Stream Processing Motivation
- popular spark cloud platform - databricks
- popular spark on prem platform - cloudera
- setup for databricks and local is already covered here
- when our iterations are done on a weekly, daily or even an hourly basis, we use batch processing
- issue 1 - backpressure problem
- it means data is coming at a faster rate than we can process it
- if we use batch processing, we need to do the following every time within the small window
- starting of the on demand cluster / resources
- processing the entire volume of data every time
- cleanup of the resources
- issue 2 - scheduling
- with batch processing, we can set a schedule / cron
- but that will not work if we want to process data in realtime
- issue 3 - incremental data processing
- we should process only the new data
- we can achieve this using checkpoints
- we will know using previous checkpoint what we have already processed and what we are yet to process
- issue 4 - handling failures
- what if during the processing, there is a failure?
- this is why we only commit our checkpoint after the entire processing is complete
- so, we read the previous checkpoint, perform the processing and if successful, commit the new checkpoint
- issue - we have two different transactions - committing of checkpoint and processing of data
- so, it can happen that processing of data is successful, but committing of checkpoint fails
- issue 5 - late events
- e.g. we have 15 minute windows to display the stock prices
- we show the output according to the data we have at 10am
- then, when processing the data for 10.15am, we receive an event for 9.58am as well
- this means our previously computed result for 10am needs to be updated as well
- spark streaming can address all these 5 issues for us
Getting Started - Word Count
- creating the spark session - the first option helps configure graceful shutdowns
- the second option is needed because the default is 200. the group by which we perform later causes a shuffle, and now we end up creating 200 partitions for a very small amount of data. so, we manually specify this
conf = ( SparkConf() .setAppName("Getting Started") .set("spark.streaming.stopGracefullyOnShutdown", "true") .set("spark.sql.shuffle.partitions", "3") ) spark = ( SparkSession.builder .config(conf=conf) .getOrCreate() ) - note about the above point - i see this important line in log, probably worth remembering -
spark.sql.adaptive.enabled is not supported in streaming DataFrames/Datasets and will be disabled - listening to the net cat producer -
lines = ( spark.readStream .format("socket") .option("host", "localhost") .option("port", "9999") .load() ) - we can start the netcat utility using
nc -lk 9999 - performing transformations - splitting the lines into words and calculating word counts -
words = lines.select(explode(split("value", " ")).alias("word")) word_counts = words.groupBy("word").count() - writing to the console - a spark streaming application continues to run indefinitely, unless it is terminated due to maintenance etc. this is what the
awaitTerminationhelps achieve - also, note how we have to provide the checkpoint location for this to work properly
query = ( word_counts.writeStream .format("console") .option("checkpointLocation", "checkpoints/getting_started") .outputMode("complete") .start() ) query.awaitTermination() - note - assume we had multiple streaming dataframes in our spark application. we would use the following -
spark.streams.awaitAnyTermination()
Stream Processing Model
- spark will start a background thread called streaming query
- the streaming query will start monitoring the streaming source - e.g. text directory
- the streaming query will also initialize the checkpoint location
- each execution of the streaming plan is called a micro batch
- micro batch is basically responsible for the small piece of data in the stream
- a micro batch is triggered every time a new file is added to the text directory
- our data is processed and written to the streaming sink
- each micro batch is basically a “spark job”, composed of the stages and tasks
![]()
- finally, the streaming query will commit to the checkpoint location
- recall how all the issues we discussed - scheduling, incremental data processing, handling checkpoints, are all being done by the streaming query
- the earlier model was “dstream apis”, built on top of rdd
- however, it did not have the optimizations that structured apis had, did not support “event time semantics”, etc
- so, we now use the “structured streaming apis”, that is built on top of the dataframe / structured apis
Triggers
- we have the following options for triggers types
- unspecified (the default) - trigger the next micro batch once the previous micro batch execution is over
- fixed interval / processing time - trigger the next micro batch once the specified interval is over
- if previous micro batch takes less time than the interval, wait till the interval is over
- if previous micro batch takes more time than the interval, kick off the next micro batch immediately
- available now - one micro batch to process all the available data, and then stop on its own
- we use third party schedulers in this case, and start and stop the spark cluster once the job is finished
- it is like batch processing but with features like incremental data processing from spark streaming
- continuous - for millisecond latency use cases. it is still marked as experimental
- example of specifying a trigger -
.trigger(Trigger.ProcessingTime("1 minute")) - max files per trigger - helps keep micro batches small in case a lot of files get queued up, and thus produce outputs faster
word_counts.writeStream .option('maxFilesPerTrigger', 3) # ... - so, if we have max files per trigger set to 1, available now set to true and we have 10 files in the queue, our job stops after 10 micro batches are processed successfully
- kafka too has a similar option to control the data processed by a micro batch - max offsets per trigger
- optionally, we can either clean up the files from the source or archive the files in the source (by moving them to a different place)
Output Modes
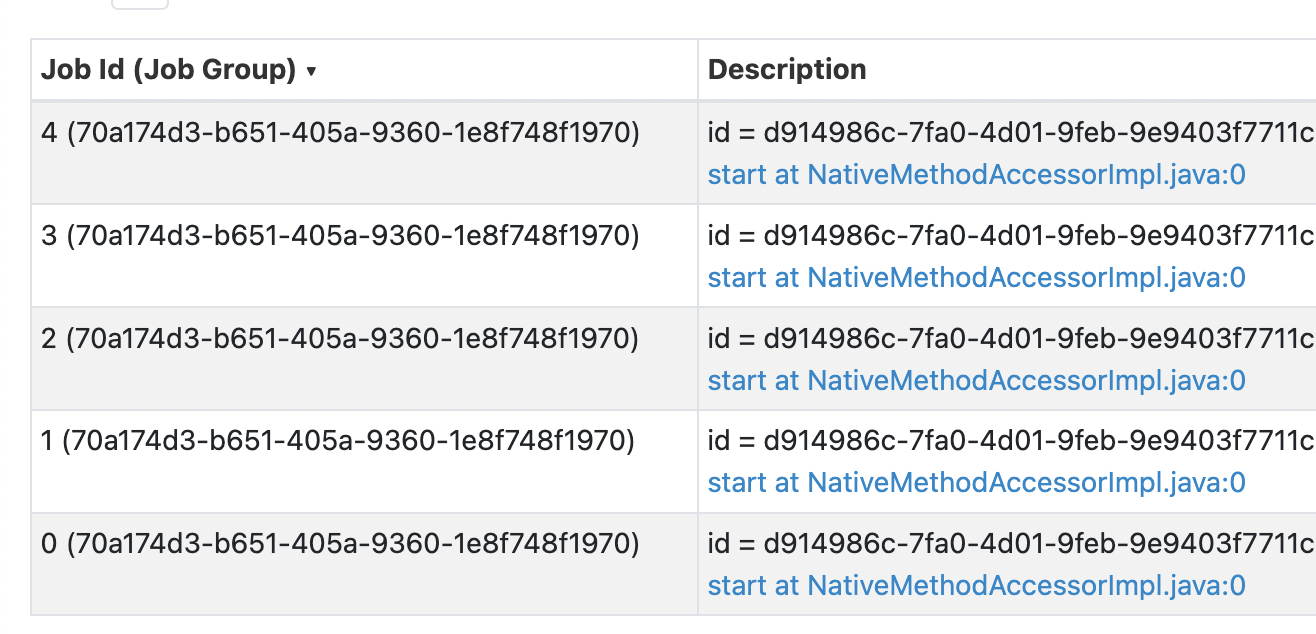
- e.g. assume our inputs are these for the word count example, and assume both are consumed as part of separate micro batches
- hello spark streaming
- hello spark programming
- append - insert only operation - when we are sure that each micro batch will only write new records, not update existing records. i get this error when trying to use it -
pyspark.errors.exceptions.captured.AnalysisException: Append output mode not supported when there are streaming aggregations on streaming DataFrames/DataSets without watermark; - why this error - creating groups in streams means we will update those groups. however, append only adds new records and it does not update existing records. hence, the error
- update - like an upsert option. note - in the output, we will only see records that were updated, not the records that were not updated
![]()
- complete - we get the complete result in the output every time
![]()

Fault Tolerance and Restarts
- stream processing applications are expected to run forever
- however, they would terminate at some point - due to some maintenance tasks, or some unforeseen failure
- so, the application should be able to stop and restart gracefully
- we want to achieve “exactly once” processing -
- we do not want to miss any records
- we do not want to create duplicate records
- spark streaming achieves this using “checkpoints” and “write ahead log” techniques
- it “commits” checkpoints, maintains “intermediate state” being processed by the current micro batch, etc inside its checkpoint directory
- so, spark itself has the ability to restart from the failed micro batch
- however, some external features we need to consider -
- replayable source - we should be able to re-read the data for the failed microbatch from the source. my understanding - e.g. kafka has the ability - read from specific offsets, as long as we are within the configured retentions. however, socket (the netcat utility we saw for word count) does not have this ability
- our sink should be idempotent, so that we can upsert the recomputed data
- finally, in case we make fixes, the nature of our fixes would determine whether or not the same checkpoint data can be used - e.g. if we add an additional filtering clause, the same checkpoint can be used. however, if we change our group by clause, spark would throw an exception if we try to resume our application
- cleanup of old checkpoints can be managed by spark using
spark.sql.streaming.minBatchesToRetain. it defaults to 100 - the management of checkpoints can be made asynchronous
- the state management can be implemented using rocksdb instead of the default jvm implementation
- be sure before implementing either of the optimizations above
Integration With Kafka
- how it works internally - spark commits the offsets it has read upto to the checkpoint directory
- this way, if the application is restarted, spark can pick up from where it left
- for the kafka integration to work, i added the following config -
.set("spark.jars.packages", f"org.apache.spark:spark-sql-kafka-0-10_{scala_version}:{spark_version}") - this is how we can read from kafka -
records = ( spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "invoices") .load() ) records.printSchema() - note - by default, it reads from the latest offset. we can change that behavior as well
- the schema output looks as follows -
|-- key: binary (nullable = true) |-- value: binary (nullable = true) |-- topic: string (nullable = true) |-- partition: integer (nullable = true) |-- offset: long (nullable = true) |-- timestamp: timestamp (nullable = true) |-- timestampType: integer (nullable = true) - so, to convert the binary type of value to the desired json type, we can do the following -
- step 1 - cast the value to a string
- step 2 - predefine the schema
- step 3 - use
from_jsonto convert from the json string to spark types using the schema
from pyspark.sql.types import StructType, StructField, ArrayType, StringType, DoubleType, IntegerType, DataType schema = StructType([ StructField("InvoiceLineItems", ArrayType(StructType([ StructField("ItemCode", StringType()), StructField("ItemDescription", StringType()), StructField("ItemPrice", DoubleType()), StructField("ItemQty", IntegerType()), StructField("TotalValue", DoubleType()) ]))) ]) # ... invoices = ( records # below is the main line .select(from_json(col("value").cast("string"), schema).alias("invoices")) .select(explode("invoices.InvoiceLineItems").alias("InvoiceLineItems")) .select("InvoiceLineItems.*").drop("InvoiceLineItems") ) - for writing to kafka, we need to transform our dataframe to have two columns - key and value
- for value, we first use the
structfunction to nest specified columns inside a parent struct column. the struct function receives a list of columns, and bundles all of those columns inside a struct type - then, we use
to_jsonto format this struct column as a json stringinvoice_records = ( invoices .select( col("ItemCode").alias("key"), to_json(struct("*")).alias("value") ) ) invoice_records.printSchema() # |-- key: string (nullable = true) # |-- value: string (nullable = true) query = ( invoice_records.writeStream .queryName("Kafka Demo") .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .outputMode("append") .option("topic", "notifications") .option("checkpointLocation", "checkpoints/kafka_demo") .start() ) - for writing using avro, we need to add the library for spark and avro integration first -
packages = [ f"org.apache.spark:spark-sql-kafka-0-10_{scala_version}:{spark_version}", f"org.apache.spark:spark-avro_{scala_version}:{spark_version}" ] # ... .set("spark.jars.packages", ",".join(packages)) - then, simply change the
to_jsontoto_avroas follows -from pyspark.sql.avro.functions import from_avro, to_avro # ... invoice_records = ( invoices .select( col("ItemCode").alias("key"), to_avro(struct("*")).alias("value") ) ) - note - recall how we defined the schema using spark types when using
from_json. however, when usingfrom_avro, we need to specify the “avro schema” using a json format inside a separate file altogether -from pyspark.sql.avro.functions import from_avro, to_avro schema = open("examples/src/main/resources/user.avsc", "r").read() output = df \ .select(from_avro("value", schema).alias("user")) # ...
Stateful and Stateless Operations
- we saw how spark structured streaming runs using micro batches
- if we have a group by clause, the groups would be stored inside the “state”
- this way, for new incoming records, spark can either update the existing groups, or create new ones
- it does not store all the historical records, e.g. if the aggregation used is sum, maintaining the running total for all the groups in state is enough
- so, we have two kinds of transformations -
- “stateless transformations” - like flat map, map, filter, etc - which do not require state
- “stateful transformations” - like joins, aggregations, windows - which require state
- note - i feel like they are one to one with narrow vs wide transformations. while narrow / wide transformations are batch processing concepts, stateful / stateless transformations are stream processing concepts
- implications - if we only have “stateless transformations”, the “complete” output mode would not be supported, only append or update output modes would be supported
- this is because in stateless transformations, for each input record, we get one or more output records. and storing all of this inside the state is not efficient
- we also need to be careful with our state - storing too much state will result in out of memory exceptions, because state is stored inside the memory of executors after all, even if it is committed to the checkpoint location regularly
- so, we have two kinds of state - “unbounded state” and “time bound state”
- “unbounded state” - we just have a group by and aggregation. assume we are grouping based on customers. this way, our state would be ever growing as we keep receiving new customers. this way, we can get into out of memory exceptions
- “time bound state” - they use for e.g. “window aggregations”. the difference is, we can expire records / state older than for e.g. a week, thus preventing our state from being ever growing
- this is why, spark also has concepts around “managed stateful operations” vs “unmanaged stateful operations”
- we saw above how “unbounded state” is ever growing. so, instead of spark managing the state for us in this case, we can take over and use “unmanaged stateful operations” to for e.g. remove the state for customers that have been inactive for a long time. however, we can still continue to rely on “managed stateful operations” for “time bound state”, e.g. graphs showing stock prices for the last month
Event Time and Windowing
- the “time bound state” we talked about earlier are a result of “window aggregations”
- “trigger time” - represents the times at which a microbatch starts. this will tell us the “frequency” of our microbatch. e.g. the trigger times can be at 10.00, 10.10, 10.20, and so on
- this is set via the
.triggeroption in thewriteStreamclause we discussed here - “event time” - when the event was actually generated
- window aggregates have their own “interval”. this can be quicker or slower than the trigger time
- e.g. it can happen that our microbatch triggers every 15 minutes. however, our windows could be of duration 1 minute or 20 minutes
- code for window aggregations -
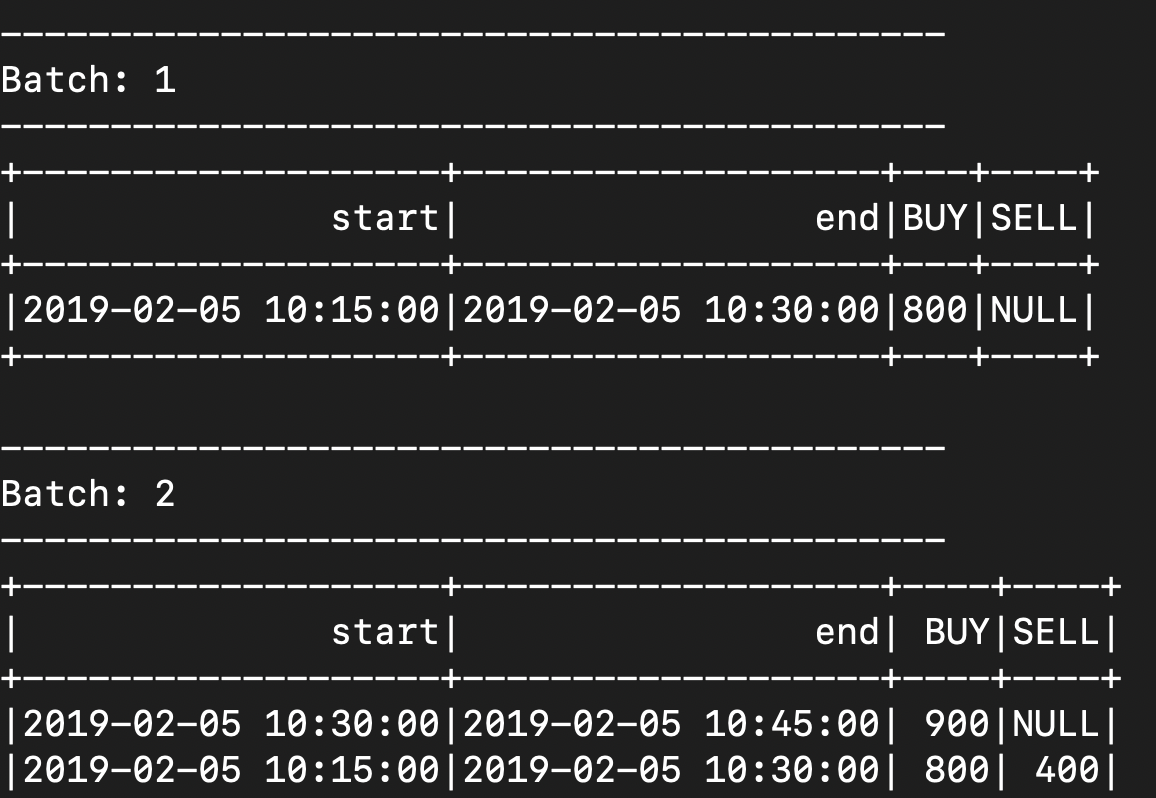
records .groupBy(window(col("CreatedTime"), "15 minutes")) .agg( sum(expr("case when type == 'BUY' then amount end")).alias("BUY"), sum(expr("case when type == 'SELL' then amount end")).alias("SELL") ) .select("window.*", "BUY", "SELL") - “late events” - when some events appear after its corresponding window has already been processed. e.g. we received events for 10.40, and therefore our microbatch generated windows for 10.30-10.45 in the output. however, for the same microbatch, we also receive events for 10.25. however, assume that the window for 10.15-10.30 had already been generated. therefore, spark will go and “update” the output for the windows of 10.15-10.30. output mode is “update” for the below screenshot
![]()
- important note - when using window aggregations, while sum etc is supported, complex aggregations like “window functions” etc are not supported. recall that window functions was where we specified the partition and order clause, do not confuse window functions and window aggregations
Watermark
- “watermarks” - we needed to store old windows to be able to handle late events. however, to prevent out of memory exceptions discussed earlier, we use “watermarks” to clear older windows
- e.g. if we show the graph for trades for the last 3 months, we can expire the windows for before that
- the business can come to us like this - we expect 99.99% accuracy. based on this, we derive that 99.99% of events reach us within 15 minutes of delay at most. hence, we can use a watermark of 15 minutes
- we can set the watermark using the following - we specify the “event time” column and the duration threshold -
.withWatermark("CreatedTime", "30 minutes") - how does spark perform the cleanup? “after” a microbatch gets over, it computes / updates the maximum “event time” it received till now
- based on that, all windows with end time before this maximum - “threshold” are ejected from the state
- assume watermark is 30 minutes and window aggregation is over 15 minute windows
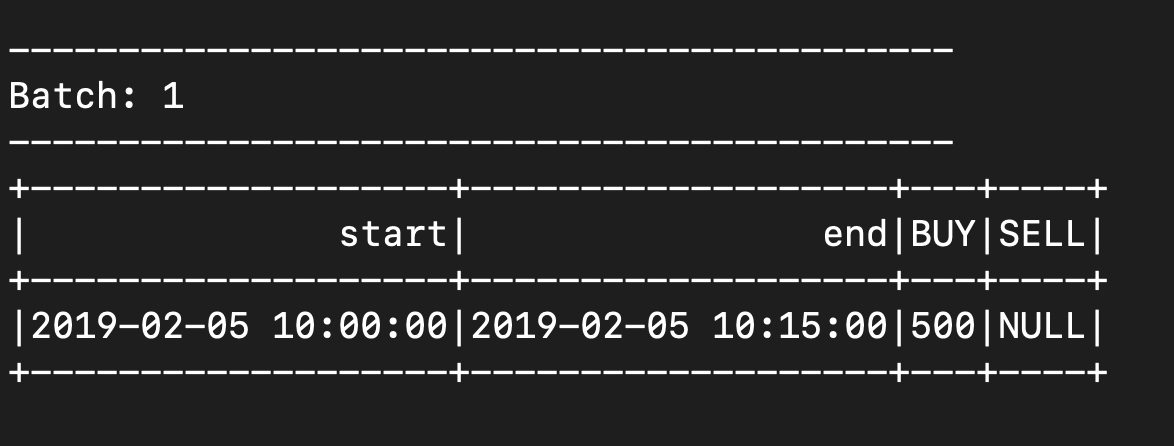
windows = ( records .withWatermark("CreatedTime", "30 minutes") .groupBy(window(col("CreatedTime"), "15 minutes")) .agg( sum(expr("case when type == 'BUY' then amount end")).alias("BUY"), sum(expr("case when type == 'SELL' then amount end")).alias("SELL") ) .select("window.*", "BUY", "SELL") ) - 1st microbatch - after it completes, max event time is updated to 10.05. no windows are expired
{"CreatedTime": "2019-02-05 10:05:00", "Type": "BUY", "Amount": 500, "BrokerCode": "ABX"}![]()
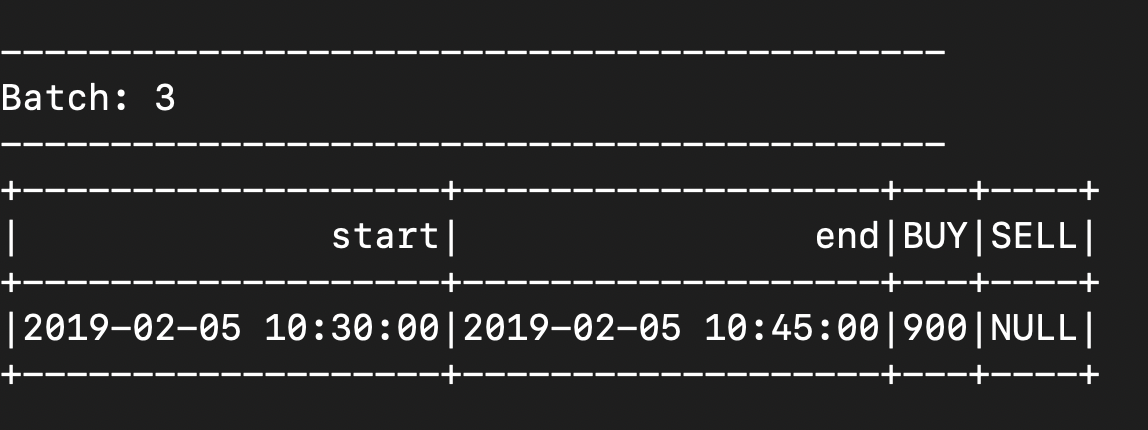
- 2nd microbatch - after it completes, max event time is updated to 10.40. no windows are expired
{"CreatedTime": "2019-02-05 10:40:00", "Type": "BUY", "Amount": 900, "BrokerCode": "ABX"}![]()
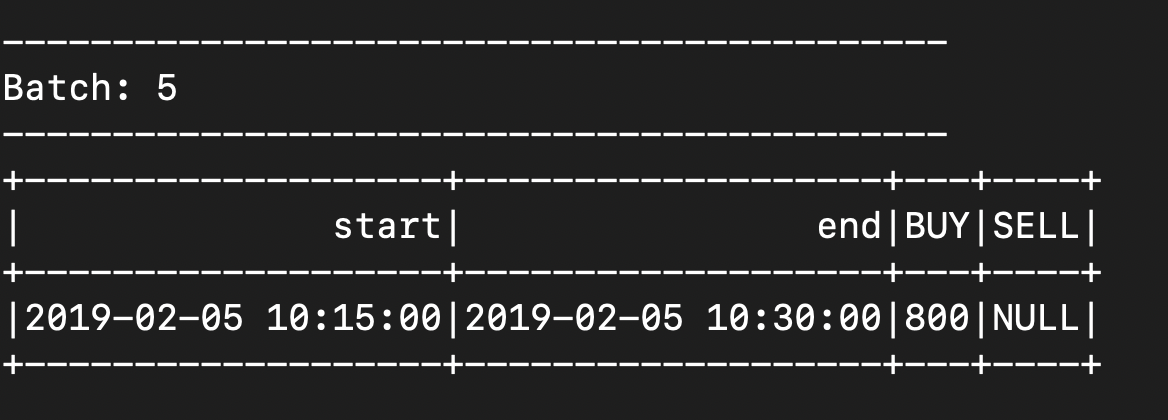
- 3rd microbatch - after it completes, max event time stays as 10.40. no windows are expired
{"CreatedTime": "2019-02-05 10:20:00", "Type": "BUY", "Amount": 800, "BrokerCode": "ABX"}![]()
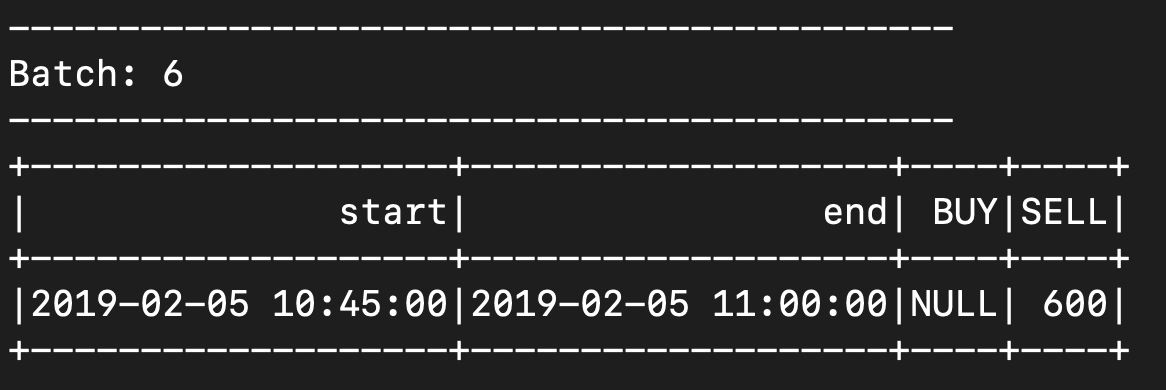
- 4th microbatch - after it completes, max event time is updated to 10.48. 10.48-30 = 10.18. so, window for 10.00 to 10.15 is ejected from state
{"CreatedTime": "2019-02-05 10:48:00", "Type": "SELL", "Amount": 600, "BrokerCode": "ABX"}![]()
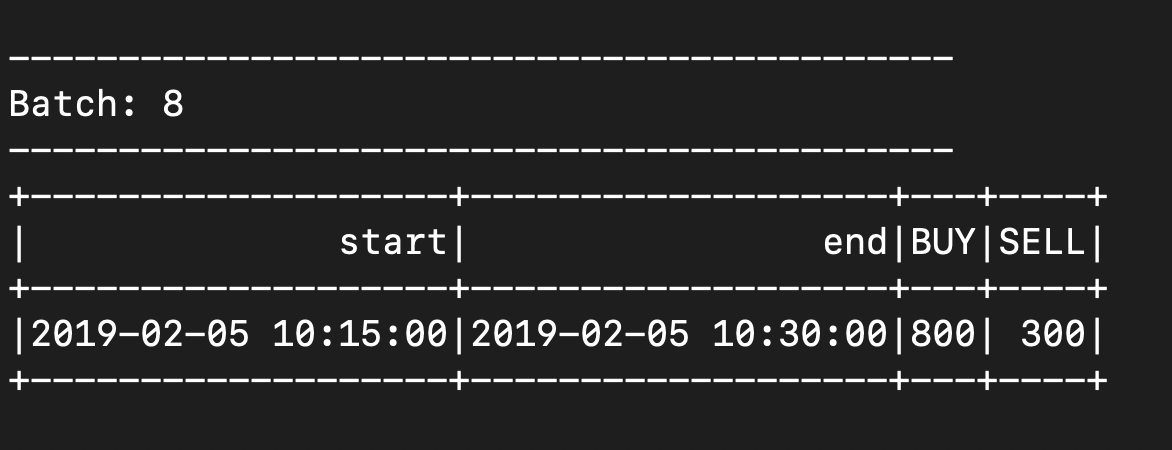
- 5th microbatch - will ignore event 10.14, since its corresponding window is 10.00-10.15, which is no longer present in the state. 10.16 is not ignored however, and it updates the window for 10.15-10.30
{"CreatedTime": "2019-02-05 10:14:00", "Type": "SELL", "Amount": 300, "BrokerCode": "ABX"} {"CreatedTime": "2019-02-05 10:16:00", "Type": "SELL", "Amount": 300, "BrokerCode": "ABX"}![]()
Watermark and Output Mode
- the example we saw above was for “update” output mode
- watermarking is ignored when we use the “complete” output mode - because spark can either show all the output, or perform the cleanup and stop showing the cleaned up windows. it cannot do both
- recall how when we used “append mode” with aggregations, we got an exception when using aggregations here
- this was because we using aggregations would involve “updating” existing groups, which is not possible when using append mode
- however, when we use watermarking, expired windows are ejected from state. we can be sure that these windows would not be updated
- therefore, in the above example, we only get the output for the 10.48 event, when it ejects the 10.00-10.15 window from the state and outputs it
- note - e.g when using “file sinks” with spark streaming, we cannot use “update” output mode, because spark does not support updating files
- however, spark does support “append” mode for file sinks
- thus, when using watermarking with file sinks, while we cannot use update mode, we can use the append mode
Sliding Window
- “window aggregations” can be of two types - “tumbling time windows” and “sliding time windows”
- “tumbling window” - non overlapping windows - 10.00-10.15, 10.15-10.30, 10.30-10.45…
- “sliding window” - overlapping windows - 10.00-10.15, 10.05-10.20, 10.10-10.25…
- the “sliding interval” is not equal to the “window interval” in sliding windows, unlike in tumbling windows
- another difference - the same event can be a part of multiple windows in sliding window unlike in tumbling windows due to the overlap, e.g. an event at 10.11 would be part of three windows in the example above
- the syntax is the same, we just have to specify the sliding interval as well now -
.groupBy(window(col("CreatedTime"), "15 minutes", "5 minutes"))
Joins
Streaming and Static Dataframe
- e.g. assume we read a streaming datasource from kafka, a static datasource from cassandra and finally write to cassandra
- note - if for e.g. sink connector for cassandra is not available, we can use the following approach -
spark.writeStream \ .foreachBatch(cassandraWriter) - the function is run for every microbatch this way, and it receives two arguments - the dataframe and the micro batch id
def cassandraWriter(df, id): pass - very important - we already know that streaming applications never stop. imagine a case where a record was inserted into the static dataframe, while the streaming query was already running joins and using this static dataframe. i saw that the changes in static dataframe get picked up automatically. this makes me believe that for every microbatch, the static dataframe is read afresh by spark
- actually, streaming to static dataframe join is a “stateless” operation - spark does not need to maintain any state for this. state is needed e.g. during grouping and aggregations, since we need to keep on updating groups as new records / microbatches arrive
- whatever we covered above was for inner joins
- outer joins are allowed only if outer part is for streaming. why? assume outer was for static. now, along with results of inner join, we have to output all records of static dataframe not in streaming dataframe. now, we will never know about all the records of streaming dataframe, because streaming dataframe never ends! therefore, outer is supported only if the outer portion is for the streaming dataframe
Two Streaming Dataframes
- unlike joins between streaming and static dataframe, joins between two streaming dataframes will involve state
- this is because for e.g. the value “a” which we are joining on can come at different points of time in different microbatches from both dataframes
- by default, the entire state for both streaming dataframes is kept in the state. assume we have an inner join, and we receive a new record for one streaming dataframe. we will see all the records from the second dataframe combined with this record
- this was possible because all of the records for both the dataframes are stored in state
- note - i saw this when using output mode as append. append works here because joins do not update any existing data. and thats why complete output mode would not be supported, because that would mean storing all of the output inside state as well, as discussed here
- however, this approach of storing both dataframes entirely in memory can lead to out of memory exceptions
- so, all we need to do is chain a
withWatermarkcall to the dataframe based on the event time column - again, we are basically making use of time bound state, to clear the state that the streaming dataframes are storing for performing the joins
- we chose to clear the state, but it was not mandatory for inner joins
- however, it is mandatory for outer joins. refer the support matrix for exact details. e.g. assume we want to perform a left outer join between two streaming dataframes -
- condition 1 - put watermark on the right dataframe. trick to remember - this is like making the right dataframe static, by expiring old records. and we saw here why outer part must be streaming
- condition 2 - “time constraints” - e.g. we are joining two streaming dataframes - one that tells when the add was displayed, and one that tracks click events. we will tell spark to only join records where the click time was within 1 hour from when the add was displayed
impressionsWithWatermark.join( clicksWithWatermark, expr(""" clickAdId = impressionAdId AND clickTime >= impressionTime AND clickTime <= impressionTime + interval 1 hour """), "leftOuter" )
- note - again, while we had to add the watermark only to the right dataframe, adding it to the left dataframe is optional
Spark Cluster on Kubernetes
- install spark -
helm install spark bitnami/spark - modify the number of workers -
helm upgrade spark bitnami/spark --set worker.replicaCount=4 - access the ui -
kubectl port-forward --namespace default svc/spark-master-svc 30080:80 - submitting the example application -
spark-submit \ --master spark://spark-master-svc:7077 \ --class org.apache.spark.examples.SparkPi \ /opt/bitnami/spark/examples/jars/spark-examples_2.12-3.5.3.jar 5 - my understanding - this approach is spark standalone cluster, i.e. pods for workers and master are there. it is not the same, or maybe as preferred as the kubernetes operator approach
Spark Kubernetes Operator
- we can use spark-submit command directly, which uses the spark native k8s scheduler
- however, a special kubernetes operator for spark is there
- google introduced the “spark operator”, which was later migrated to kubeflow
- so, we write spark applications in the form of yaml using crd (custom resource definition)
- we do not need to use spark submit now - it runs bts when we create the
SparkApplicationusing the crd - allows exposing application, driver and executor metrics to prometheus
- restart, retries, backoff etc supported
- note - apparently,
SparkScheduledApplicationis supported as well, wherein we can specify a cron etc. however, i would probably rather use airflow
Architecture
- the operator has four parts - controller, submission runner, pod monitor, mutating admission webhook
- “controller” -
- like api server of k8s i.e. both clients and the different internal components interact with it
- receives the creation, deletion etc events for “spark application”
- sends spark applications to “submission runner” with the arguments
- receives health of driver and executor pods from “pod monitor” and accordingly updates the status of the “spark application”
- “submission runner” - talks to k8s to spin up the driver pod
- after this, the executor pods are spun up by the driver pod
- “pod monitor” - watch status of the driver and executor pods, and send updates to the controller
- “mutating admission webhook” - the “controller” will add annotations, and the “mutating admission webhook” at the back of this will for e.g. perform actions like -
- mount volume(s) on the driver / executor pods
- control pod affinity etc - e.g. schedule driver on on demand instances, executors on spot instances
- we can use “sparkctl” instead of kubectl for more functionality as well
Getting Started
- adding the helm repository and installing the chart -
helm repo add spark-operator https://kubeflow.github.io/spark-operator helm repo update helm install spark-operator spark-operator/spark-operator \ --namespace=spark-operator \ --create-namespace - includes things like setting up service account called
spark-operator-sparkwith rbac so that driver can spawn executors etc - now we can run
kubectl get sparkapplications - use the value
sparkJobNamespacesto decide which namespace the spark jobs run inside. based on this value, resources like the service account mentioned above would be created - we can run the operator in high availability mode i.e. multiple replicas of the operator. there is “leader election” in play in this case, and a lock resource needs to be maintained in this case
- my understanding - this is not the same as multiple replicas, this is entirely different instances of the spark operator, so different controller, submission runner, pod monitor, etc
- we can run multiple instances of the operator itself as well. we just need to ensure that they watch different namespaces, specified using
sparkJobNamespaces
Spark Application Configurations
- a yaml definition - create using kubectl / sparkctl
- type - scala, python, etc
- deployment mode - cluster or client. we should be using cluster only, i think client is not supported yet
- the same image gets used by the driver and executor pods, since we do not have to code them separately as developers
- a very basic example -
apiVersion: sparkoperator.k8s.io/v1beta2 kind: SparkApplication metadata: name: spark-pi namespace: default spec: type: Scala mode: cluster image: spark:3.5.1 mainClass: org.apache.spark.examples.SparkPi mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.12-3.5.1.jar - we can specify a separate init container image, otherwise the same image gets used for init container as well
- spark-submit supports
--jarsand--filescommand for external dependencies and data files. we can usespec.deps.jarsandspec.deps.filesfor the same here - we can do things like download from hdfs, s3, specify maven coordinates, etc for these jars
spec: deps: jars: - local:///opt/spark-jars/gcs-connector.jar files: - gs://spark-data/data-file-1.txt - gs://spark-data/data-file-2.txt - we can also specify
.spec.deps.pyFiles, which translates to--py-filesof spark-submit - we can set either specify individual spark configuration under
spec.sparkConfin a key value format, or specifyspec.sparkConfigMap, which mounts the config map storing spark-defaults.conf, spark-env.sh, log4j.properties at /etc/spark/conf, and also setsSPARK_CONF_DIRto the same- note, my understanding - prefer using
spec.executor.javaOptionsandspec.driver.javaOptionsin the crd directly over specifyingspark.driver.extraJavaOptionsandspark.executor.extraJavaOptionshere
- note, my understanding - prefer using
- the same thing applies to
spec.hadoopConfandspec.hadoopConfigMap - use
spec.driver-- resources - memory and cpu
- labels, annotations
- environment variables - use
envorenvFromfor config maps / secrets - to set a custom pod name
- a service account with the right permissions to generate executors
- a driver specific image. it overrides the one specified inside
spec.image - mount secrets. additionally, we can specify a type, e.g. if we specify type as
GCPServiceAccount, it would set the environment variableGOOGLE_APPLICATION_CREDENTIALSfor us automatically - mount config maps
- set the affinity and toleration. my understanding of what this translates to - allows us to think about things like cost savings, by scheduling drivers on on demand instances and executors on spot instances
- set volumes for scratch space. my understanding of what this translates to - during shuffle etc, spark can store to disk. the pod storage might not be enough for this, and so we need volumes. to validate - additionally, maybe if an executor has to be restarted, the new executor can reuse this data?
spec.executoris be pretty similar. but additionally, it allows specifying number of executor instances viaspec.executor.instances, which defaults to 1- optionally, dynamic allocation is supported as well, which can be configured using
dynamicAllocation - status of “spark application” =
- “failed” if status of driver pod has status failed
- “completed” if status of driver pod has status completed
- “failed_submission” if somewhere around “submission runner” there is a failure
- restart policies - never, always or on_failure. also notice how we can configure backoff etc for the restarts
restartPolicy: type: OnFailure onFailureRetries: 3 onFailureRetryInterval: 10 onSubmissionFailureRetries: 5 onSubmissionFailureRetryInterval: 20