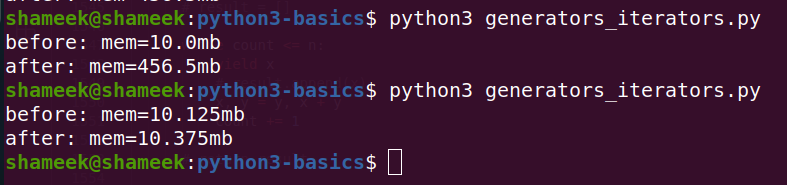
- lists - ordered collection of items
- it is a data structure - a combination of data types
- we can add / remove items, reorder items, etc in a list
- a list can contain different data types
- e.g. of using len -
demo_list = [1, True, 4.5, "bca"]
print(len(demo_list)) # 4
- iterable objects like a range can be converted to a list as well -
rng = range(1, 4)
print(rng) # range(1, 4)
lst = list(rng)
print(lst) # [1, 2, 3]
- accessing data - remember that negative indexing is supported in python as well. on exceeding the bounds, we get an index error
friends = ["Ashley", "Matt", "Michael"]
print(friends[1]) # Matt
print(friends[3]) # IndexError: list index out of range
print(friends[-1]) # Michael
print(friends[-4]) # IndexError: list index out of range
- use in too check if a value is present in a list
print("Ashley" in friends) # True
print("Violet" in friends) # False
- iterating over lists -
friends = ["Ashley", "Matt", "Michael"]
for friend in friends:
print(friend)
- use append for adding a single element / extend for adding multiple elements
nums = [1, 2, 3]
nums.append(4)
print(nums) # [1, 2, 3, 4]
nums.extend([5, 6, 7])
print(nums) # [1, 2, 3, 4, 5, 6, 7]
- use insert to add an element at a specific position
nums = [1, 2, 3]
nums.insert(2, 4)
print(nums) # [1, 2, 4, 3]
- clear - delete all items from the list
nums = [1, 2, 3]
nums.clear()
print(nums) # []
- pop - remove the last element / remove element from the specified index
nums = [1, 2, 3, 4]
removed_element = nums.pop()
print(f"removed = {removed_element}, nums = {nums}") # removed = 4, nums = [1, 2, 3]
removed_element = nums.pop(1)
print(f"removed = {removed_element}, nums = {nums}") # removed = 2, nums = [1, 3]
- remove - specify the element to delete, and its first occurrence is removed
nums = [1, 2, 3, 2, 1]
nums.remove(1)
print(nums) # [2, 3, 2, 1]
- index - return the (first?) index where the specified value is present
- we can specify the range of indices - start and end between which it should look for
- throws an error if not present
numbers = [1, 2, 4, 3, 5, 4, 5, 2, 1]
print(numbers.index(4)) # 2
print(numbers.index(4, 3, 6)) # 5
print(numbers.index(21)) # ValueError: 21 is not in list
- count - number of times the element occurs in the list
numbers = [1, 2, 4, 3, 5, 4, 5, 2, 1]
print(numbers.count(4)) # 2
print(numbers.count(21)) # 0
- reverse to reverse the list - in place
- sort - sort the elements, again in place
numbers = [2, 1, 4, 3]
numbers.sort()
print(numbers) # [1, 2, 3, 4]
- join - concatenate the elements of the string using the specified separator
words = ["hello", "to", "one", "and", "all", "present"]
sentence = ' '.join(words)
print(sentence) # hello to one and all present
- slicing (works on strings as well) - allows us to make copies. we provide three optional pieces of information - start, stop and step
numbers = [1, 2, 3, 4, 5, 6]
print(numbers[:]) # [1, 2, 3, 4, 5, 6]
print(numbers[1:]) # [2, 3, 4, 5, 6]
print(numbers[:2]) # [1, 2]
print(numbers[1:5]) # [2, 3, 4, 5]
print(numbers[1:5:2]) # [2, 4]
- we can use negative steps to go backwards as well when slicing. a common use case - reverse the list (not in place)
nums = [1, 2, 3, 4]
print(nums[::-1]) # [4, 3, 2, 1]
- shorthand in python for swapping elements of a list -
numbers = [1, 2, 3]
numbers[0], numbers[2] = numbers[2], numbers[0]
print(numbers) # [3, 2, 1]
- destructuring lists -
a, b, c = [1, 2, 3]
print(f"{a} {b} {c}")
- also applicable to tuples etc
- shorthand of doing it via for loop manually. basic syntax -
nums = [1, 2, 3]
nums_mul_10 = [x * 10 for x in nums]
print(nums_mul_10) # [10, 20, 30]
- list comprehension with conditionals -
nums = list(range(1, 10))
odds = [num for num in nums if num % 2 != 0]
print(odds) # [1, 3, 5, 7, 9]
- the first condition below determines how to map the element. think of it like a ternary expression. the second condition acts like a filter, like the one we saw in the example above
nums = list(range(1, 10))
mapped = ["3x" if num % 3 == 0 else str(num) for num in nums if num % 2 == 1]
print(mapped) # ['1', '3x', '5', '7', '3x']
- list comprehension with strings -
all_characters = "the quick big brown fox jumps over the lazy dog"
vowels = [character for character in all_characters if character in "aeiou"]
print(vowels) # ['e', 'u', 'i', 'i', 'o', 'o', 'u', 'o', 'e', 'e', 'a', 'o']
- nested list comprehensions - e.g. we would like to generate a combination of all suits and values for generating cards -
possible_suits = ("Hearts", "Diamonds", "Clubs", "Spades")
possible_values = ("A", "2", "3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K")
cards = [f"{value} of {suit}" for suit in possible_suits for value in possible_values]
print(cards)
# ['A of Hearts',
# '2 of Hearts',
# '3 of Hearts',
# ...
# 'J of Spades',
# 'Q of Spades',
# 'K of Spades']
- note - because we did not surround the first list inside square braces, we got a flattened list automatically. for obtaining a list of lists, we could use the following instead -
cards = [[f"{value} of {suit}" for suit in possible_suits] for value in possible_values]
# [['A of Hearts', 'A of Diamonds', 'A of Clubs', 'A of Spades'],
# ...
# ['K of Hearts', 'K of Diamonds', 'K of Clubs', 'K of Spades']]
- helps describing data with detail - e.g. item in a shopping cart has attributes like product, quantity
- it uses key value pairs - in lists, keys are the indices
cat = {
"name": "bubbles",
"age": 3.5,
"color": "blue"
}
print(type(cat)) # <class 'dict'>
print(cat) # {'name': 'bubbles', 'age': 3.5, 'color': 'blue'}
- we can pass an iterable of iterables of length 2 to dict as well. it will create a dictionary for us automatically, by using the first element as the key and the second element as the value -
print(dict([("shameek", 25), ("colt", "45")])) # {'shameek': 25, 'colt': '45'}
- so, if we had a list of keys and another list of values, we can construct a dictionary out of them as follows -
dict(zip(keys, values)) - accessing data - similar to how we do it in lists. notice the
KeyError if the key is not presentcat = {"name": "bubbles", "age": 3.5, "color": "blue"}
print(cat["name"]) # bubbles
print(cat["not_present"]) # KeyError: 'not_present'
- accessing all elements of dictionary -
cat = {"name": "bubbles", "age": 3.5, "color": "blue"}
print(cat.values()) # dict_values(['bubbles', 3.5, 'blue'])
print(cat.keys()) # dict_keys(['name', 'age', 'color'])
print(cat.items()) # dict_items([('name', 'bubbles'), ('age', 3.5), ('color', 'blue')])
- now, we can use for loops for the iterables we saw above -
cat = {"name": "bubbles", "age": 3.5, "color": "blue"}
for key, value in cat.items():
print(f'{key} => {value}')
# name => bubbles
# age => 3.5
# color => blue
- check the presence of a key in the dictionary -
cat = {"name": "bubbles", "age": 3.5, "color": "blue"}
print("name" in cat) # True
print("phone" in cat) # False
- check if a value is present in a dictionary - since values returns an iterable data structure, we can use in again, like we used in lists
cat = {"name": "bubbles", "age": 3.5, "color": "blue"}
print("blue" in cat.values()) # True
print("purple" in cat.values()) # False
- clear - to clear a dictionary
- copy - to clone a dictionary. notice the difference in outputs between outputs of
is vs ==, discussed herecat = {"name": "bubbles", "age": 3.5, "color": "blue"}
copy_cat = cat.copy()
print(cat is copy_cat) # False
print(cat == copy_cat) # True
- get - return value if key is present, else return None
user = {"name": "shameek", "age": 25}
print(user.get("name")) # shameek
print(user.get("phone")) # None
- now, get can also accept a default value -
print(user.get("phone", "+916290885679")) # +916290885679
- pop - remove the key value pair from the dictionary for the key passed. it also returns the value removed
user = {"name": "shameek", "age": 25}
print(user.pop("name")) # shameek
print(user) # {'age': 25}
print(user.pop("email")) # KeyError: 'email'
- we can add / update values like this -
user = {"name": "shameek"}
user["age"] = 25
user["name"] = "shameek agarwal"
print(user) # {'name': 'shameek agarwal', 'age': 25}
- update - modify value if the key is already present, else add the key value pair to the dictionary
user = {"first_name": "shameek", "age": 2}
user.update({"last_name": "agarwal", "age": 25})
print(user) # {'first_name': 'shameek', 'age': 25, 'last_name': 'agarwal'}
- dictionary comprehension example - look how we obtain both key and value, use
.items and use curly instead of square braces. rest of the things stay the samenumbers = {'one': 1, 'two': 2, 'three': 3}
powers = {f'{key}^{value}': value ** value for key, value in numbers.items()}
print(powers) # {'one^1': 1, 'two^2': 4, 'three^3': 27}
- map values in list 1 to values in another list -
list1 = ["CA", "NJ", "RI"]
list2 = ["California", "New Jersey", "Rhode Island"]
answer = {list1[i]: list2[i] for i in range(0,3)}
*args - allows us to pass variable number of positional argumentsdef sum_except_first(num1, *args):
print(f"skipping {num1}")
return sum(args)
print(sum_except_first(1)) # 0
print(sum_except_first(1, 2, 3, 4)) # 9
**kwargs - allows us to pass variable number of keyword argumentsdef fav_colors(**kwargs):
print(kwargs)
fav_colors(shameek="red", colt="purple") # {'shameek': 'red', 'colt': 'purple'}
- e.g. use case - combine a word with its prefix and suffix if provided -
# Define combine_words below:
def combine_words(word, **kwargs):
return kwargs.get("prefix", "") + word + kwargs.get("suffix", "")
print(combine_words("child")) # 'child'
print(combine_words("child", prefix="man")) # 'manchild'
print(combine_words("child", suffix="ish")) # 'childish'
print(combine_words("work", suffix="er")) # 'worker'
print(combine_words("work", prefix="home")) # 'homework'
- note - args and kwargs are just conventions inside python, we can name them differently as well
- the order of parameters should be as follows -
- normal parameters
*args- default parameters
**kwargs
- unpacking args - we can unpack the arguments in a list while passing it to a function as follows -
def unpack_add(a, b, c):
return a + b + c
numbers = [1, 2, 3]
print(unpack_add(*numbers))
- now, we can extend this functionality to
*args as well. when we pass a list without unpacking, args ends up being a tuple, with the first argument as the list itself. however, we get the desired functionality when we unpack the list while passing it to the functiondef adder(*args):
return sum(args)
numbers = [1, 2, 3, 4]
print(adder(numbers)) # TypeError: unsupported operand type(s) for +: 'int' and 'list'
print(adder(*numbers)) # 10
- similarly, we can unpack dictionaries as well -
def get_display_name(first_name, last_name):
return f"{first_name} {last_name}"
user = {"first_name": "shameek", "last_name": "agarwal"}
print(get_display_name(**user)) # shameek agarwal
- notice how though unpacking and args / kwargs can be combined, they are separate things
- combining unpacking and kwargs -
def get_display_name(**kwargs):
return f"{kwargs.get('first_name')} {kwargs.get('last_name')}"
user = {"first_name": "shameek", "last_name": "agarwal"}
print(get_display_name(**user)) # shameek agarwal
- lambdas - functions that are short, one line expressions
square = lambda num: num ** 2
add = lambda a, b: a + b
print(square(3)) # 9
print(add(4, 9)) # 13
- lambdas are useful when we for e.g. want to pass small functions as a callback to other functions
- map - accepts a function and an iterable. it then runs the function for each value in the iterable
- my understanding - it returns a map object which while iterable, has limited functionality. that is why we again convert it to a list. this is a common theme in all functions we see now - zip returns zip object, map returns map object and so on. we convert these special objects to a list manually
numbers = [1, 2, 3, 4]
doubled = list(map(lambda x: x * 2, numbers))
print(doubled)
- filter - filter out elements of the iterable that do not satisfy the condition
- it is possible to do this map and filter using comprehensions as well, which is a bit more readable. it depends on use case
- all - return true if all elements of the iterable are truthy. if iterable is empty, return true
- any - return true if any element of the iterable is truthy. if iterable is empty, return false
numbers = [1, 2, 3, 4]
print([num > 0 for num in numbers]) # [True, True, True, True]
print(all([num > 0 for num in numbers])) # True
print(all([num > 1 for num in numbers])) # False
print(any([num > 0 for num in numbers])) # True
print(any([num > 4 for num in numbers])) # False
- sorted - accept an iterable and returns a new iterable with the sorted elements. notice the difference between sorted and the sort we saw in lists - sorted is not in place, sort is
numbers = [1, 2, 3, 4]
print(sorted(numbers)) # [1, 2, 3, 4]
print(f'stays the same: {numbers}') # stays the same: [1, 2, 3, 4]
print(sorted(numbers, reverse=True)) # [4, 3, 2, 1]
- specify custom sorting logic -
users = [
{"username": "samuel", "tweets": ["I love cake", "I love pie", "hello world!"]},
{"username": "katie", "tweets": ["I love my cat"]},
{"username": "jeff", "tweets": [], "color": "purple"},
{"username": "bob123", "tweets": [], "num": 10, "color": "teal"},
{"username": "doggo_luvr", "tweets": ["dogs are the best", "I'm hungry"]},
{"username": "guitar_gal", "tweets": []}
]
print(sorted(users, key=lambda user: user["username"]))
# [
# {'username': 'bob123', 'tweets': [], 'num': 10, 'color': 'teal'},
# {'username': 'doggo_luvr', 'tweets': ['dogs are the best', "I'm hungry"]},
# {'username': 'guitar_gal', 'tweets': []},
# {'username': 'jeff', 'tweets': [], 'color': 'purple'},
# {'username': 'katie', 'tweets': ['I love my cat']},
# {'username': 'samuel', 'tweets': ['I love cake', 'I love pie', 'hello world!']}
# ]
- max - find the max in iterable etc. i think works for *args as well based on the first example
print(max(3, 1, 4, 2)) # 4
print(max([3, 1, 4, 2])) # 4
- custom logic for max -
names = ['arya', 'samson', 'tim', 'dory', 'oleander']
print(max(names, key=lambda name: len(name))) # oleander
- reversed - again, unlike the reverse we saw in lists, this does not do it in place
numbers = [1, 2, 3, 4]
print(list(reversed(numbers))) # [4, 3, 2, 1]
for i in reversed(range(5)):
print(i)
# 4 3 2 1 0
- len - length of iterable. e.g. calling it on a dictionary will return the number of keys it has -
print(len({"name": "shameek", "age": 25, "profession": "IT"})) # 3
print(len([1, 2, 3, 4, 5])) # 5
- abs, round, sum - all self explanatory. notice how we can provide sum with an initial value as well
print(abs(-4)) # 4
print(abs(4)) # 4
print(sum([1, 2, 3, 4], 5)) # 15
print(sum((2.0, 4.5))) # 6.5
print(round(5.4123, 2)) # 5.41
print(round(1.2, 3)) # 1.2
- zip - makes an iterator that aggregates elements from each of the iterators i.e. ith tuple contains the ith element from each of the iterator. the iterator stops when the shortest iterator is exhausted
numbers = [1, 2, 3, 4, 5]
squares = [1, 4, 9]
print(zip(numbers, squares)) # <zip object at 0x797350050f00>
print(list(zip(numbers, squares))) # [(1, 1), (2, 4), (3, 9)]
- a slightly complex example of combining zip with unpacking. we unpacks the list, and it essentially means we are passing several tuples to zip. so, first element of all tuples are combined to form the first element, and second element of all tuples are combined to form the second element
tuples = [(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]
print(list(zip(*tuples))) # [(1, 3, 5, 7, 9), (2, 4, 6, 8, 10)]
- e.g. we have a list of students, and their attempts in two exams. we want a dictionary keyed by student names, and their final score which is the best of the two attempts -
# question
attempt_1 = [80, 91, 78]
attempt_2 = [98, 89, 53]
students = ["dan", "ang", "kate"]
# solution
final_scores = map(max, zip(attempt_1, attempt_2))
final_scores_by_student = dict(zip(students, final_scores))
print(final_scores_by_student) # {'dan': 98, 'ang': 91, 'kate': 78}
- classes - attempts to model anything in the real world that is tangible (or non-tangible) via programming
- classes are like blueprints for objects. objects are instances of a class
- when we were creating lists or even int, we were basically creating objects of int / list classes
- goal - make a hierarchy of the classes after identifying the different entities
- note - visibility modifiers like private etc are not supported by python - so, we prefix variables and methods not meant to be touched from outside the class with underscores instead
- defining a class. note -
pass acts like a placeholder, it helps us stay syntactically correct, and the idea is that we revisit it laterclass User:
pass
- creating objects for this class -
user1 = User()
print(user1) # <__main__.User object at 0x77e693863040>
- self - refers to the instance. technically, we can name it something else, but self is pretty much the standard everywhere
- self must be the first parameter to all the methods of a class
- init - called when we instantiate the class
class User:
def __init__(self, name):
self.name = name
user1 = User("shameek", 25)
print(user1.name) # shameek
- methods starting and ending with
__ are typically used by built in methods of python, and we typically override them - so, for custom private methods / variables, we can prefix with a single
_ - name mangling - when we prefix attributes with a
__, python internally prepends it with the class name. helps distinguish in case they are overridden by child class. this has been discussed laterclass User:
def __init__(self, name, age):
self.name = name
self.age = age
self._secret = "hint (convention): do not access me directly"
self.__profession = "unemployed"
user1 = User("shameek", 25)
print(user1._secret) # hint (convention): do not access me directly
print(user1._User__profession) # unemployed
print(user1.__profession) # AttributeError: 'User' object has no attribute '__profession'. Did you mean: '_User__profession'?
- adding instance methods -
# ....
def greeting(self):
return f"hi {self.name}!"
print(user1.greeting()) # hi shameek!
- till now, we have seen instance attributes and instance methods, now we discuss class attributes and class methods
- class attributes / methods exist directly on the class and are shared across instances
- defining class attributes -
class User:
active_users = 0
# ...
- accessing class attributes from instance methods or outside -
# ...
def __init__(self, name, age):
self.name = name
self.age = age
User.active_users += 1
print(f"active users = {User.active_users}") # active users = 0
user1 = User("shameek", 25)
user2 = User("colt", 50)
print(f"active users = {User.active_users}") # active users = 2
- all objects in python get their unique id which python assigns. we can check that both users point to the same active_users int object as follows. note - this also makes me think that python probably doesn’t really differentiate between primitive and non primitive types
print(id(user1.active_users)) # 134256650092816
print(id(user2.active_users)) # 134256650092816
- note - above shows that we can access class attributes via the instance as well. even self inside the class can be used to access the class attributes. accessing via the class however, improves readability
- class methods - decorate with
@classmethod. the first argument it receives is cls and not self. look at the print statements below to understand the differenceclass User:
active_users = 0
def __init__(self, name, age):
print(self)
self.name = name
self.age = age
User.active_users += 1
@classmethod
def get_active_users(cls):
print(cls)
return cls.active_users
user1 = User("shameek", 25)
user2 = User("colt", 50)
print(User.get_active_users())
# <__main__.User object at 0x718a83b63eb0>
# <__main__.User object at 0x718a83b63e50>
# <class '__main__.User'>
# 2
- another example, like a factory method -
# ...
@classmethod
def create(cls, csv_row):
name, age = csv_row.split(",")
return cls(name, age)
user3 = User.create("shameek,25")
print(user3.name) # shameek
print(user3.age) # 25
- repr is one of the several ways to provide a string representation -
# ...
def __repr__(self):
return f"{self.name} aged {self.age}"
print(user3) # shameek aged 25
string_repr = str(user3)
print(string_repr) # shameek aged 25
- properties - helps use getter and setter methods underneath, while clients interact with them like normal attributes. advantage - when our getter / setter logic has some complexity underneath and simple assignment / accessing is not enough
class Human:
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
@property
def full_name(self):
return f"{self.first_name} {self.last_name}"
@full_name.setter
def full_name(self, full_name):
self.first_name, self.last_name = full_name.split(" ")
shameek = Human("", "")
print(f"{shameek.first_name}, {shameek.last_name}, {shameek.full_name}") # , ,
shameek.full_name = "shameek agarwal"
print(f"{shameek.first_name}, {shameek.last_name}, {shameek.full_name}") # shameek, agarwal, shameek agarwal
- there is a handy dict attribute we can access to look at the instance attributes of the class -
class Human:
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
human = Human("shameek", "agarwal")
print(human.__dict__) # {'first_name': 'shameek', 'last_name': 'agarwal'}
- notice how instance variables / methods of superclass are accessible from child class -
class Animal:
def __init__(self):
self.is_animal = True
def make_sound(self, sound):
print(f"i say {sound}")
class Cat(Animal):
pass
cat = Cat()
print(cat.is_animal) # True
cat.make_sound("meow") # i say meow
- is instance returns true for the parent class as well
print(isinstance(cat, Cat)) # True
print(isinstance(cat, Animal)) # True
- calling superclass init from subclass
class Animal:
def __init__(self, species, name):
self.species = species
self.name = name
def __repr__(self):
return f"{self.name} is a {self.species}"
class Cat(Animal):
def __init__(self, name, breed, favourite_toy):
super().__init__("cat", name)
self.breed = breed
self.favourite_toy = favourite_toy
blue = Cat("blue", "scottish fold", "string")
print(blue) # blue is a cat
- multiple inheritance explained with output -
class Aquatic:
def __init__(self, name):
print("init of aquatic")
self.name = name
def swim(self):
print(f"{self.name} is swimming")
def greet(self):
print(f"{self.name}, king of the ocean")
class Ambulatory:
def __init__(self, name):
print("init of ambulatory")
self.name = name
def walk(self):
print(f"{self.name} is walking")
def greet(self):
print(f"{self.name}, king of the land")
class Penguin(Aquatic, Ambulatory):
def __init__(self):
print("init of penguin")
super().__init__("pingu")
pingu = Penguin() # init of penguin, init of aquatic
pingu.swim() # pingu is swimming
pingu.walk() # pingu is walking
pingu.greet() # pingu, king of the ocean
- instance methods from both are inherited - we are able to call both walk and swim
- in cases of instance methods like greet defined in both, aquatic is taking preference
- aquatic’s init is being called when we use super in subclass
- mro or method resolution order - the order in which python is going to look for methods
- the underlying algorithm is complex, but we can inspect it using the mro method on classes
print(Penguin.__mro__)
# (<class '__main__.Penguin'>, <class '__main__.Aquatic'>, <class '__main__.Ambulatory'>, <class 'object'>)
- so maybe this decides what order to traverse superclasses in when super is used / what superclass will be ultimately used when an instance method is referenced
- as a resolve, e.g. if we want to call init for both classes, instead of using super, we can reference the class directly
# ...
class Penguin(Aquatic, Ambulatory):
def __init__(self):
print("init of penguin")
# super().__init__("pingu")
Aquatic.__init__(self, "pingu")
Ambulatory.__init__(self, "pingu")
# ...
pingu = Penguin() # init of penguin, init of aquatic, init of ambulatory
- now, if we understand mro further - if the init in our superclass is enough - we can skip the init in the subclass altogether, because due to mro, the superclass init will be automatically called by python if its subclass does not have an init
- we use file io in combination with the csv module to interact with csvs
- if we use the reader, each row is represented as a list of strings. first row is included as well. the trick used here is to manually call next once on the iterator
with open("fighters.csv") as file:
fighters_csv = reader(file)
header = next(fighters_csv)
for row in fighters_csv:
print(row)
# ['Ryu', 'Japan', '175']
# ['Ken', 'USA', '175']
# ['Chun-Li', 'China', '165']
# ['Guile', 'USA', '182']
- if we use dict reader, each row is represented as a dictionary. keys are constructed using the first row
with open("fighters.csv") as file:
fighters_csv = DictReader(file)
for row in fighters_csv:
print(row)
# {'Name': 'Ryu', 'Country': 'Japan', 'Height (in cm)': '175'}
# {'Name': 'Ken', 'Country': 'USA', 'Height (in cm)': '175'}
# {'Name': 'Chun-Li', 'Country': 'China', 'Height (in cm)': '165'}
# {'Name': 'Guile', 'Country': 'USA', 'Height (in cm)': '182'}
- writing to csv files - since i wanted to just add a row and not overwrite the row entirely, i opened it in append mode. opening using write mode would have overwritten the file entirely with just the one row that i specified -
with open("fighters.csv", "a") as file:
fighters_csv = writer(file)
fighters_csv.writerow(["Shameek", "India", "165"])
- writing using dict writer -
with open("people.csv", "w") as file:
fieldnames = ["name", "age"]
fighters_csv = DictWriter(file, fieldnames=fieldnames)
fighters_csv.writeheader()
fighters_csv.writerow({"name": "shameek", "age": 25})
fighters_csv.writerow({"name": "colt", "age": 50})
- assume csv has two columns - first and last name. return the row number of the row that matches the given values. note how we use the enumerate function
import csv
def find_user(first_name, last_name):
with open("users.csv") as file:
csv_reader = csv.reader(file)
header = next(csv_reader)
for index, row in enumerate(csv_reader):
if row[0] == first_name and row[1] == last_name:
return index + 1
return 'Not Here not found.'
- note, my understanding - we should iterate one by one for efficiency since it is an iterator, instead of converting the iterator to a list
- helps reduce bugs - e.g. when changes are made to existing code that results in unintended effects. our tests can help catch these bugs early
- tdd or test driven development - write tests first, and write code to have these tests pass
- we can use assert to make assertions - it returns None if the expression is truthy, raises an AssertionError otherwise. we can also specify the error message to use inside the assertion error
assert 1 == 1
assert 1 == 2
assert 1 == 2, "validation failed"
- problem with assert - if we run it in optimized mode (
python3 -O test_example.py), all the assert statements are ignored, and the code continues to execute normallydef say_hi(name):
assert name == "Colt", "I only say hi to Colt!"
return f"Hi, {name}!"
print(say_hi("Charlie")) # Hi, Charlie!
- doctests - also improves readability of modules exposed to clients -
def add(a, b):
"""
>>> add(2,3)
6
>>> add(2,"shameek")
Traceback (most recent call last):
...
TypeError: unsupported operand type(s) for +: 'int' and 'str'
"""
return a + b
- to run doctests, use the following command -
python3 -m doctest -v test_example.py. it will show that first test will fail, since expected is 6 but actual is 5 - disadvantage - very finicky - even a simple whitespace can fail a perfect valid test
- unit testing - test small standalone components of classes, instead of testing interaction between different components / entire applications in one go
- assume we have the below file -
def eat(food, is_healthy):
reason = "it is good for me" if is_healthy else "you only live once"
return f"i am eating {food} because {reason}"
- we create a new test file, where we import the different functionalities and test it as follows
from test_example import eat
import unittest
class ActivitiesTest(unittest.TestCase):
def test_eat_healthy(self):
self.assertEqual(eat("broccoli", True), "i am eating broccoli because it is good for me")
def test_eat_unhealthy(self):
self.assertEqual(eat("pizza", False), "i am eating pizza because you only live once")
if __name__ == "__main__":
unittest.main()
- note - i think unittest looks for methods with prefix test
- we run the file containing tests like we would normally run a python file. if we add the verbose flag, the name of the tests being executed are also displayed
python3 test_example_tests.py -v
- we also have other variations of assert like true / false, in / not in, raises (for asserting on type of error thrown) etc. e.g. below, we deal all the cards first, and then expect a value error to be thrown if we try dealing a card
# ...
def test__given_full_deck__when_5_cards_are_dealt__then_5_cards_are_returned(self):
self.deck.deal_hand(self.deck.count())
with self.assertRaisesRegex(ValueError, 'All cards have been dealt'):
self.deck.deal_card()
- hooks - run code before or after tests - creating database connections, adding fake data, etc. we need to override methods for this -
# ...
def setUp(self):
self.deck = Deck()
def test__given_deck__when_count__then_52_is_returned(self):
self.assertEqual(self.deck.count(), 52)
def tearDown(self):
pass
- programmatically download web pages, extract it and then use that data
- used when data from servers is not in the form of json
- as a best practice, we should refer the robots.txt of websites to see what paths they want to allow vs disallow scraping. e.g. refer this before scraping imdb. however, this is just a best practice, and nothing is stopping us from scraping publicly available websites
- the library used is beautiful soup -
python -m pip install bs4 - we read from an html file and interact with the beautiful soup object
from bs4 import BeautifulSoup
with open("mocked.html") as html_file:
html_content = html_file.read()
soup = BeautifulSoup(html_content, "html.parser")
print(soup.find("div")) # <div data-example="yes">bye</div>
print(type(soup.find("div"))) # <class 'bs4.element.Tag'>
- notice that while it prints the exact div when we use the print statement, it is not stored as a string, but a beautiful soup tag underneath
- i think using
find returns the first match, while using find_all returns all matches. here, we see matching using id, class and a custom attributeprint(soup.find_all(class_="special")) # [<li class="special">This list item is special.</li>]
print(soup.find_all(id="first")) # [<div id="first"></div>]
print(soup.find_all(attrs={"data-example": "yes"})) # [<h3 data-example="yes">hi</h3>]
- we can use css selectors as well. my understanding -
select works like find_all, select_one works like findprint(soup.select(".special")) # [<li class="special">This list item is special.</li>]
print(soup.select("#first")) # [<div id="first"></div>]
print(soup.select("[data-example='yes']")) # [<h3 data-example="yes">hi</h3>]
- understanding selectors more - to check if an attribute is “present”, use one of the below -
print(soup.find_all(attrs={"data-example": True})) # [<h3 data-example="yes">hi</h3>]
print(soup.select("[data-example]")) # [<h3 data-example="yes">hi</h3>]
- getting the inner text of an element -
print(soup.select_one("#first").get_text())
- accessing attributes like class, id, etc -
attrs, which is a dict, has access to all of themprint(soup.select_one("#first").attrs["id"]) # first
print(soup.select_one("[data-example]").attrs) # {'data-example': 'yes'}
- contents - shows the contents of a tag. if we see carefully, it also considers new line as children
print(soup.body.contents)
# ['\n', <div id="first"></div>, '\n', <ol></ol>, '\n', <div data-example="yes">bye</div>, '\n']
- we might need to navigate to siblings. remember the new lines we saw in the previous point, it is reflected in the example below
print(soup.select_one("#first").next_sibling) # <<empty line>>
print(soup.select_one("#first").next_sibling.next_sibling) # <ol>...</ol>
- this is why, the find variants might be better, since they ignore the new line characters. notice how we did not have to chain the next sibling call twice this time around, since find next sibling is sufficient
print(soup.select_one("#first").find_next_sibling()) # <ol>...</ol>
- find next sibling using a specific selector -
print(soup.select_one("#first").find_next_sibling(attrs={"data-example": True})) # <div data-example="yes">bye</div>
- till now, we were navigating to next sibling(s). similarly, we can do for previous sibling(s), parent, etc