 1 - user a sends the message to the chat server
- step 2 - the chat server sends an acknowledgement to user a
- step 3 - the chat server sends the message to user b
- step 4 - user b sends an acknowledgement to the chat server
- step 5 - the chat server notifies user a that the message was delivered
- step 6 - user b reads the message
- step 7 - user b notifies the chat server that the message was read
- step 8 - the chat server notifies user a that the message was read
Websockets
- why websocket - http does not keep the connection open
- so, it uses polling, which is resource intensive and has latency
- websocket maintains a persistent connection
- it allows for bidirectional communication
- now, assume we had one chat server as described in the basic architecture of high level design
- we would not be able to scale it to billions of users
- so, we have multiple “websocket servers” to support multiple users
- each user establishes a connection with one of these servers
- we have a “websocket manager” that manages the mapping between user (or device) and websocket server
- why “device” - a user can be logged in from multiple devices, and we want to deliver messages to all of them
- the websocket manager can use redis to store these mappings internally
- advantage - unlike dynamodb which uses disk, redis is in memory, resulting in faster lookups
- we don’t really need to think about concurrent updates etc - we just need fast reads and writes here
- now, we need a load balancer to distribute the traffic between these websocket servers
- we cannot use a layer 7 load balancer here - layer 7 load balancers terminate the connection and create a new connection. this works well when we need to forward traffic to stateless web servers
- however, we need persistent connections here - so, we use a layer 4 load balancer here
- it uses tcp, and it almost feels as if the load balancer is not there - it does not do routing based on inspection of content etc, unlike layer 7 load balancers
- overall flow - user a sends a message to their websocket server
- the websocket server queries the websocket manager to find the websocket server for user b
- then, it forwards the message to user b’s websocket server, which delivers it to user b
- to avoid frequent lookups, websocket server can cache the mapping
- however, the websocket manager would then have to invalidate the cache of the websocket servers when the mappings change
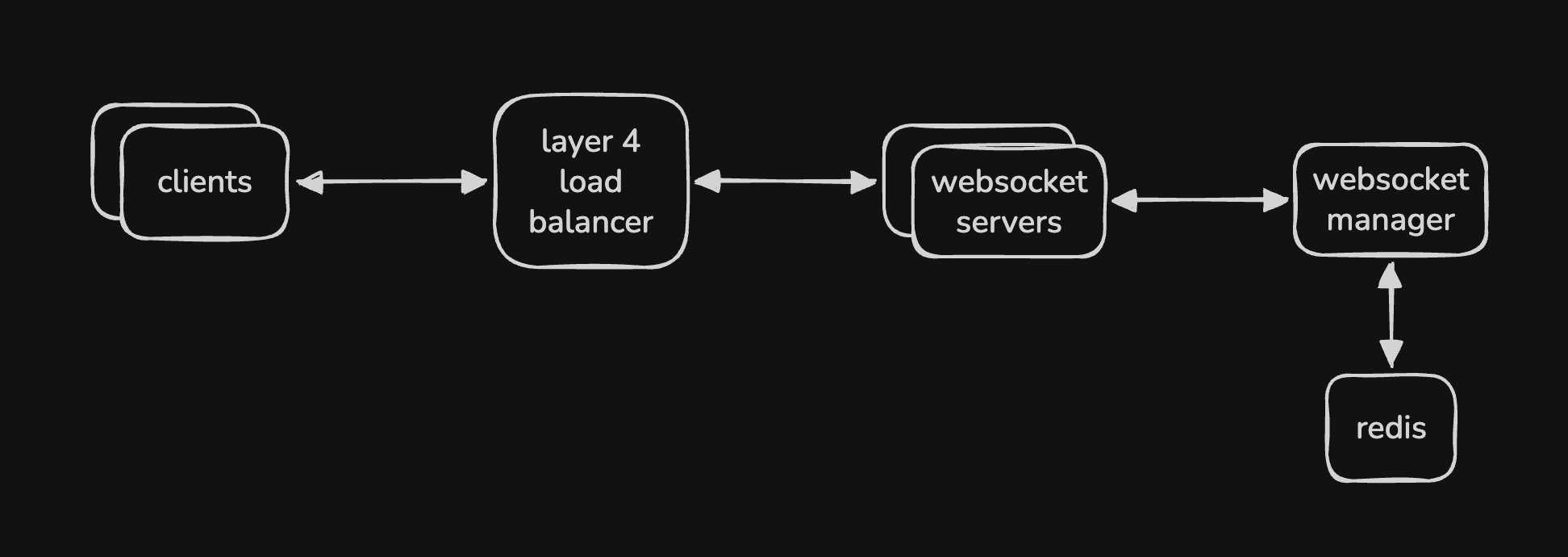
- the load balancer can use “least connections” for load balancing in this case
- i also think we can use “consistent hashing” as usual here
- the user ids can be present on the ring, we can add / remove websocket servers as needed
- then, we would accordingly call out how in case of rebalancing, the mapping of the websocket manager would require updating, the cache of the other websocket servers would require invalidation, etc
Handling Media Files
- using our websocket servers etc for multimedia might create a bottleneck
- so, use an approach similar to youtube - using singed urls, cdn, etc
- our servers can authenticate with the blob storage and return the clients a signed urls
- the clients can then directly interact with the blob storage for uploading / downloading files
- additionally, the servers store these signed urls in the message entity in the database
Message Service
- this is where we store all the messages
- this helps us handle offline users as well
- so, there are two things the websocket servers do (in parallel maybe)
- communicate with other websocket servers for realtime message delivery
- forward these messages to the message service
- we can have an additional cleanup service that deletes messages after the retention period
- it can use key value store like dynamodb
- mention entities, their primary and sort keys, gsi, etc here as well
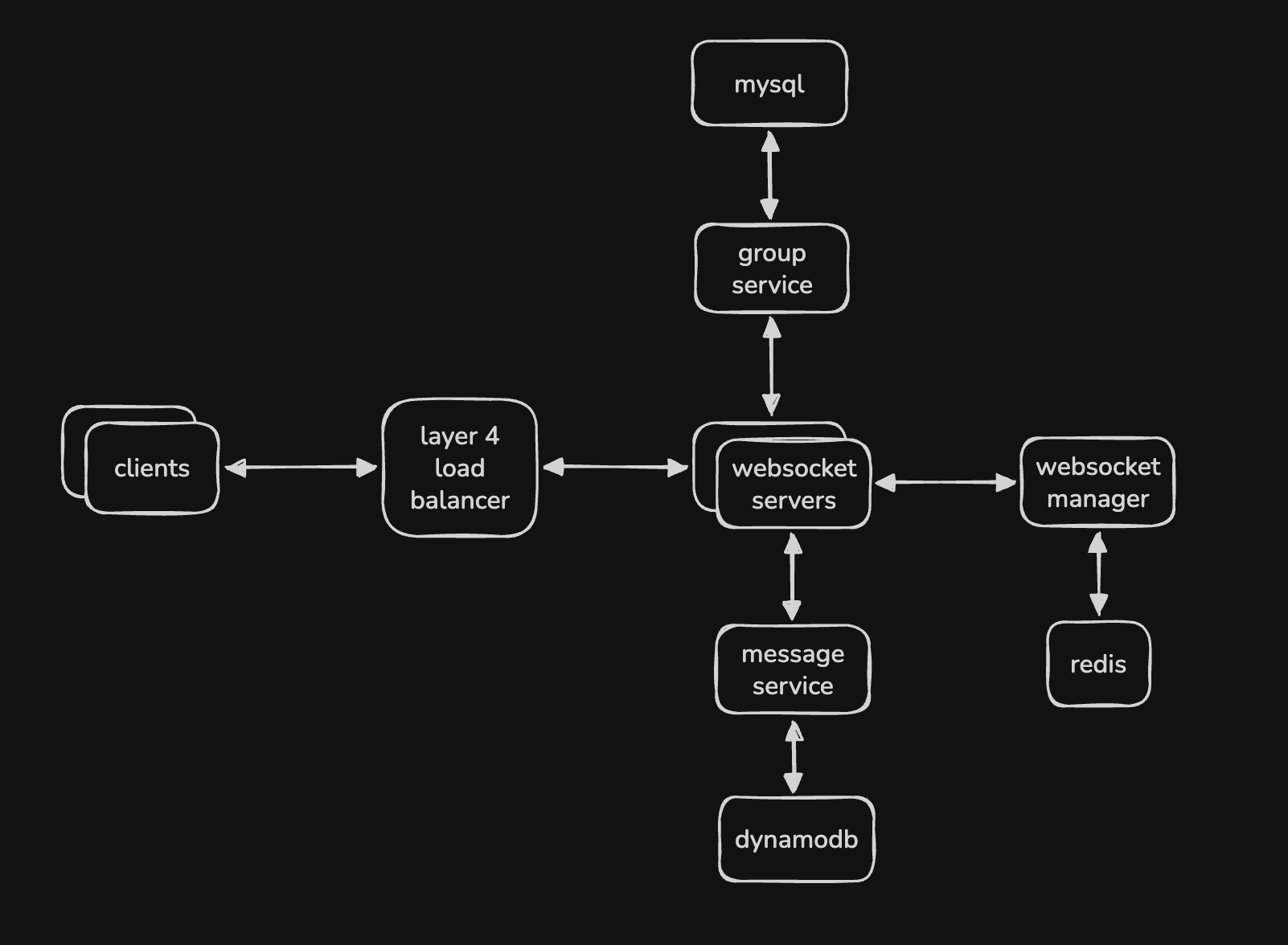
Handling Groups
- websocket servers can know from websocket manager which users are connected to which websocket server
- so, it works when a user communicates with another user directly
- however, the websocket manager cannot for e.g. tell it which users are a part of a group etc
- so, group messaging is handled differently
- assume we have a “group service” with its own mysql database, which manages the group metadata like name and description, membership of a group, etc all with consistency and scalability
- so, the websocket server would first query the group service to find the members of the group
- then, it would query the websocket manager to find which websocket servers these members are connected to
- finally, it would forward the message to the right websocket servers for delivering the message
- the design below not contains both logics for message service and group handling
Typeahead / Autocomplete / Suggestions
Requirements
- provides realtime suggestions as users type
- in this case, we assume it is based on “current trends”
- the suggestions need to be ranked as well
- low latency - under 200ms
- fault tolerant - provide suggestions even if individual components fail
- scalability - handle increasing number of users and suggestions
High Level Design
- as a user types, we do need to reload the whole page, but just update the suggestions list. we use “ajax” to achieve this easily
- a frequently searched term becomes a “trend”. so, there needs to be a “threshold” for this
- we might need to have different trends based on region
- in this case, the thresholds for different regions might be different as well
- we use a “trie”, since it helps with prefix based lookups
- additionally, this needs to be stored in ram for low latency
- however, it can be stored in disk for durability and recovery as well
- in the trie data structure, we can for e.g. collapse multiple nodes into one node if all the nodes along this path have only one child, something like xylophone for instance maybe
- now at the leaf node, we store the count of how many times the term was searched
- if a user types uni, the system first traverses all the descendants of uni
- then, it ranks them by their counts and finally returns the top k suggestions
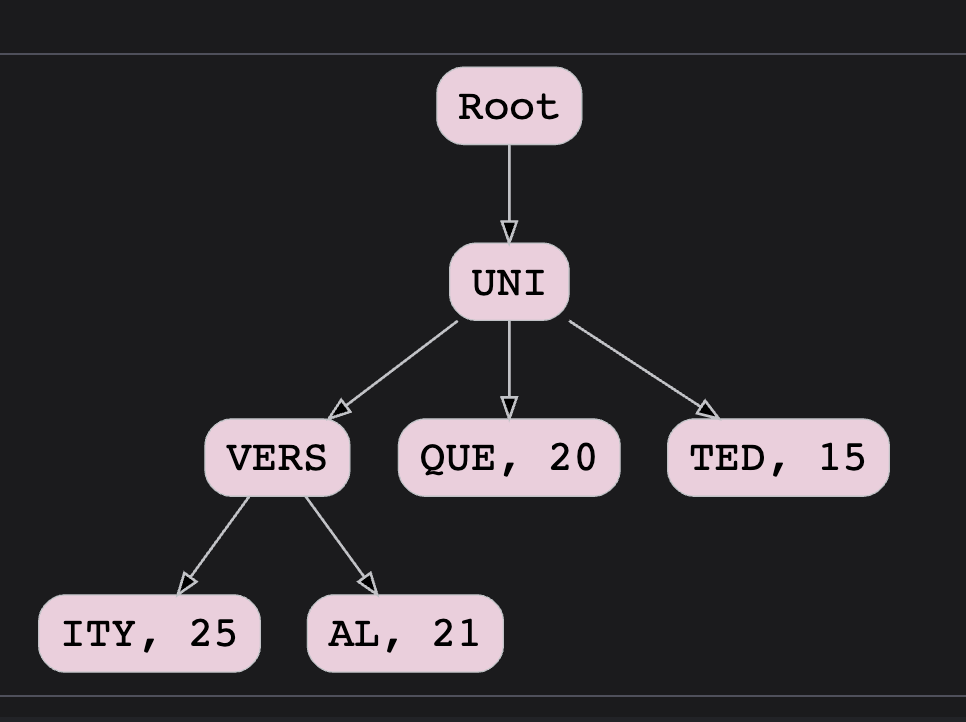
- now, to avoid traversing the whole subtree, we can store the top k ranked suggestions for each node
- tradeoff - this significantly increases the storage
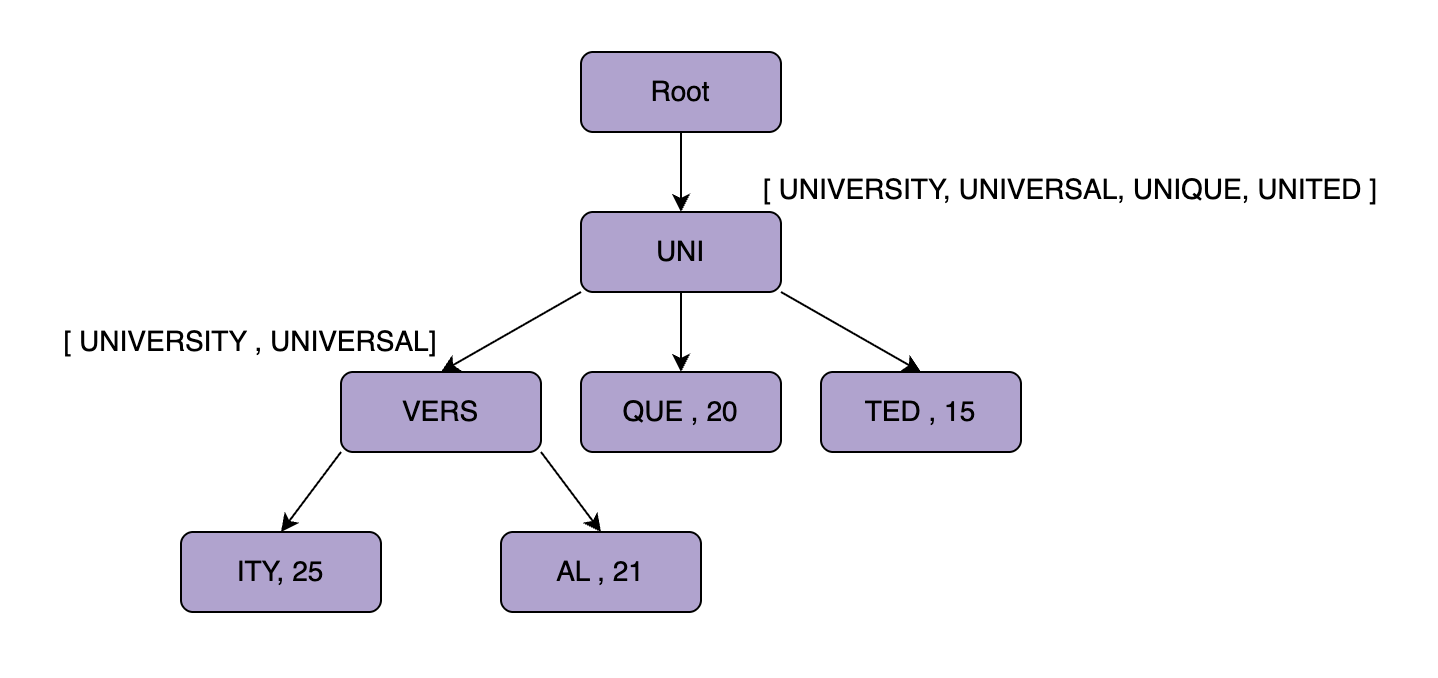
- “partitioning trie” - we cannot store the whole trie in a single machine
- so, we partition the trie by prefixes - e.g. a to m in server 1, n to z in server 2
- the mapping can be managed via zookeeper
- issue - hot / skew partitions
- solution - we keep splitting further, e.g. a to ea, ea to m and then n to z
- for incoming queries, the system queries zookeeper to find the right server, and then forwards the query to the server storing the trie partition
- now, we need to update the trie itself
- doing it realtime can have significant performance implications and is not required here
- so, we log the timestamp etc of the searches
- then an offline job that runs for e.g. hourly processes these logs
- it accumulates the count for each term and then updates the partition
- there can be multiple approaches for updating the partitions -
- approach 1 - we reconstruct the trie partition, and then swap it with the original partition
- approach 2 - we update the secondary replica, and then swap the primary and secondary replicas
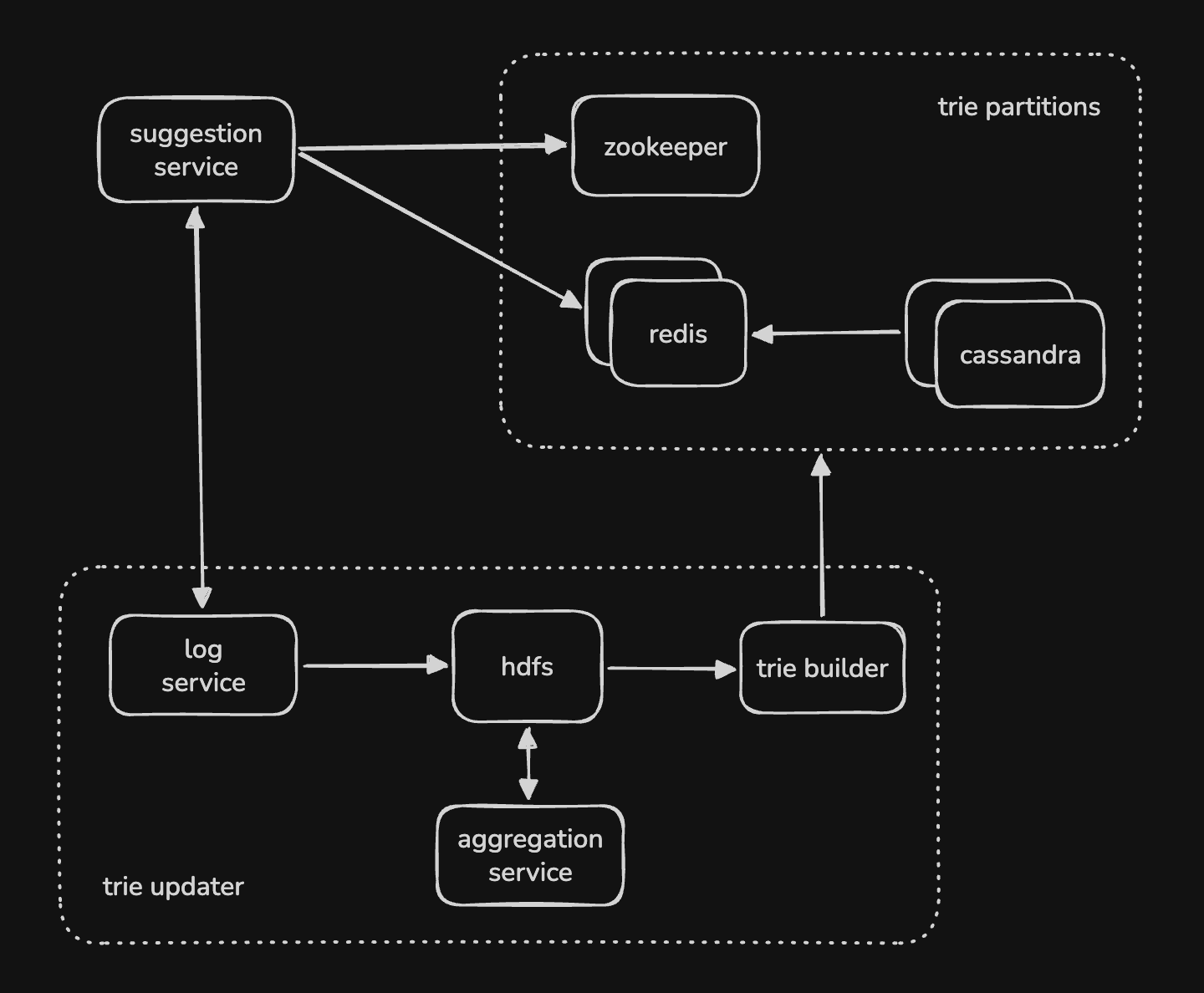
- “log service” - logs the searches
- “aggregation service” - aggregates the logs
- “trie builder” - builds / updates the trie partitions
- “suggestion service” - queries the trie partitions
Google Docs
Requirements
- collaborating on files by exchanging local copies is inefficient
- google docs solves this by allowing realtime collaboration
- multiple users can edit and view the same document simultaneously
- resolving conflicts related to concurrent editing - manual approvals in case of conflicts, prs etc work for git, but not in google docs where users expect realtime updates. the conflict resolution needs to be automatic
- users can see the version history
- suggestions for autocomplete, grammar correction, etc
- low latency for users in different regions
- consistency - users should see the same updated state
- this question can be framed as collaborative editing - design a collaborative whiteboard, realtime code editor etc all fall under this bucket
High Level Design
- api gateway to handle authentication, rate limiting, etc
- we use “websockets” for realtime bidirectional communication - they do not have the overhead of http headers, they enable bidirectional communication with low latency, etc
- the apis can look like this (notice the use of websocket api) -
- POST /api/documents - for creating the document
- WS /api/documents/{document_id} - for updating the document
- option 1 - we store the document in blob storage
- we use a “last write wins” kind of an approach here
- drawback 1 - we would have to rewrite and the whole document for every update. remember that object stores cannot handle edits
- drawback 2 - the whole document would have to be sent every time by the user. this would consume a lot of bandwidth as well
- so, this approach would be very inefficient
- so, we update the document periodically / batch the updates
- we can use a time series database for supporting version history and recovery
- this time series database holds the “edits” - e.g. insert(world, 5)
- now, clients fetch the latest document in the blob store, and then apply the edits from the time series database to it. e.g. if the time is 10.11am, and the document was last updated at 10am, the client would fetch the document from the blob store, and then apply all edits from the time series database between 10am and 10.11am on top of it
- cdn - cdn / caching may not be ideal for frequently changing documents. but i felt even if document in cdn is not latest, the remaining edits can be fetched from the time series database and applied to the document to get the latest version right
- how to scale the websocket server - we can use a consistent hashing mechanism, to ensure all users of a document are connected to the same websocket server. the document id can be treated as the key in this case
- my thought - this is possible here unlike in whatsapp because the scale is much less - the number of concurrent editors for e.g. for google doc is capped at 100
- if the software was something like google sheets, we could have locks for the different cells when using collaborative editing, and then we would not have needed the algorithms like operational transformation and differential synchronization described below
Operational Transformation
- this algorithm can be used to resolve conflicts during concurrent editing
- it transforms the operations in a way that they can be applied in any order, but still yield the same final document state
- below is just my layman understanding of how it works
- assume the document only contains “hello”
- user 1 edits and adds “my “ to the document. our app captures it as an edit - insert(my, 0)
- user 2 edits and adds “ world” to the document. our app captures it as an edit - insert(world, 6)
- first, i would think from the server perspective, what it captures in the time series database etc
- assume user 1 edit reaches our server first, and then edit 2 reaches
- after the first edit, the document becomes “my hello”
- however, the second edit position now has to change. the server now stores the edit as insert(world, 9) instead, to account for the first edit and resolve the conflict itself
- now, i would think from the client perspective, how their local copies are updated using the websocket
- user 1 updates their document to “my hello”
- our server receives the edit of user 2, and has to forward it to user 1 now
- our server knows that the edit needs to be “operationally transformed” for user 1 to insert(world, 9), so this transformed edit is what gets sent
- then, user 1 can finally apply this edit and load the right document
- when a new user joins, they just fetch the latest document from the blob store and apply all the edits from the time series database
- my thought - now, recall that only one server is consuming all the edits, so that the websocket can push edits to all users. this should automatically ensure that the edits come in the correct order
- drawback - this would have a lot of edge cases and permutations in the code base to handle
- if user 1 deletes vs user 2 inserts
- similarly, the other way round for order of operations i.e. 1st operation is delete and second operation is insert
- now, imagine the different kinds like bullets, images, etc - they might need to be handled in a different way
- so, there is another approach called crdts (conflict free replicated data types), which i am skipping for now
Differential Synchronization
- a much more intuitive algorithm to follow
- the user maintains two copies of the document - last synced copy and current copy that the user is working on
- then, the user sends the diff between the last synced copy and the current copy to the server
- the server receives this, and performs a diff against what is stored in the database vs what the user sent
- it first applies the diff, and then sends the diff back to all the users
- the users then apply this diff to their copies
- unlike operational transformation, it does not have the granularity - not every operation is captured and logged - it is instead performed in batches. so, features like showing the “cursor” is possible with this approach
Code Deployment System
Requirements
- “continuous deployment system” to automate software distribution across environments like staging, production, etc
- support deploying code to multiple machines distributed across multiple regions
- steps involved -
- commit to version control
- continuous integration tests
- generate build artifacts
- deploy it in a controlled test environment and run automated tests
- deploy to staging for final validation
- deploy to production
- monitor application performance and automatically rollback if needed
- mention the different deployment strategies like rolling, blue green, canary discussed here
Estimations
- assume there are 200 applications, each deployed 3000 times a day, and each build requiring 20gb
- so, daily storage = 12pb
- remember - this excludes different versions, compressions, etc and is a simple calculation
- bandwidth - assume it takes 5 minutes to push a build
- so, bandwidth = 20gb / (5 * 60) = 533.33mbps
- availability - it should be highly available, as engineers would use it to fix ongoing issues, perform rollbacks or forward deployments
High Level Design - Build
- first, we discuss the various apis
- trigger_build(project_id, branch, commit_id, build_configuration) -> build_id
- now using the build_id, we have apis to query status of the build, logs, artifacts, etc
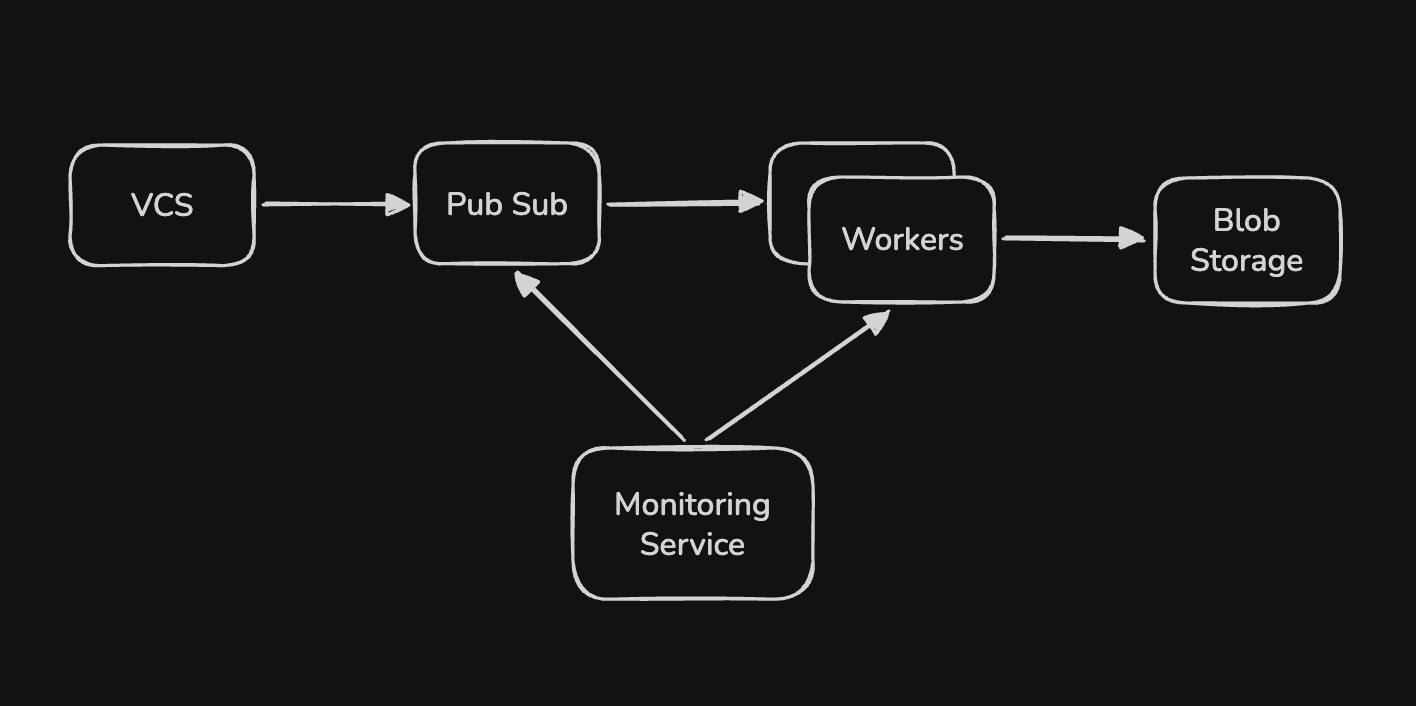
- when a user pushes the code to vcs, a build process is triggered
- the event is “queued” to the message queue
- we have multiple workers that can consume from this queue
- these workers run unit tests, generate the build artifacts, run integration tests
- for building, workers needs to pull the different dependencies - so, we can cache them to speed up the process
- finally, they push the build artifacts to a blob storage
- we can track the different builds in a sql table - it would have fields like status, sha, created_at, etc. we can query the status of a build using the build id using this table
- status can be queued, running, failed, completed and cancelled
- we need a monitoring system for the workers -
- the existing workers need to continuously be monitored using heartbeats etc
- workers can maybe autoscale based on queue size etc
- if a worker somehow fails during the build, just like we discussed in web crawler, the message would become visible again in the queue, and another worker can pick it up eventually
- we can also point out how many build metadata / artifacts to retain, how to perform cleanup, etc
High Level Design - Deployment
- first, we discuss the various apis
- trigger_deployment(build_id, strategy, environment) -> deployment_id
- using the deployment_id we have apis to query status of the deployment, trigger a rollback, etc
- now, during the build phase, we had pushed the build artifact to a blob storage
- one of the use cases was to deploy code to multiple regions
- pulling the build artifacts from the same regional blob storage to thousands of machines present in the other regions would cause a lot of overhead on the storage
- so, we instead replicate the binary artifacts to the blob stores of the different regions
- once a regional blob storage service completes replicating, it notifies the “deployment service”
- now, once a user calls the “deployment service” to deploy a certain build artifact / version, the machines pull the build artifact from their region’s blob store and run it
- improvement - now the machines instead of pulling from the blob storage in that region, can pull from each other. such a “peer to peer” mechanism is better thant the “client server” mechanism, as it avoids overloading the blob storage and allows us to utilize the bandwidth of the peers as well
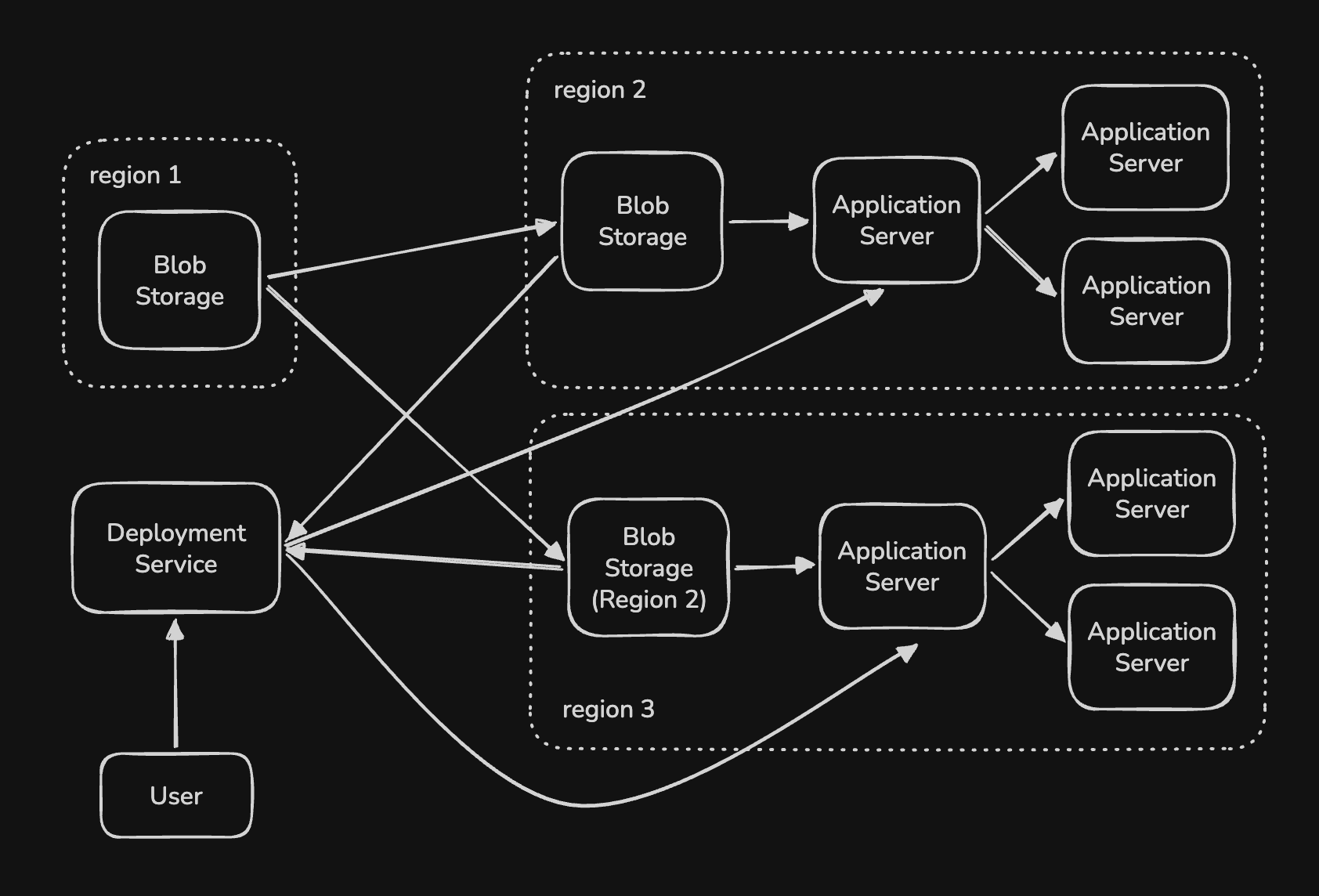
Stripe (PSP - Payment Service Provider)
Workflow (Functional Requirements)
- merchant’s app initiates the payment
- user submits payment request through the merchant’s app
- stripe forwards the request to an external payment provider like visa, mastercard, etc
- “authorization phase” - if approved, the funds are held, not immediately transferred
- the payment provider returns a code in this case, which our system needs to save
- “settlement phase” - finally, for e.g. once per day, stripe aggregates the approved payments and submits them
- the merchant can check the status of the transactions - pending -> authorized -> settled or declined
Non Functional Requirements
- security - encrypt sensitive data (in transit using tls, at rest using aes256), enforce authentication and authorization, add audit logging, etc
- strong consistency - ensure exactly once processing - no duplicate / missing payments
- durability (99.999999999%) - nine 9s - payments should be stored durably
Entities
- merchant(merchant_id, name, created_at, status[ACTIVE, INACTIVE, SUSPENDED, …])
- this helps us partition data by merchant, apply rate limiting rules per merchant, etc
- payment(payment_id, merchant_id, customer_id, amount, currency, status[PENDING, AUTHORIZED, SETTLED, DECLINED], …)
- transaction(transaction_id, payment_id, status[SUCCEEDED, FAILED, RETRYING], actor_response, actor_type(CUSTOMER, MERCHANT, PROVIDER), actor_id, …)
- actor response - the response returned by the actor - e.g. the code in case the actor is the payment provider
- actor id - id of the (customer / merchant / provider)
- why we should keep payment and transaction different - payment is the entity created to charge the customer. each payment might go through multiple transactions e.g. multiple retries in case of failures etc. these are modelled using transactions
High Level Design
- create payment (blue) - payment initiated by merchant. the request hits the “payment service”
- the payment service then creates a payment entity and stores it in the “database”
- we use postgres for strong consistency. we can scale the data by partitioning it using merchant id
- we can fetch the payment and its status via payment service as well (not drawn in diagram)
- authorize payment (green) - requests are buffered in kafka
- the “auth service” picks these, and then checks them with the “external provider”
- it accordingly updates the database
- using kafka removes slow network calls built with retries from customer experience
- settlements (yellow) - finally, the “settlement service” runs in the background on a cron to handle the settlements
Deep Dive 1 - Using State Machines
- state machine - helps us easily model something that changes over time
- both - payments and transactions have a set of valid states and transitions
- powerful where ambiguity is dangerous
- e.g. we should never be able to settle a payment that was never authorized
- important - modelling them as a state machine makes such invalid transitions impossible
- this prevents a lot of bugs that might otherwise surface in production
- state machines can also help configure such retries for the transaction’s state machine. here, mention strategies like exponential backoff. such auto recovery mechanisms are important for fault tolerance
- e.g. find the state diagram of payment here
- why captured is there between authorized and settlement - authorized phase helps to for e.g. check if sufficient funds are there. a separate captured state to model scenarios like out of stock items
PCIDSS
- in our current design, when a customer wants to confirm the payment, they send their payment details directly
- this means card details flows through our public apis, kafka, etc
- issue - storing data like credit card information requires pcidss level 1 compliance
- pcidss - payment card industry data security standard
- lot of encryption, hardware level compliance, etc, and enforcing all of this ourselves can become a huge task
- alternative - we use a pcidss compliant vault provider
- customers submit their card details to this service, which returns a token
- then, we store this token alongside the payment entity
- this way, we stay out of pcidss scope entirely
- the diagram shows the updated portion for the confirm payment flow
- so, in our payment entity, we do not store the credit card information, but this token instead
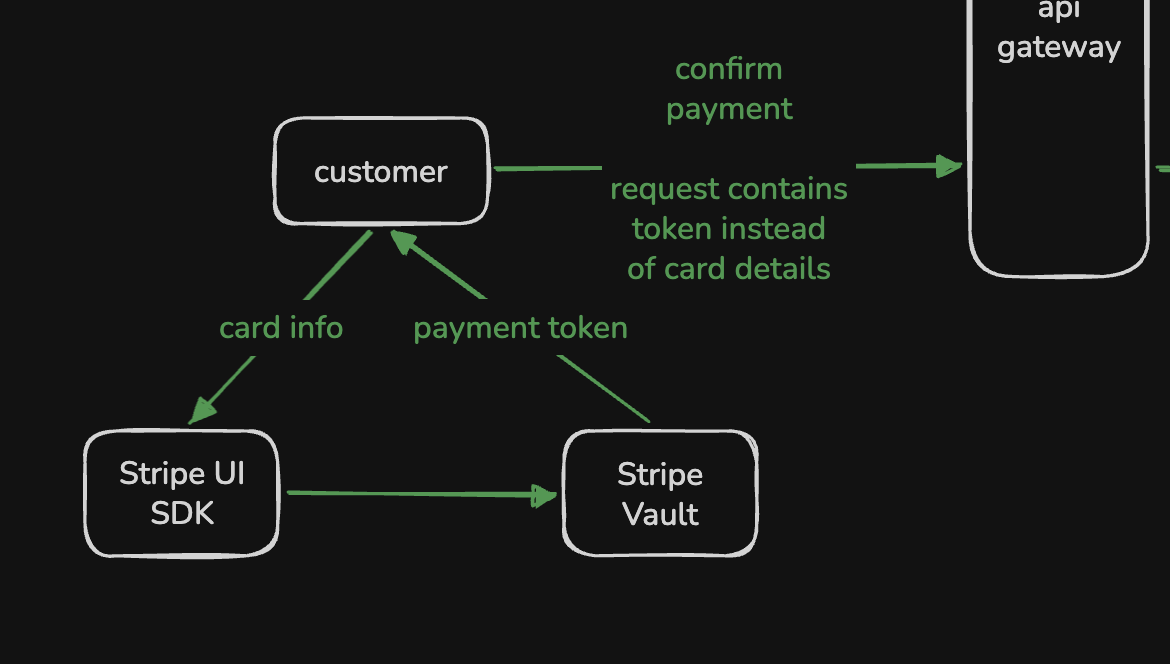
MTLs
- the different services communicate with each other without any authentication between each other
- if one service is compromised, the rest of the services would be compromised as well
- solution - mtls
- each service has a “unique” identity certificate issued by an internal authority
- the requesting service adds this to the calls
- the receiving service validates the identity and checks
Ensuring Exactly Once Semantics
- to prevent duplicates, we can use multiple approaches
- problem 1 - imagine the customers confirm the payment twice
- solution - every time the customers confirm the payment, they include an “idempotency key”
- the auth service would store this key in the database
- this way, even if the operation is retried because of some network failure, the auth service would know
- this can be for e.g. a uuid that the client generates and attaches to the headers
- the server can now store and query this uuid using its database - if an entry already exists, it simply returns the response without actually executing the payment
- this is the solution if asked for “double charges”
- problem 2 - imagine the auth service call to external provider passes but fails to save the changes in the database or vice versa
- solution - “transactional outbox pattern”. instead of calling the provider as part of the same transaction, commit it to an “outbox table” while updating the database about the payment. this way, a separate process can pick the calls up from the outbox table, and then call the external provider
- problem 3 - what happens if the batch settlement process fails - would we have to retry the entire batch, or from where we failed?
- solution - we keep saving updates to database - which transactions were settled etc. i was thinking that “spring batch” like frameworks might be helpful here
- finally, we can mention concepts around message delivery semantics, optimistic concurrency, etc
Double Entry Ledger
- every financial transaction should record two entries - credit and debit
- we do not simply decrease 100 from customer’s account and add 100 to merchant account
- instead, we append two events - “debit entry” and “credit entry”
- the pattern is called “event sourcing”
- it gives the entire audit - it allows us to the see / replay the history
- so, the current balance is “computed” by summing all the debit / credit entries
Webhooks
- merchants want to know when the payment is settled so that they can ship orders
- polling for updates manually is inefficient
- so, we can use webhooks to update the merchants about the same
- apparently, there is a method to build a robust webhook system as well, skipping it for now
- based on this deep dive, we would add the relevant components to our system
- for reference - https://www.youtube.com/watch?v=mZXJKcChCYo
LLM Powered Customer Support Bot
- traditional rule based chat bots fail when user inputs fall outside predefined scripts
- llms can interpret intent, maintain context across multiple exchanges and generate natural responses
Requirements
- maintain the multi turn conversation history, so that follow up questions can be answered
- understand the intent, extract order id etc from vague conversations
- generate accurate results instead of hallucinating
- map intent to actionable operations like checking order status, initiating refund, etc
- collect feedback to improve response over time
- transfer communication to humans when confidence is low
- low latency for inference to maintain the conversational feel
- encrypt data in transit and rest, comply with gdpr, etc
Estimation
- 10M DAU, with 10 prompts on average per user per day
- this gives us an average of 1000 qps for prompts
- so, we can tell the burst traffic would be approximately 10 times of 10k qps
- assume each generation will take 10s to complete. assuming the 10k qps above, it would mean we would have 100k concurrent generations at any point of time
- assume each chat is 10k tokens on an average - this means total (100M prompts * 10k tokens) tokens / day
- additionally, a 3 billion parameter model in fp16 (16 bit floating point) occupies around 6gb, which needs to be kept in memory of the gpu for inference
- assume that the request size is 2kb. using dau as a proxy for requests per second, we would need an incoming bandwidth of 10M * 2 = 160gbps
- similarly, if response size is 4kb, we would need an outgoing bandwidth of 320gbps
High Level Design
- “api gateway” - authentication, authorization, rate limiting, tls termination, etc
- “nlu service” - natural language understanding service. it is a pre processing layer used to classify intent. it extracts order id etc. it acts as a “triage layer”
- “llm router” - route simple questions like return policy, faqs, etc to light weight models. this helps save costs using a technique called as “tiered model selection”
- “rag pipeline” - convert prompt into “vector embeddings”, search vector database for semantically similar chunks, rank them by relevance, inject the top k results into the prompt. this helps give “grounded” answers and prevent hallucinations
- “llm core servers” - host the llm servers with “function calling” capabilities. this helps invoke external apis to check order status, refund, etc
- “vector databases” - stores chunked and embedded policy documents, faqs, troubleshooting guides, etc
- we have an “ingestion pipeline” to continually ingest data into this. real world data shifts away from the data the model was originally trained on. this architecture helps avoid this “drift” i.e. prevent outdated responses
- “redis” - for retrieving conversations quickly, thus avoiding repeated database lookups
- “monitoring service” - user satisfaction level, cost metrics, conversation logs, latency, etc. this can be “asynchronous” i.e. need not be part of the critical user path. also for e.g. help decide parameters like “chunk size” when storing embeddings in the vector databases
- “human escalation” - route to humans when llms cannot adequately solve a query
- “content moderation service” - scan llm output for policy violations, pii leak, harmful content, etc
- we can have caching, but this cannot be a traditional cache, as the intent, wording, etc of each prompt might be different. however, we can add a semantic cache which uses vector embeddings to find prompts or responses that were semantically similar. we can enrich our context and responses using the knowledge base in this vector database
- we use websockets for multiple benefits - we can stream responses from the server (typewriter effect)
- because of the bidirectional nature, we can also send events from the client - e.g. “stop” for abruptly stopping the generation of response
- as usual, mention the different options like long polling, server side events, etc here
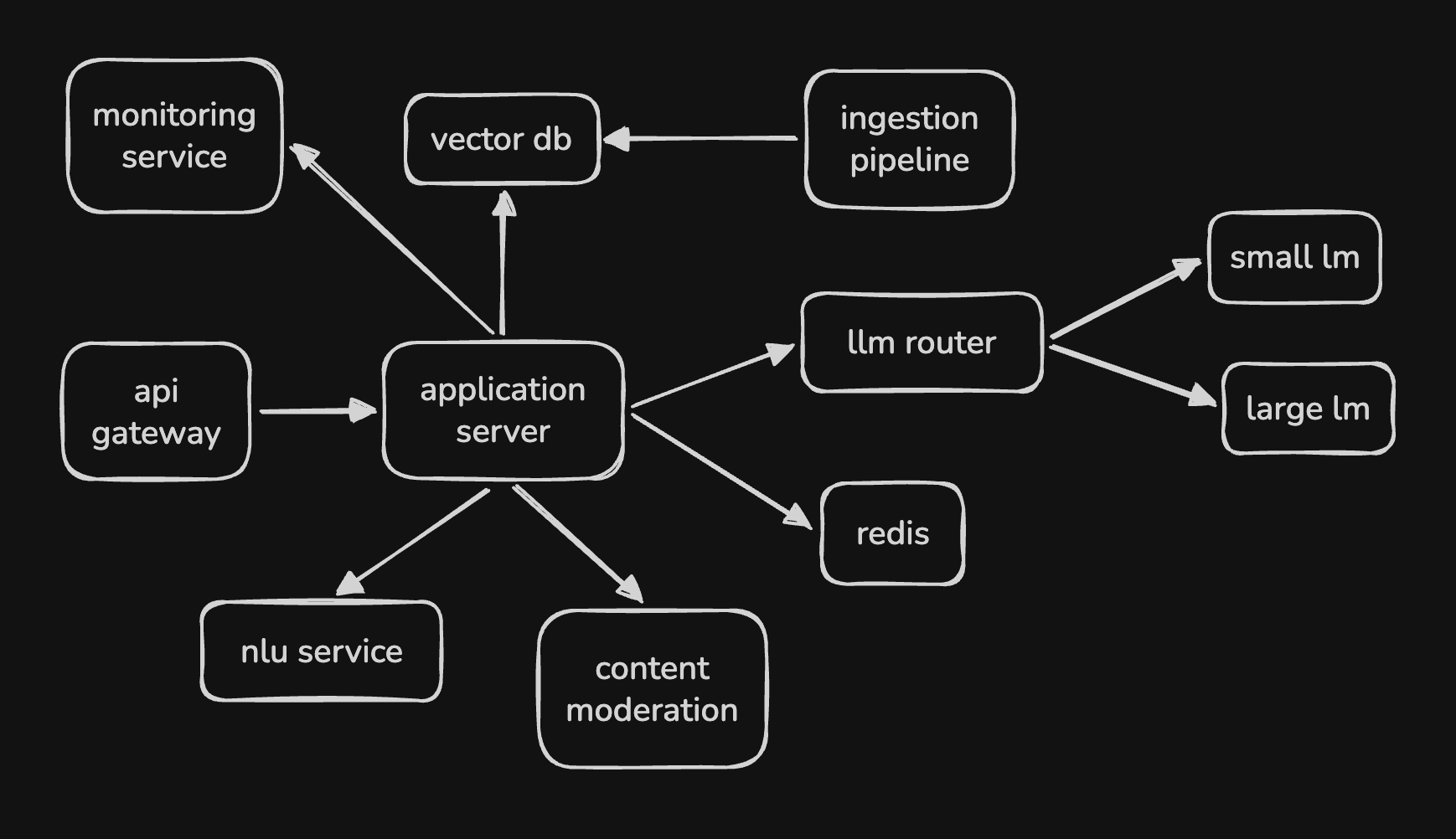
Rate Limiting
- a single user can have 60 completion requests per minute, and at most 2 concurrent generations per user
- users might be using multiple devices / tabs etc
- so, we need to mention the use of a centralized distributed rate limiter
- discuss the different rate limiter algorithms here
- for the chat completion endpoint, mention how we need to encode “concurrency” as part of our rate limiting algorithm i.e. how many concurrent requests can a single user have. the user can consume a token when his / her request starts, and we refill the token once this request ends
Avoiding Low Latency
- during less load, the model would scale down
- so, when requests arrive, it would be a “cold start” - there would be time spent in spinning up the workers, during which the user would be staring at a blank screen
- this would affect our sla, e.g. p95 of 300ms
- solution 1 - on a periodic basis, our “completion service” hits the models. this way, they stay warm. issue - it consumes tokens, is expensive, etc
- solution 2 - we use a proxy, like a load balancer in front of the model
- it would monitor the different metrics of the model - it routes traffic to healthy instances only
- it make dummy requests only when it sees the traffic dropping via its monitoring. this way, we do not spam the model all day like solution 1
- it would use patterns like circuit breaker - example if the model is down, it would route the traffic to a model in another region, or a less powerful model. this helps in degrading the service eventually instead of the flow breaking abruptly
- also, mention concepts around circuit breaker, retry patterns, etc here
- now, we would address the bottleneck at completion service
- solution 1 - completion service uses thread per request model. issue - this has bigger tail latency. additionally, we would hit the concurrency limits, have context switching overhead, etc
- solution 2 - completion service uses an “internal request queue”. the size of this queue is “bounded” (fixed), so if the incoming request cannot fit inside the queue, the service sends back an error
- a pool of workers will now consume from this queue
- it handles “back pressure” - when we get more requests than the server can handle, the requests are queued
- the cluster autoscaler for the completion service pods now will also depend on the queue lengths apart from cpu and memory metrics
- the gateway is also aware of these metrics, and forwards requests to pods with lower queue lengths, resource consumption, etc