Steps to Follow
- abstraction - we need to stay at the abstraction level of the system and not its low level implementation
- there is no one correct solution
- step 1 - ~ 5 mins - gathering functional requirements. it also helps “narrow down” the scope
- step 2 - ~ 5 mins - gathering the non functional requirements. helps ensure our system has the right quality attributes for the given workload
- step 3 - ~ 5 mins - combination of sequence and use case diagram. additionally, define the api of system as a part of it
- step 4 - ~ 15 mins - software architecture diagram for functional requirements - what data to store in what type of database, describe the flow of network requests, define the architectural pattern used, etc
- step 5 - ~ 10 mins - optimize the software architecture diagram to address the non functional requirements. add the components, remove the single points of failure, etc
- to help revise efficiently - skipping step 3, merging steps 4 and 5
- document effectively in the interview - interviewer might take snapshots which would be assessed later
Non Functional Requirements Questions to Ask
following are the typical generic questions to ask -
- number of users - ask for each actor separately
- performance in terms of percentile distribution graph - of different api calls
- availability percentage
- size of data / objects being stored
- number of events / api calls, etc
Social Media Platform
Gather Functional Requirements
- what information should the system store for a particular user?
- what type of media can be shared - only images, or videos / text as well?
- what type of relationship exists between users? - bidirectional i.e. friends, or unidirectional i.e. followers and following - unidirectional
- what kinds of timelines to support? - both user and home page
- social media platforms are typically very read heavy and not so much write heavy
- can anyone post / view, or there is registration / login required
- are the comments organized using a flat list or tree - flat list
Software Architecture
- user service -
- used for storing profile information
- store public information like user name, first name, last name, etc
- store private information like password, email, phone, etc
- store optional fields like location, interests, etc
- instead of storing profile image directly, store the image in an object store, and store the reference to this inside user db
- note - there might be optimizations like resizing around storing thumbnails
- instead of a new followers service, we can also track followers via user service itself
- it has a collection called “followers”, which stores the follower id and followee id
- i think we can index on both -
- follower id - retrieve influencers followed by a user
- followee id - retrieve followers of the post’s created by
- now, the entire user service can use a sql database, because of the nature of the data and the fact that the number of users should not typically be as much - we can also model the followers table as a many to many constraint
- we saw we can index on followers id, followee id, etc for faster access. optionally, we could have used redis as a layer of cache -
- key = follower id, value = followees - to retrieve all the people this user is following
- key = followee id, value - followers - all the followers of this user
- key = user id, value = profile - we might want to display a short profile of users alongside their posts / comments
- my understanding - we could have used cqrs pattern here to separate the redis into a separate query service. but i think here, its more around caching. cqrs makes sense when we want to use materialized view pattern as well
- posts service -
- a platform like twitter can have a huge number of writes. so, we use cassandra / dynamodb for storing posts
- comments are very similar to posts - have the same up votes / down votes fields, the same structure around the content, etc. so, instead of a new comments service, we can store the comments inside the posts service itself
- we can use the post id when sharding for posts
- we can use the post id when sharding for comments as well - this helps us easily retrieve the comments for a post
- second approach - compound index + range shard strategy
- we use a combination of the post id, comment id
- post id is the partition key, and comment id the sort key
- this way, all comments for a post can be fetched fast, since the comments for the same post will be located close to each other
- search service -
- used to help search for users and posts
- using a specialized search service can also help us with type ahead etc
- it will have its own nosql database with text search capabilities - e.g. elasticsearch
- users service and posts service communicate changes to search service via a message broker
- this is the cqrs pattern - hence, it is eventually consistent
- now, instead of always running elasticsearch through our query because searching through elasticsearch can be expensive, we can cache our results in redis as well. reason - there can be hot topics - e.g. elections, and we can cache the elasticsearch response for such queries
- timeline service -
- approach 1 - construct the timeline on the fly every time
- however, it is very inefficient - the complex query to posts service can become a bottleneck
- so, we use the cqrs + materialized view pattern
- we add a new service called the timeline service, which has the timeline for each user stored inside an in memory key value database, where the key is the user id, and value is the timeline i.e. list of posts
- first, the posts service publishes a message to the message broker every time a new post is created
- then, the timeline service calls the user service with the user id of the post, to retrieve all the followers for this user
- finally, it updates the database to add this new post to all these followers
- we use a queue like data structure to keep track of the latest n posts in the timeline for a user - first in first out i.e. the oldest post would be removed from the timeline
- so now, the client only needs to request the timeline service for the timeline of the current user
- then, it needs to fetch the posts (in bulk) from posts service
- finally, it needs to fetch all the assets from the object store
- downside - we now have eventual consistency as opposed to the strong consistency earlier
- we can also “archive” the timeline data - people might end up scrolling more, and instead of recomputing everything from scratch, the old timeline data can be stored again inside cassandra
- handling influencers -
- some users can be an influencer - they can have thousands or millions of followers, based on our system
- when the timeline service receives a post from such users, it will have to update the timeline of all of its followers, which means there can be millions of potential writes
- instead, we track for each user if they are an influencer or not via a boolean in the user service
- now as usual, for each post that the timeline service received from the post service, it tries to fetch all the followers for that user
- this time, since the user service knows that this user is an influencer, instead of returning all the followers, it will just return true for the influencer field
- the timeline service will just track the posts of all influencers in a separate collection - the key would be the influencer id, and the value all the posts by this influencer
- note - we can still use the redis for recent posts, and cassandra for archival
- now, when the timeline service is called for getting the timeline, it does not return the timeline directly
- it first fetches all the influencers the current user is following from the user service
- it then merges the timeline of the user with the posts by all the influencers this user follows and return this final list. the merge can be performed using the timestamp field
- a user could be following hundreds of normal people, but a very handful of them would classify as influencers. so, this technique of merging works the best
- scaling timeline service further -
- assume the functional requirement wants to support user timeline as well - we can look at the posts by a user after clicking on a user
- the user timeline will be designed in the same as the “influencer timeline” - the key would be the user id, and the value the entire timeline
- however, we maintain the timeline only for active users - and not for all users
- note - the same can apply to home page timelines as well i.e. we only maintain the home page timeline for active users
- e.g. our platform might have 2 billion users, but only 100 million of them are active, rest of them are passive users
- this helps us saves on disk space / infrastructure cost
- the active / inactive flag can be tracked inside user service itself, just like influencer / non influencer
- when an inactive user comes in - we first have to populate redis with the right active data
- then, we generate the entire timeline and populate our key value database with this
- scaling (generic) -
- we can horizontally scale all services and run them behind a load balancer
- sharding for all databases - remember posts service has an sql database, so might or might not be supported
- replication for all databases
- run the system in different geographical regions
- some other considerations -
- we can use connection management as described in realtime instant messaging, for pushing notifications about new posts by followers, when users are tagged in a post, when a user is followed by another user, etc. we use the choreography pattern here to help subscribe to events on the message broker, and then we use websockets to push these events
- assets - for storing media, we can use the optimizations we talked about in video on demand. we can perform compression, perform processing on thumbnails, use cdn, etc. assets of old posts should automatically expire from cdn, thus saving us on the costs for using the cdn
- given that tweets have a character limit, we might want to shorten the urls. we can do this using a url shortener
- to the timeline of a user, we might want to add posts based on their interests. so, we can have analytics running on users and on posts, to tag both these entities based on different parameters. finally, we can add matching posts to the timelines of all the relevant users
Video On Demand Streaming Service
Gather Functional Requirements
- can the content be modified - videos can be deleted but not modified
- what kind of information is provided along with the video
- mandatory - title, author, description
- optional - tags
- note - these fields can be updated
- does it support only video on demand or live streaming as well - live streaming is out of scope
- is there any particular video format we would like to support - all formats / codecs should be supported
- what kind of devices do we want to support - all - browsers and apps, with varying network bandwidths
- main functional requirement - close to no buffering
- should we support subscription based content - no
Software Architecture
- challenge - there are different formats, different aspect ratios, different bandwidths, etc that we need to handle - so too many combinations
- handling different formats of videos -
- videos can come inside different formats - each with different formats of audio, video, subtitles, etc
- some videos, e.g. ones taken from cameras can have very high resolution, since they use “lossless” compression algorithms
- this makes them ideal for video editing but not for storage / streaming
- so, we can use “lossy” compression algorithms to reduce the amount of data stored and transferred
- supporting varying devices -
- video size is ~ bitrate * video length
- so, to optimize the video size to support different devices and network conditions, we need to optimize the bitrate
- now, bitrate is directly proportional to the resolution and frame rate of the video
- so, for reducing the bitrate, we need to reduce the resolution and frame rate
- so, using the transcoder, we need to generate videos with different resolution and frame rate to support different devices
- supporting varying network conditions -
- network bandwidth is not stable - it can be different when the user started watching vs when the user is halfway through
- so, we can use “adaptive bitrate” or “adaptive streaming”
- we break the transcoded video into segments, each a few seconds long
- the client first downloads a “manifest file”, that contains the different resolutions, frame rate, etc available
- the app then based on this manifest and the device information that it has access to, downloads a few segments of the right encoding
- it evaluates the time taken to download these files, and then accordingly switches to a different bitrate based on the network conditions
- finally, the different devices support different kinds of video protocols -
- i think this is around the application layer protocol being used
- so, we need to package our transcoded video chunks according to the different protocols and then forward it to the client
- we use an api gateway to handle authentication and authorization
- video service -
- store the videos in an object store
- store the metadata (title, description, author, tags) in the document store of the video service
- content processing service -
- “pipes and filter pattern” can be used for it
- runs when the raw video has been finished uploading to the object store
- so, the final sequence of steps using a pipes and filters patter would be -
- chunking
- perform appropriate compression
- perform sanitization - flag piracy, only allow legal content, etc
- generate thumbnails for these chunks, generate subtitles using nlp, etc
- transcoding - convert to different resolutions and frame rates
- package for different protocols
- generate manifest and send the link to video service
- after completion of all these steps, the service publishes an event to the video service for it to store the link to manifest file
- finally, we also need to notify the uploader of the successful upload - this entire process is asynchronous because it can be very time consuming, and the uploader should know once the upload is complete
- search service -
- after the video service has all the necessary details for a video, it publishes an event to this search service
- this search service uses an optimized database for text search, and stores this event there
- note - elasticsearch can take care of type ahead, perform fuzzy searching for typos in complex names, etc
- this is also a cqrs pattern - video service is the command service, and the search service is the query service
- get videos flow -
- when a user searches for videos, their requests go to the search service, which returns the video ids
- then, when the user clicks on a video, they request for the video from the video service, which returns the manifest file, description of video, etc
- finally, the device will start requesting for the right video chunks from the object store
- my doubt - we can extend the presigned url here as well for subscription based content?
- upload videos flow - approach 1 -
- right now, our request for uploading videos goes through the api gateway to make use of the authorization features etc
- then, the video service routes it to the object storage
- this means we will have to scale our api gateway and video service to just support this uploading functionality
- upload videos flow - approach 2 -
- we can use “presigned urls” - this allows the client to make requests to the object storage directly for a limited time
- so now, the request to the video service does not contain the actual video - just metadata containing title etc
- the video service with its permissions then generates a signed url and sends it back to the client
- the client now uses this signed url to upload the video - thus bypassing the api gateway and video service
- cdn and its optimizations -
- to improve the video delivery time, we use a cdn. “push strategy” might work better because videos cannot be updated
- we need not store all the videos in all the cdns
- we can instead have a few main cdns with the actual content, and the smaller local cdns can only have the content that a user is likely to watch - e.g. german content need not be cached at an indian cdn
- we can pre compute and store these likely videos beforehand using ml models to improve on our non functional requirements
- additionally - all cdns need not be sent all chunks of all formats from the main cdns - we can kind of distribute these chunks among the local cdns, and then these local cdns can use a peer to peer like model to distribute the chunks among themselves - this reduces the load on our main cdn as well
- tagging a video -
- during the processing of video, determine tags for the video based on some machine learning
- then, add these tags to the video
- basically, for each chunk, we would determine some tags
- then, we would group all these tags by video id
- finally, we can choose the top x tags which are the most relevant, highest count, etc to obtain the tags for a video
- we can also tag users based on their watch history etc
- now, based on tags assigned to videos and users, we can send the right recommendations to users
Real Time Instant Messaging Service
Gather Functional Requirements
- one to one direct messaging or group messaging?
- three types of mediums need to be supported - one to one, groups and channels
- one to one chats are a specialized form of group chats only involving two users
- channels - other users can join or leave channels. useful inside companies, where employees can join or leave channels
- types of media supported - text based, sharing images / documents, video calls
- persisting chat history - e.g. a user is offline when they receive a message. should they see the message after coming back online?
- users should be notified immediately after receiving a message
- a user should be able to see both - previously read messages and all unread messages after going offline
- other messaging statuses to show -
- if a user is online - in scope. a user can click on the profile of a user to see if they are online
- if a user is currently typing a message - out of scope
- system needs to have close to no lag - it is a messaging system, unlike social media platform etc
Software Architecture
- approach for message delivery -
- user a gets the ip address of user b from our system
- then, user a talks to user b directly, and the communication does not go through our system
- benefit - since the system would not be involved, this approach can be easily scaled to millions of users chatting “one to one” (one to one is key) with each other
- drawback - hard to support groups and channels - the user would have to establish a connection to potentially thousands of users, which is not possible for mobile devices
- another drawback - messages would not be stored and hence be lost for offline users
- so, we proxy the messages instead via our system
- so now, the user sends the message and the target group / channel to our system
- our system then takes care of creating history, pushing it to the right receivers, etc
- delivering the messages -
- in the typical client server model, a request needs to be received first in order to send a response
- so, one approach - clients keep polling the server for messages
- disadvantage - polling from all the end users will lead to too much resource consumption, along with computation for potential inactive channels and chats as well
- so, we instead use “websockets”, which allow for full duplex, bidirectional communication
- note - websockets use tcp underneath
- first, the users establish the websocket connection with the server
- then, the server can push the messages / receive the messages using this connection
- user service -
- persist the user information - we can use an sql database
- step 1 - when searching for users, it should return the correct user
- as a part of this, index based on username to make this search faster
- worth pointing out - an additional user search service feels like an overkill - we do not need features like sophisticated autocomplete when searching for users
- groups and channels service -
- used to maintain groups and channels - recall that one to one messaging is a specialized case of group chats
- one groups table - (group_id, created_at, …)
- one channels table - (channel_id, channel_name, channel_url, owner_id, created_at, …) - users use channel url to join a channel
- a many to many table for storing which users are a part of which groups
- a many to many table for storing which users are a part of which channels
- index channel table by name for quick searching
- index the two many to many tables by group / channel id to look up all the members in a group / channel quickly
- step 2.1 - a user can make a call to this service to create a group
- step 2.2 - then, they can search for users and add them to the group
- creating a channel has similar steps, just that an extra step of searching and joining the channel might be involved
- step 4.1 - if the user is offline and comes back online later, they first request this service to know about the groups that they are a part of
- optionally, this can be backed by a redis key value store - serves as a cache, retrieving all members of a group becomes very fast - we use group id as key
- chat history service -
- one messages table - (message_id, group_id / channel_id, sender_id, text, created_at, …)
- step 4.2 - using the ids of the groups and channels that the user receives from the groups and channels service, the user requests for the chat history from the chat history service
- again, the complex sharding problem might arise - one shard might not be able to fit all the messages for a group, and so we use a compound index using group id, message id -
1 2 3 4
select * from messages where group_id = xyz sort by message_id desc
- messaging service -
- users establish a bidirectional connection with this messaging service
- step 3 - a user sends a message to the messaging service (group_id / channel_id, message). the messaging service does the following -
- step 3.1 - store it in the chat history service (asynchronously)
- step 3.2 - request for the users part of this group / channel from the groups and channels service
- step 3.3 - push the message to the currently online users via the bidirectional connections
- scaling message service - unlike other services, the messaging service cannot be simply horizontally scaled behind a load balancer, since it is not stateless
- e.g. we use a simple round robin load balancer in front of two instances of the messaging service
- assume user a is connected to instance 1, and user b is connected to instance 2
- if user a wants to send a message to user b, instance 1 will need to communicate this message to instance 2
- approach 1 - when our user base is “partitioned”
- if in our use case, we have dedicated groups - one group for company 1, one group for company 2, and so on
- we can have all users for a particular group aka company connect to the same instance
- in this case, we would have ensured all users of a particular company are connected to each other
- the idea is that we can be sure that users of one company would not want to communicate with another company
- we can also vertically scale each instance individually depending on the size of that company
- i feel this approach will work well in use cases like games - whenever there are smaller clusters of users, and users of different clusters cannot talk to each other
- approach 2 - when our user base is not partitioned i.e. any user can send a message to any other user
- we introduce a new connection service
- this “manages connections” via a key value store (redis) - it knows which user is connected to which message service instance
- now, when a message service instance receives a message, it asynchronously sends it to the connection service
- advantage of asynchronous communication between messaging service and connection service - the sender does not care about this flow, so it does not have to wait to receive a “message delivered” notification
- then, the connection management service (again asynchronously) asks the chat history service to backup the message and synchronously asks the group and channel service for the members of the group of the message
- finally, it notifies the right message service instances - it knows which message service instance is responsible for which user via its database
- handling race condition - user a sends message and user b comes online simultaneously
- user b’s call to chat history service does not return this message because this message had not been persisted yet
- user a’s call is unable to push the message to user b because this user has not established an active connection with connection service yet
- one solution - connection service polls chat history service for the messages of users with active connections and pushes them to the messaging service
- asset management -
- should have compression logic, discussed in depth in video on demand
- once the upload is completed successfully, the message in the connection service needs to be updated with the url before it starts pushing them to messaging / chat history service
- can use cdn for faster delivery, etc
- based on whether or not the messages are end to end encrypted, we can run analytics on message content
Type Ahead / Autocomplete for a Search Engine
Gather Functional Requirements
- what criteria to use for suggestions - most popular queries in the last 24 hours
- is spell checking in scope
- how many suggestions to provide - 10
- what languages to support it for - only english
- maximum length of prefix - 60 characters, beyond this we do not show suggestions
Software Architecture
- we need two api queries
- /complete?query=xyz - to help with autocomplete
- /search?query=xyz - used when the user hits the search button / selects one of the results. note - our analytics will be updated based on this, so “get” http verb might feel wrong
- solution 1 - trie
- a subtree contains words with the prefix the same as the path up to it from the root
- we can store the frequency of search in the terminal nodes of this trie
- disadvantage 1 - can become too big - with 60 character being the maximum limit, there can be 26^60 (if considering only lowercase)
- disadvantage 2 - for a given prefix, we would have to traverse all its branches and then even sort them based on popularity
- observations -
- our autocomplete suggestion has to be very quick
- the update corresponding to our search query can be slow
- so, we can use cqrs along with batch processing
- autocomplete service -
- resolves autocomplete related requests
- uses a key value store underneath, where the key is the prefix and the value is the list of results
- autocomplete updater service -
- triggered once the button / result is clicked
- receives a tuple of (search term, timestamp)
- this is then stored in a dfs for further processing
- now our big data processing workflow is as follows -
- read all the (search term, timestamp) tuples populated by the autocomplete updater service
- we have a mapper with the following steps -
- filter the tuples with timestamp within the last 24 hours
- for each prefix of this search query, emit a tuple of (prefix, search query)
- understand that the above mapper will emit all prefixes of a word twice if the autocomplete updater service populated it twice
- now, all the search queries with the same prefix should end up in the same computer, given our mapper outputs the prefix as the key
- then, the reducer can perform an aggregation to find out all the top k (10 in our case) searches for that prefix
- remember to run multiple instances of both mapper and reducer
- cdc - change data capture -
- we use a cdc pipeline to send changes in our dfs i.e. every time the results for a particular prefix change to the autocomplete service
- the autocomplete service reads these events and updates its key value store
- note how we do not surface the autocomplete queries from the dfs directly since it is inefficient
- instead we use the more optimized key value store
- we could also have used the reducer to write the results to the key value store directly, which too would have been very inefficient
- now, cdc will only send over the changes, as opposed to the reducer, which would have done a complete rewrite
- we can horizontally scale both autocomplete service and autocomplete updater service
- shard manager service -
- used for scaling the key value store
- the key value store being used should have sharding given the amount of data
- we can also use read replicas to help distribute the load
- both replication and sharding should be available for databases by default
- despite of all of the above, some shards like ones storing the prefix “how” can be hot, while others would not even be close
- the default replication mechanism will usually use the same number of replicas for every shard, which might not work in our case
- so, one approach is to have a “proxy” between the autocomplete service and key value store, which can dynamically increase the number of replicas for hot shards i.e. different shards can have different number of replicas based on our workload
- note - this is not a write heavy system, as much as it is a read heavy system. we can also use an sql like database - the number of read replicas of a shard need to be increased - we can use an active passive architecture here for the database, key value store is not necessary
URL Shortener
Gather Functional Requirements
- short url and actual url mapping should be maintained in a database
- generate a short url for a long url
- return the long url when queried for a short url
- traffic per day - 10 million urls per day
- we will run this service for a 100 years
- characters we can use - alphanumeric
Software Architecture
- calculation behind how many characters we should use -
- characters allowed = 26 + 26 + 10 = 62 characters
- number of urls to support = 100 * 365 * 10,000,000 = 365 billion
- 62^7 = 3521 614 606 000 - 3 trillion - so, our url shortener would have to use at least 7 characters
- popular hash generation techniques -
- md5 hashes are 16 bytes long = 128 (16 * 8) bits = 32 (128 / 4) hexadecimals
- sha1 is 20 bytes = 20 * 8 / 4 = 40 hexadecimals
- sha256 is 64 (256 / 4) hexadecimals
- sha512 is 128 (512 / 4) hexadecimals
- none of them work because we only need 7 hexadecimals - this feels wrong? we need to check log16(365 billion) = 10 hexadecimals? when we said 7, it included the whole range of both small and capital letters
- one solution - “ticket server” -
- we maintain a counter inside redis - remember - redis is an excellent choice for atomic incrementing counters
- all instances of our shortener request this instance for the next number
- issue - a single redis server might not be able to scale
- solution -
- e.g. we need 7 hexadecimal numbers i.e. 28 bits
- imagine we have 8 redis instances, and number them - 000, 001, 010 and so on using 3 bits
- remaining 25 bits are used by redis to generate the auto incrementing ids - each instance can generate 0 to 2^25 - 1
- so now, we have a unique number
- another solution - “token service” -
- when our shortener system comes up, it would ask our token service for a range to use
- each instance would be assigned a range - 10000-20000, 20000-30000 and so on
- now, the instance can generate 10000 urls before asking for the next range
- the token service need not worry too much about scaling - it would take some time for our shortening service instance to exhaust the 10000 range it has been assigned - so, it can use a regular mysql database
- a disadvantage - the instance can go down after being assigned a range from the token service and before exhausting this list entirely, and thus we have now wasted a range of numbers
- till now, we only took care of generating a unique 28 bit number - now, we can convert it to a hexadecimal number
- issue - 16 would map to just g, 17 to 10 and so on, but we would like to ensure urls of 7 characters
- solution - pad using a special symbol like
= - finally, we can use cassandra to store the short url to actual url mapping
- follow up question - analytics - how many times a short url was accessed etc - solution - put messages onto kafka, have a separate analytics service
Key Value Store
Gather Functional Requirements
- equivalent question - dynamodb, maybe others like redis, memcached, etc can draw inspiration
- use cases - customer preferences, shopping cart, etc
- key value stores are “distributed hash tables”
- we want our system to be configurable - applications can chose between high consistency and high availability models
- note - this cannot be done dynamically, only when instantiating our key value store
- we should always be able to write - availability > consistency
- scalability - add or remove servers easily with little to no impact on availability
- fault tolerance - operate uninterrupted despite failures
- get(key) - when choosing eventual consistency model, more than one value can be returned
- put(key, value) - server can store additional metadata alongside as well, e.g. version etc
- we can use md5 for generating a hash for the key
- if amount of data becomes too much, we can store the data in s3 and the link to this object in cassandra
Consistent Hashing - Scalability
- we pass our value through a hash function to obtain a hash
- “mod hashing” - used when the size of our hash table is limited - we can perform % m with the hash obtained from above
- problems when using mod hashing -
- what if we suddenly increase the number of shards? - the hash will change! e.g. we had 3 shards initially, our data was stored in shard 1 (3 % 3) + 1, but after the increasing to 4 shards, we would end up looking in shard 4 (3 % 4) + 1
- even distribution - we might end up having hot shards
- so, to avoid both these problems, we need to use “consistent hashing” instead
- using consistent hashing, when we add or remove a node, we should only have to re balance (1 / n)% of the data, where n is the number of nodes
- imagine a virtual ring like structure

- we set the servers randomly at some point on this ring
- we go clockwise to decide which key should go into which server
- imagine we have 2 servers initially
- data for keys 2, 3, 4, 5 and 6 go into server 7
- data for keys 7, 8, 9, 10 and 1 go into server 2
- suppose, we add a new server at 4
- now, we only need to re balance the data for keys 2 and 3
- we can similarly work it out in the cases when we remove a server
- now, we have handled issue 1 - change in number of instances without re balancing
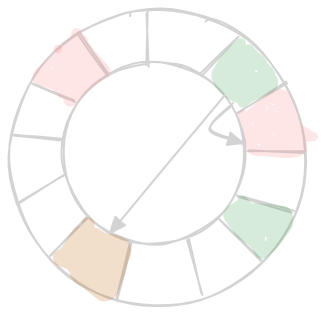
- with our current strategy, we can still end up with skewed partitions -
- workaround - we replicate the server in random places on the ring
- for calculating where the data should be in the ring - we use a single hash function and move in clockwise direction to find the responsible node
- for calculating where the node should be in the ring - we use multiple hash functions and place all these replicas on the right parts of the ring
- this is called a “virtual server” - our physical server is present on multiple parts of the ring
- another advantage - if we have a heterogenous architecture i.e. the node being added to the mix has more capacity - we can replicate it more times in the ring
Replication
- why an active passive architecture would not work -
- we want a write heavy system, and the active system can become a bottleneck
- there is a lag for acknowledgements from replicas
- therefore, we use an active active / peer to peer architecture
- the data is replicated into (x - 1) other replicas (not all n servers). this x is typically 3 or 5
- for quorum, it makes sense to have an odd number of replicas - quorum required for 5 replicas is 3, for 6 replicas is 4. so we can withstand 2 failures in case of both 5 and 6 replicas
- we find the virtual server responsible for our write in the ring - this is called the “coordinator”
- then, we replicate the data to the next x - 1 replicas in clockwise direction
- note - due to the virtual server concept we discussed, skip the virtual servers which point to physical server where the key is already stored. this way, we have our data stored in x different physical servers
Versioning - Vector Clocks
- issue - during network partitions / node failures, the version history of the same object might diverge across nodes
- so, we need some reconciliation logic
- so, we need to use versioning
- we can use timestamp, but it is not reliable in a distributed system
- so, we use “vector clocks”
- the idea is like git - if automatic merging is possible then good, else the client has to resolve the conflicts for deciding the ultimate value
- note - the client in our case is the load balancer / another node
- so, now our api works as follows -
- get requests return multiple vector clocks in case of conflicts
- put requests accept a vector clock to help resolve conflicts
- e.g. we have 3 replicas, A B and C
- first write goes to A, all nodes will have (A,1), value E1
- second write goes to A, all nodes will have (A,2), value E2 - this overwrites E1
- at this point, we have a network partition, and say A becomes unavailable as well
- third write goes to B, B will have (A,2), (B,1), value E3
- fourth write goes to C, C will have (A,2), (C,1), value E4
- now suppose the network partition is resolved
- now, when a write comes in, all nodes will have (A, 3), (B, 1), (C, 1), value E5
Load Balancer
- “generic load balancer” -
- the load balancer can forward the request to any of the replicas
- all servers are aware of the preference list for all key ranges - gossip protocol
- thus, they can forward the request to the right coordinating node
- disadvantage - has more latency, since there is an extra hop to reach the coordinating node
- “partition aware load balancer” -
- the load balancer itself is aware of the right partition to direct the read request to
- disadvantage - non trivial load balancer logic
r and w
- we maintain a “preference list” for each key - this contains the servers where the data is stored
- now, if we want to maintain x replicas, we do not necessarily wait for response from all x replicas for writes / reads
- r - for a get request - wait for r - 1 replicas to respond with their vector clocks and values
- if the histories of the total r replicas are divergent, return everything to the client to merge
- w - for a put request - wait for w - 1 replicas to acknowledge
- replicate to remaining x-w replicas “asynchronously”
- we need to ensure r + w > x
- this way, we ensure that at least one replica between r and w is common
- this way, we ensure we always get the latest value
- this is because at least w of them will have the value updated synchronously
- one of them would end up being used as a part of r
- e.g. x is 3, r and w can both be 2
- if r is 3 and w is 1, we provide speedy reads but slower writes
- similarly, if r is 1 and w is 3, we can have slower writes but much faster reads
Fault Tolerance
- “gossip protocol” - servers are able to communicate things like preference lists using this
- they send each other heartbeats, and this way the servers would know which servers are up and which ones are down
- we know that nodes are responsible for maintaining ranges of hash
- now, using “merkle tree”, hash of each key’s value is stored at the leaves
- remaining nodes of the tree contain the hash of all of their children
- this way, if the hash of a node in two different merkle trees match, we do not need to recursively check in the subtree and leaves
- e.g. look how we duplicate the value below if number of nodes are odd

Ride Sharing Service
Gather Functional Requirements
- should the system design the payment processing system and automate the payments -
- yes, collect payment from users
- track bank information of drivers to pay them
- should we consider eta -
- yes, ride matching should reduce the wait time of rider / reduce the distance traveled by the driver to reach the user
- we can use an external eta service
- can multiple people share a ride -
- yes, a driver can be matched to multiple riders if the riders want to share rides and the driver has capacity left in the vehicle
- how do we calculate the riders fee and driver compensation -
- it has three components - a flat fee, duration of the ride and the distance traveled
- the exact formula is not in scope, but we need to track the three parameters above
- is registering users and drivers supported -
- registering and logging in of users is supported
- registering of drivers is not supported, since they go through a background check, vehicle inspection, etc
- logging in of drivers is however supported
Sequence Diagram
- driver flow -
- the driver logs in
- then, the driver hits the “join button”, which adds them to the driver pool
- since this point, their location gets sent to our system every 5-10 secs
- rider flow -
- the rider registers / logs in
- then, the rider requests for a ride. the request contains their location
- the system looks for drivers - close to the rider, about to finish their ride, etc
- if the driver accepts the ride, they start sending the coordinates continuously to our system
- simultaneously, our systems keeps sending the location updates to the rider
- finally, once the trip ends, the driver hits the finish trip button
- the system sends both the driver and the rider the fare details
- once the payment is completed successfully, the driver’s account is credited with their pay
State Diagram
- the driver has 5 states - logged out -> logged in -> available for matching -> matched with rider -> in trip
- from in trip, they can either jump to matched with rider (if their current trip is about to end but they already have a match) or available for matching (if their previous trip has ended)
- the driver can transition into the logged in state when they do not wish to accept any further rides
Software Architecture
- user service -
- will contain two tables - riders and drivers. both should have name, auth information, etc
- note - the drivers table might have additional information like vehicle information
- the user service returns an authentication token on successful login
- payment service -
- store user’s billing information
- store driver’s bank information
- it will integrate with the different banks / credit card companies with their apis
- driver service -
- maintains a bidirectional websocket connection with the driver
- removes the overhead around establishing a new connection for every location update
- another reason - our system needs to “push” the potential riders to the driver
- rider service -
- just like driver service, a long bidirectional connection is maintained
- helps push updates from the system around driver location updates, etc
- location service -
- receives location updates from the driver service via a message broker
- benefit of this event driven model - we can use separation of concerns / decoupling
- location service has another functionality - to serve the matching service
- the matching service sends it the rider’s starting coordinates
- the location service can respond to it with the close by drivers
- given the location of user, we try to build a 1km radius and try to look for all the drivers in this range using the location service
- first challenge - how to optimally find drivers in 1km radius
- a technique used by location based services is to divide the earth’s surface into cells
- each cell is given a unique id, and the location service alongside the actual coordinates, stores this cell id as well
- now, we only need to know the cells that fall within the range of a given cell
- we also save ourselves from the complex distance computation involved when using latitude and longitude, which are floating point numbers
- this technique is called “geo hash”
- it is readily available in multiple databases and libraries
- second challenge - what if the direct distance is less than 1km, but the arrival time is more than an hour, given the u turn, some new construction and traffic
- so, we need to use an eta service
- while gathering functional requirements, we were told we can use an external service
- matching service -
- match the driver and rider
- the matching service accepts the user location request from the user service
- the matching service forwards this to the location service and receives the response containing (driver, eta) combinations
- after this, the matching service can contain complex logic -
- favor riders who have not earned anything yet
- consider drivers who are about to finish the trip
- consider sharing of ride
- then this gets sent to the driver service for acceptance
- once it receives the accept from a driver, it will notify the trip service about it
- the trip service can now create an entry in its database about the driver rider combination
- finally, the rider is notified about this as well
- i do not think matching service needs a database
- trip service -
- maintains the trip details
- calculates the fare details
- we can use the “event sourcing pattern” from the location service to trace the entire path. actually, this is the event sourcing + cqrs pattern discussed here. underneath, the event streaming capability of the message broker is being used
- the entire architecture is “choreography pattern”, since there is an event driven workflow between multiple services
- for scalability, we again hit the same issue for both driver service and rider service as in instant messaging. we solve it by introducing a connection service in between which tracks which user is connected to which instance. the matching service, trip service, etc can communicate with connection service, which calls the right instance of driver / rider service
- we want to minimize the login time -
- essentially as a part of the functional requirement, we want to immediately notify the user (driver or rider) if there are typos
- approach 1 - we use in memory hash set - if the username in the request payload is not present inside the hash set, we avoid performing the expensive database lookup to find the password, profile information, etc and immediately inform the user that the username does not exist
- drawback - storing millions of users in memory in each of our user service instance is infeasible
- solution - we can use bloom filters
- how hash set works - for each hash, it stores a linked list like data structure to handle collisions
- how bloom filter works - for each hash, it just stores a binary 0 or 1
- drawback - false positives - due to collision, it might happen that a user is actually not present in the database but holds one for the bloom filter
- one solution - multiple hashing functions. thus, the bloom filter will have to have 1 for all the computed hashes
- however, it is a tradeoff we make given our use case
- another drawback - we can only add values to a bloom filter, not remove them. should be fine -
- deleting a user is rare
- the bloom filter is recreated every time a fresh instance of the user service boots up
Video Conferencing Service
Software Architecture
- websockets -
- there can be functionalities like calling etc that we want to support
- so, we would need to have a client-server, websocket feature to be able to push such events
- now this connection can additionally be used for validating credentials of meeting (entering the right pass code) etc
- meetings -
- assume there are n participants. zoom has to send n-1 video streams to all the n participants
- the participants try to obtain the public ip addresses of each other - using the websocket described above
- finally, they can now start talking to each other directly
- so, we started from client server protocol and eventually switch to a peer to peer model using web rtc (realtime communication)
- udp is used underneath for faster delivery at the sake of lesser reliability - people would not (or sometimes even cannot) go back to hear what they miss
- issues and solutions for meetings -
- we still typically use ipv4, so we need techniques like nat
- recall how we had to exchange the ip address between each other using websockets
- “stun server” - tells a participant what its public ip address is - this would be a combination of the isp’s router’s public address and the port which helps with port forwarding
- now that a participant knows about its public ip address, it can send this via the websockets to other participants
- now, all the participants can talk using peer to peer
- issue - some nats or isp might or might not allow peer to peer communication directly
- so, we can use “turn server” instead - it is like the intermediary server through which calls are proxied
- so, we are back to the client server model when using turn server
- webinars / large conferences -
- issue with web rtc discussed in meetings - if there is a large conference, one participant (speaker) needs to send to few thousand participants
- here, the problem statement itself is different from meetings - the speaker is broadcasting, and others are just receiving
- handling so many peer to peer communications might not be possible by the small user device
- so, we use rtmp - realtime messaging protocol
- the speaker relays communication via an rtmp server in our system, which then forwards it to all the remaining clients
- now, unlike in meetings, we want more reliability around the speaker’s communication here
- so, rtmp uses tcp instead for guaranteed delivery, unlike web rtc described in meetings
- also, it is more client server here, unlike in meetings which was peer to peer
- my understanding - unlike in peer to peer, the transcoding in webinars is heavier - it supports adaptive streaming as well - the speaker’s resolution would depend on the participant’s bandwidth
- video recording -
- for meetings - clients send it asynchronously in batches to the “recording server”, without affecting the actual meeting
- for large meetings - rtmp server writes it asynchronously maybe to a dfs mounted on it, which can then eventually be sent to an object storage depending on use case
- now, we can perform optimizations like compression etc on these files, discussed here